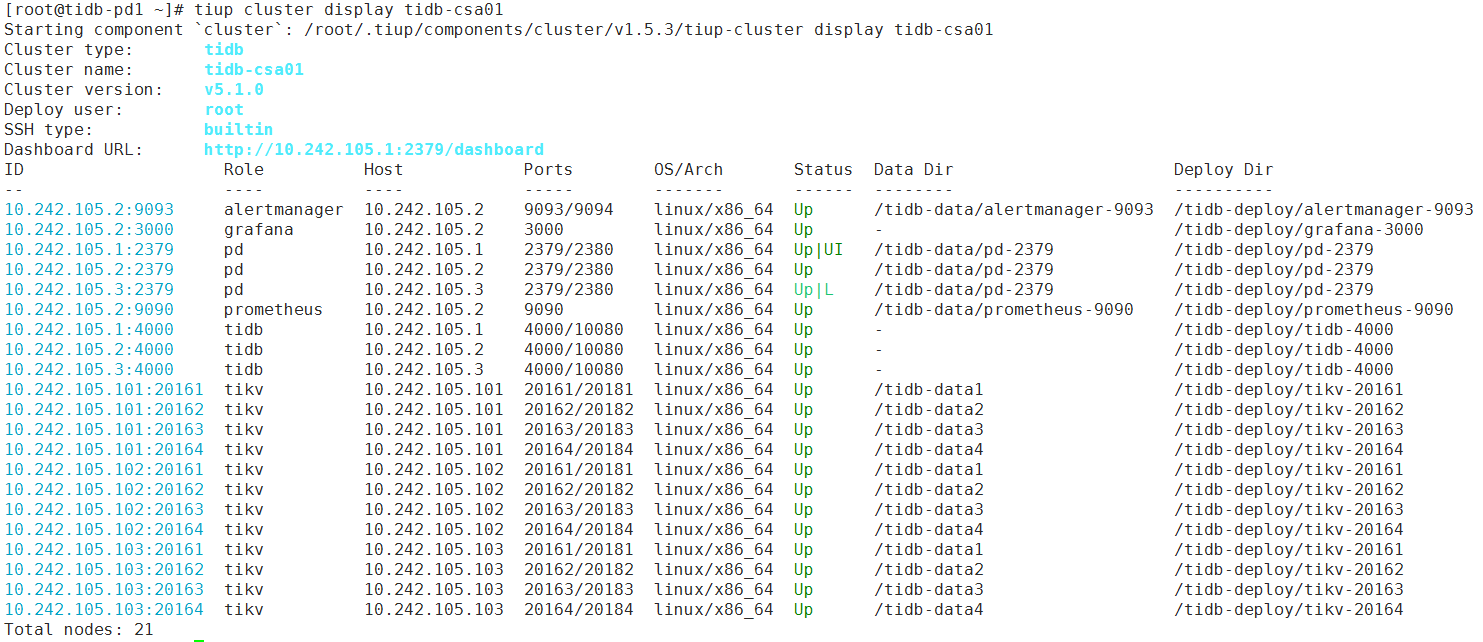
【 TiDB 使用环境】
测试TIDB
目前有三台Dell 730xd配置如下:
40C-128G-12个ssd
400G_ssd x2 打算组raid1 装系统
800G_ssd x10
三台 Dell 720 配置如下:
32C-64G-2个sas
500G_sas x2 打算raid1 装系统
问题如下:
①:tidb pd tikv 所在的物理服务器系统盘,需要ssd吗?还是sas_raid1即可。
②:r730xd 打算做tikv,10个 800G_ssd 我应该怎么部署分配。
官放的配置 tikv 好像就是一个挂载点,那我是需要10个ssd 做个raid0 挂载到挂载点上吗?
③:pd tidb 监控相关我都部署到r720上没问题吧,监控需要系统盘是ssd吧。
2 个赞
针对第二点:服务器 10 800G_ssd 组个raid0,挂载到yaml写的data_dir吗?还是每个ssd对应一个挂载点,分配10个tikv,如果这样的话 yaml文件怎么写。
2 个赞
根据你这个意思 就是我得三台 r730xd,每台10个800G_ssd 做个raid0 然后挂在给/data/tidb_data/data,那我这个目录的容量大约在7T左右。我看官方的建议是单个tikv ssd容量 不要超过1.5TB。
所以我才有疑问,我单台物理机 ssd情况较多的 情况下,官方是怎么建议部署的。是一台物理机上面部署多个tikv吗?
如果一台物理机部署多个tikv,yaml部署配置文件 我怎么配置呢。一台宿主主机上的tikv实例 内存和cpu资源怎么分配,最少多少呢。如果要限制 怎么在yaml部署配置文件里面体现呢。
2 个赞
感谢你的耐心解答!
一台物理机 三个tikv实例,每个tikv实例使用用3个800G_ssd组成raid0,那我三个tikv对应9个ssd,三个tidb_data1,2,3 挂载点,是这么建议部署的吧。
一台物理机上三个tikv实例,肯定会有资源争抢,怎么给每个tikv实例,分配CPU 内存,或者说怎么在yaml部署配置文件里面体现出,官方文档我没看出怎么配置。
1 个赞
spc_monkey
(carry@pingcap.com)
8
谢谢!原来是有的,那我就可以根据建议配置部署测试了。
我看可以根据host划分故障域啊,那是不是可以根据rack机柜 room机房划分故障域。跟ceph的crush map有点像。
大佬多问个问题,rack故障域或者room故障域 有yaml配置文件可参考吗?
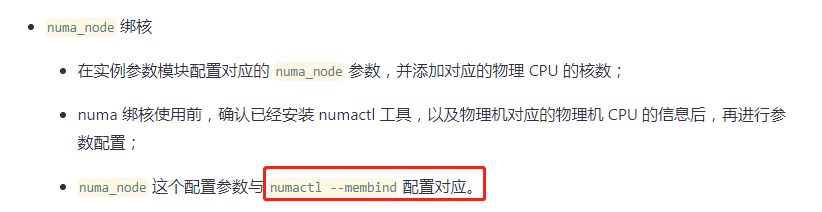
numa_node 这个配置参数与
numactl --membind 配置对应
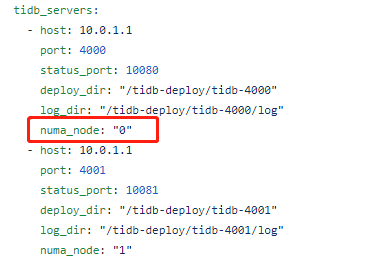
这个配置是说 我在部署yaml配置文件里面写了 numa_node:0 ,cpu跟内存都从node 0下面吗?
numactl --cpunodebind={{.NumaNode}} --membind={{.NumaNode}} 看了下是这么用的。
我去 tiup cluster destroy tidb-csa01 显示了这个报错。
这应该是一个bug,因为我是一个物理服务器上混合部署4个tikv
因此我格式化了4个盘 分别挂载到 tidb-data1 2 3 4挂载点,因此你去删除一个我得挂载点 肯定是删除不成功的。
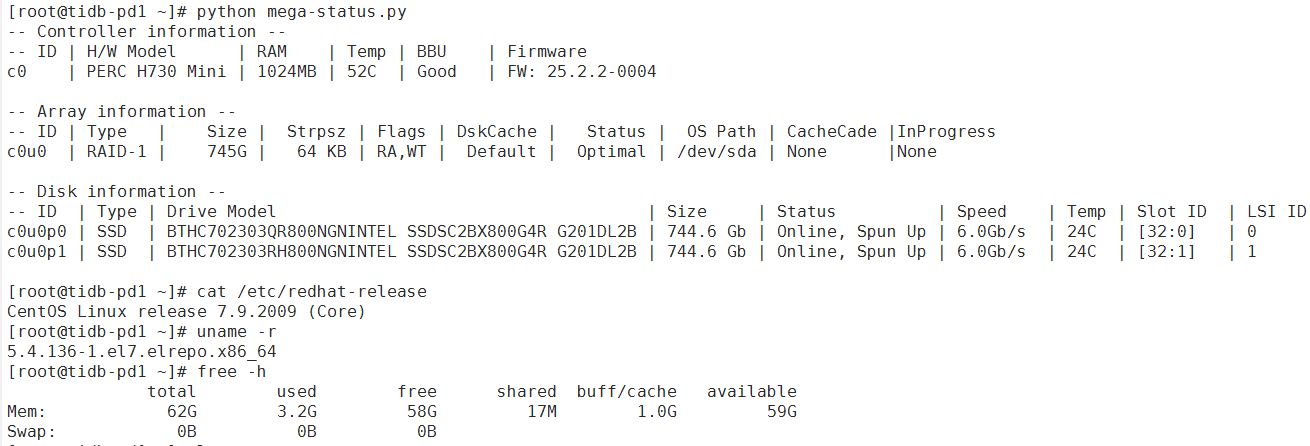
tidb部署环境机器:
tidb-server pd-server都在一台上,随机展示一台配置:
---------------------------------------------华丽的分割线---------------------------------------------------
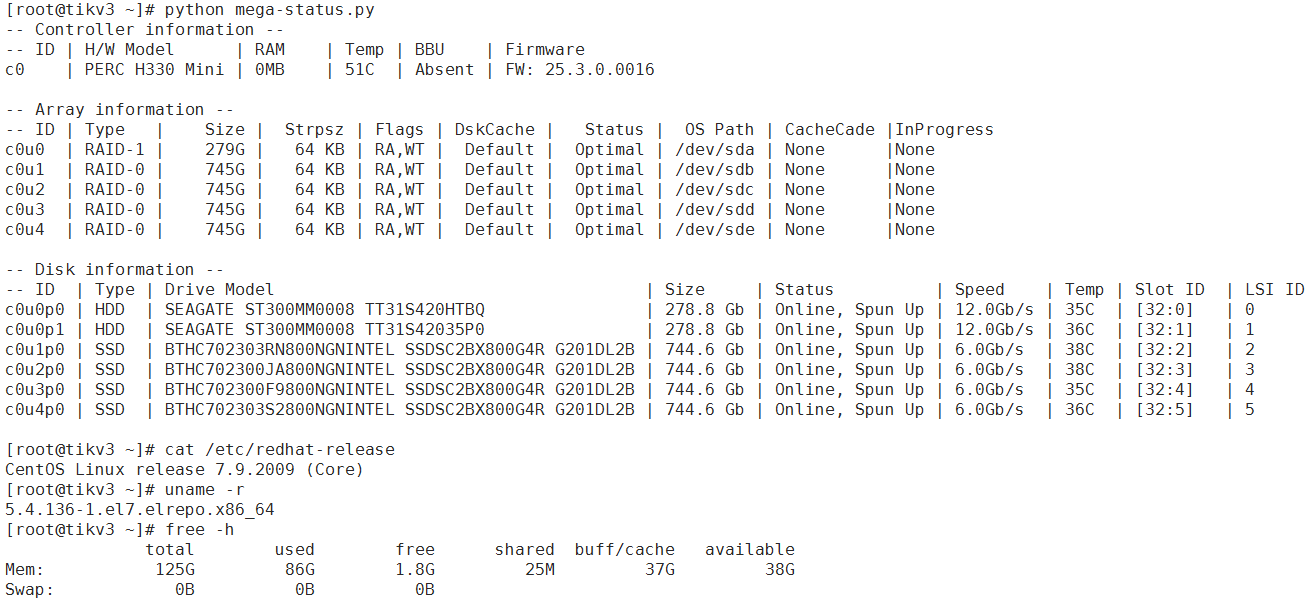
tikv-server随机展示一台配置:
部署方式如下:
tikv所在的物理服务器有额外的4个ssd存储,对应部署4个tikv实例
测试工具:
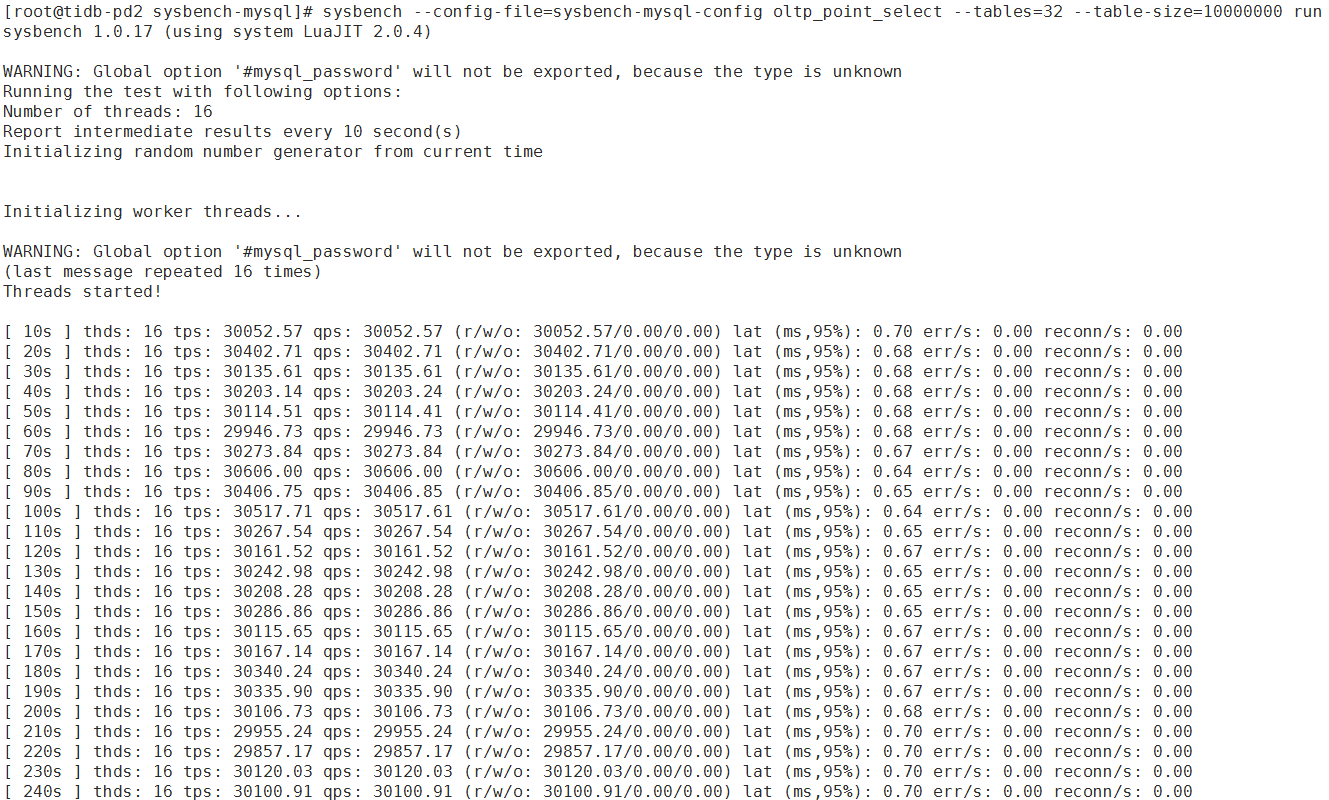
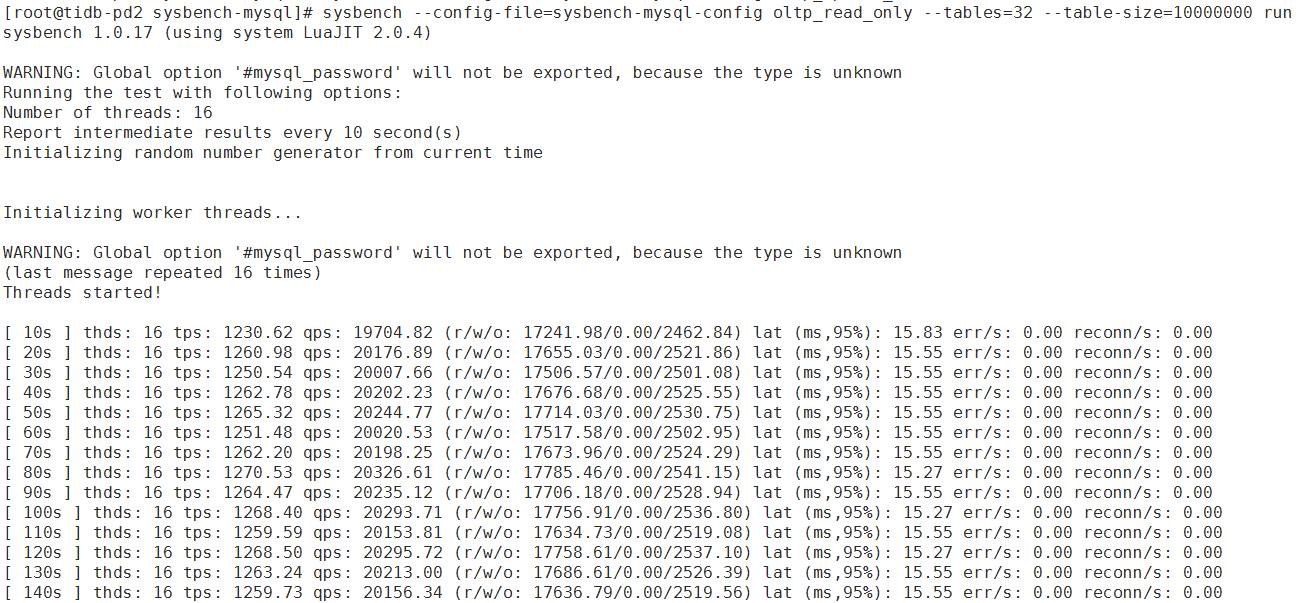
sysbench version:1.0.17(epel源直接安装的) 在tidb-pd2上做的测试

数据预热与统计信息收集已做
oltp_point_select结果:
oltp_update_index结果:
oltp_read_only结果:
几点小疑问,希望热心的大佬们帮忙解答一下:
①数据已预热的情况下 oltp_point_select 和oltp_read_only 测出来的性能是真实性能,还是数据都被缓存到内存里了,这个性能会偏高
②性能瓶颈肯定是在 tidb服务端吧,不在sysbench 测试工具吗
③有没有大佬 有相关的其他测试数据欢迎抛出来,大家共同交流一下(官方有数据也可以抛出来看下)
④手头上没有其他机器了,有没有mysql的sysbench性能测试的抛出来看下
spc_monkey
(carry@pingcap.com)
20
建议你按照官网的方式测试吧,你上面的结果,让我怀疑是你的测试没有给到 数据库压力
正好晚上有空,又重新跑了下
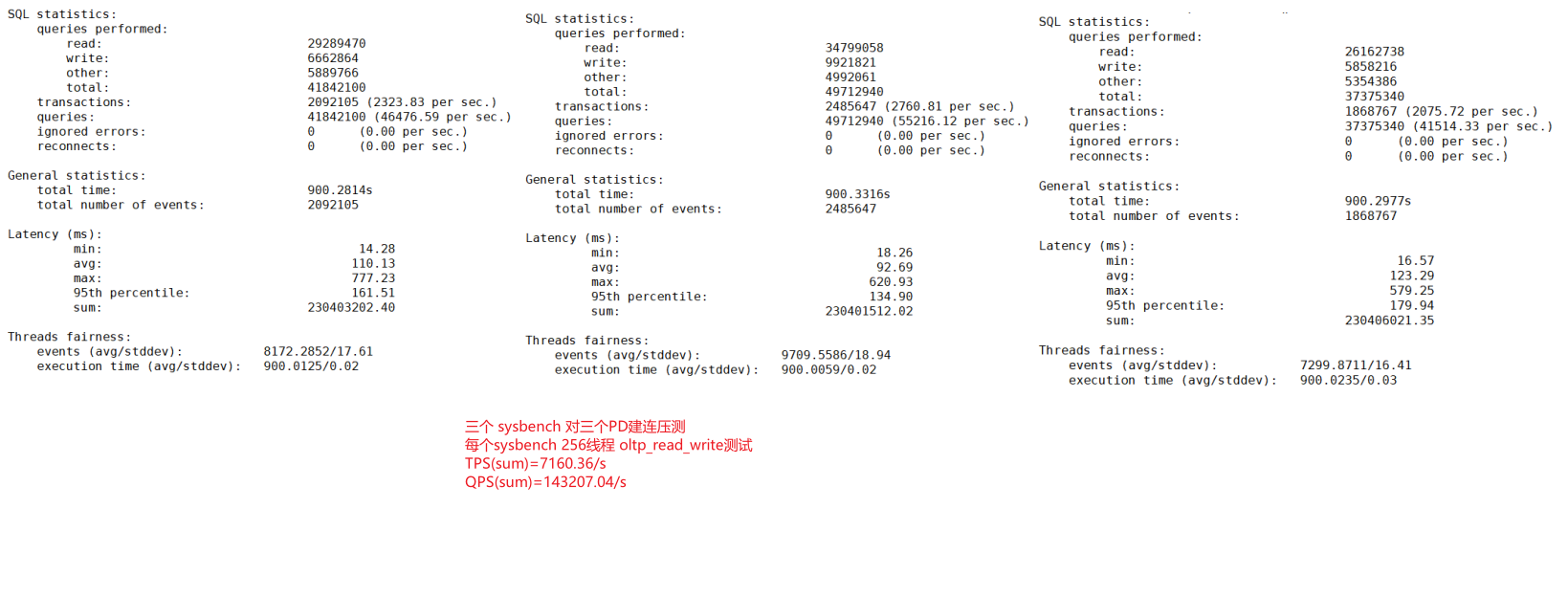
临时找了台物理机当客户端,跑三个sysbench 压三个tidb-server,每个sysbench 256线程oltp_read_write 压900s
测试结果如下
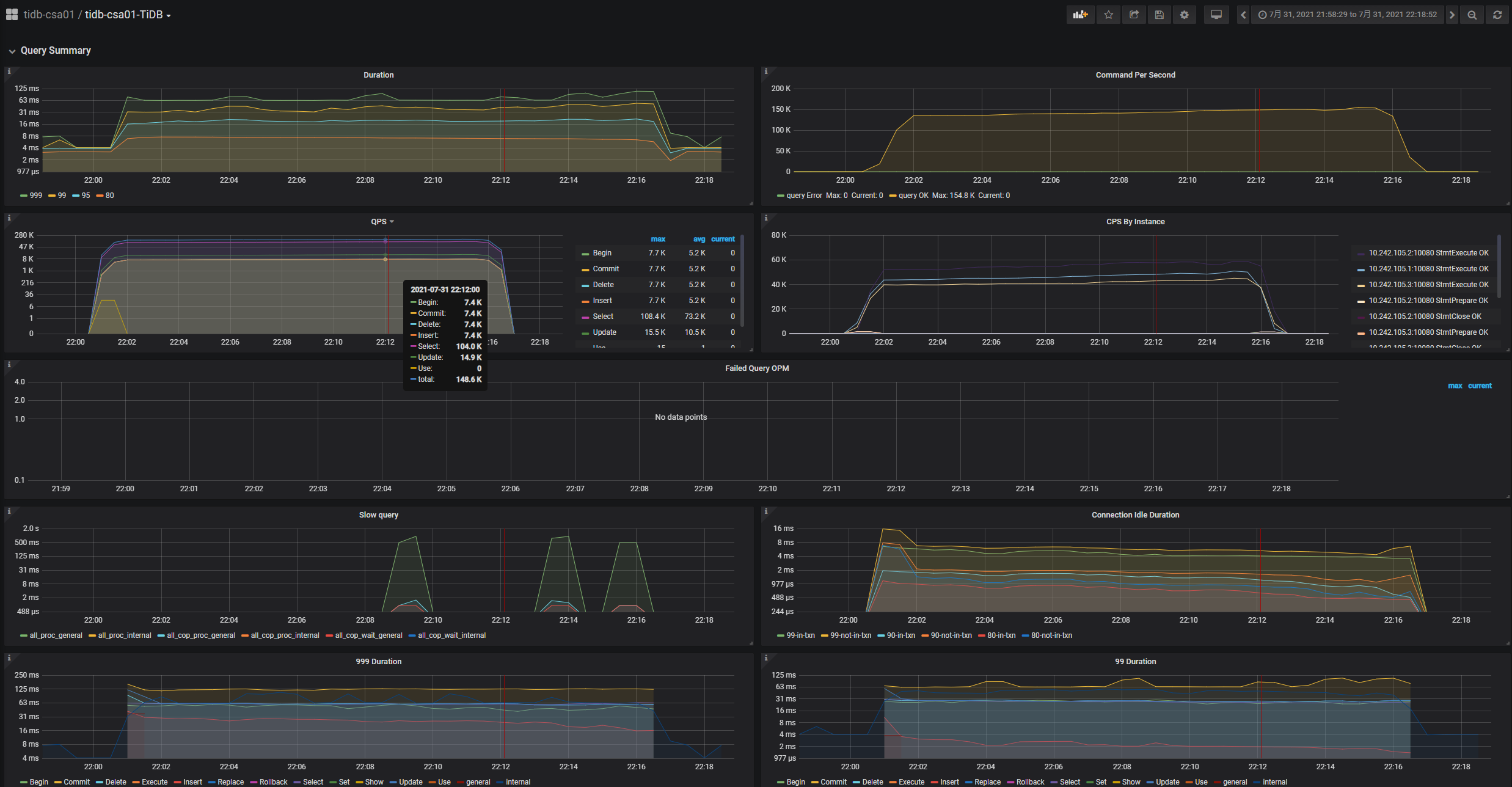
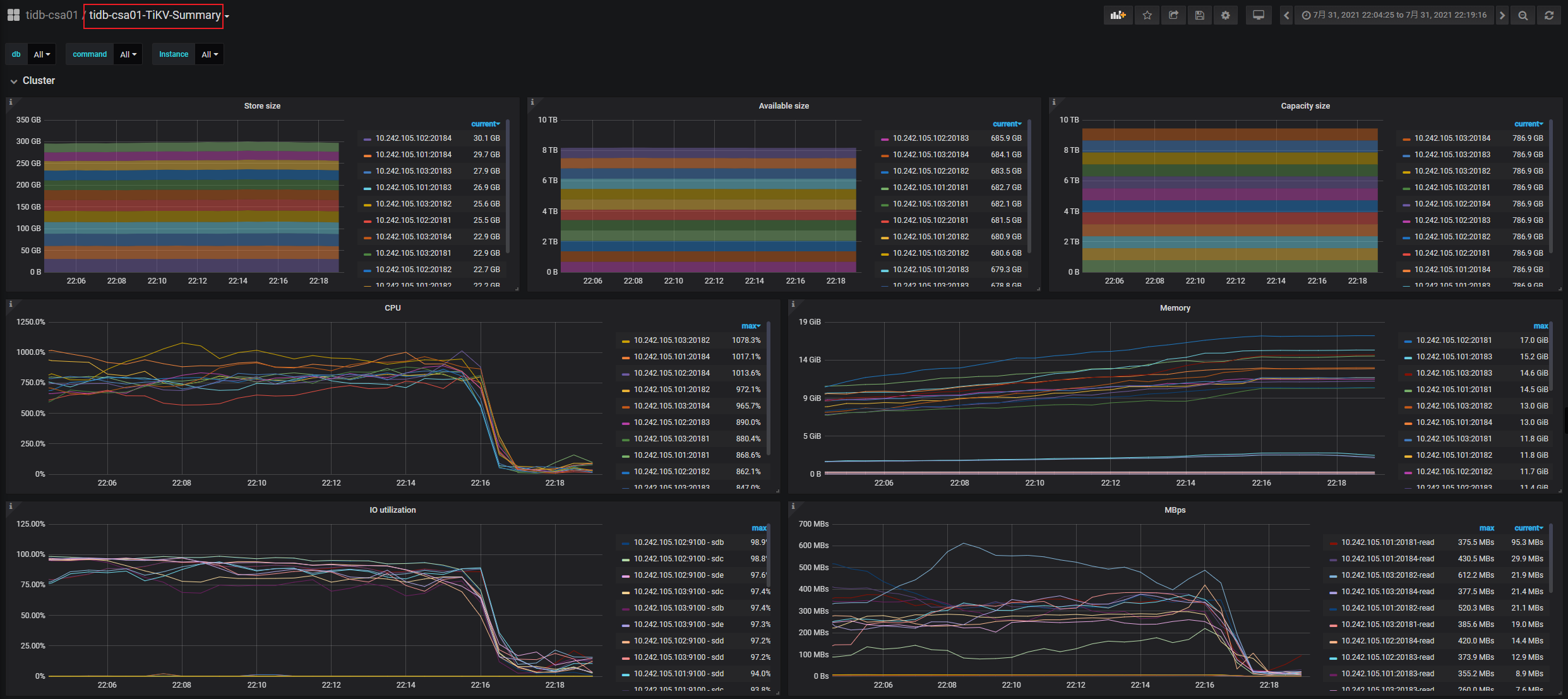
PD-server服务器资源使用情况
SQL相关统计信息
TIKV-server服务器资源使用情况
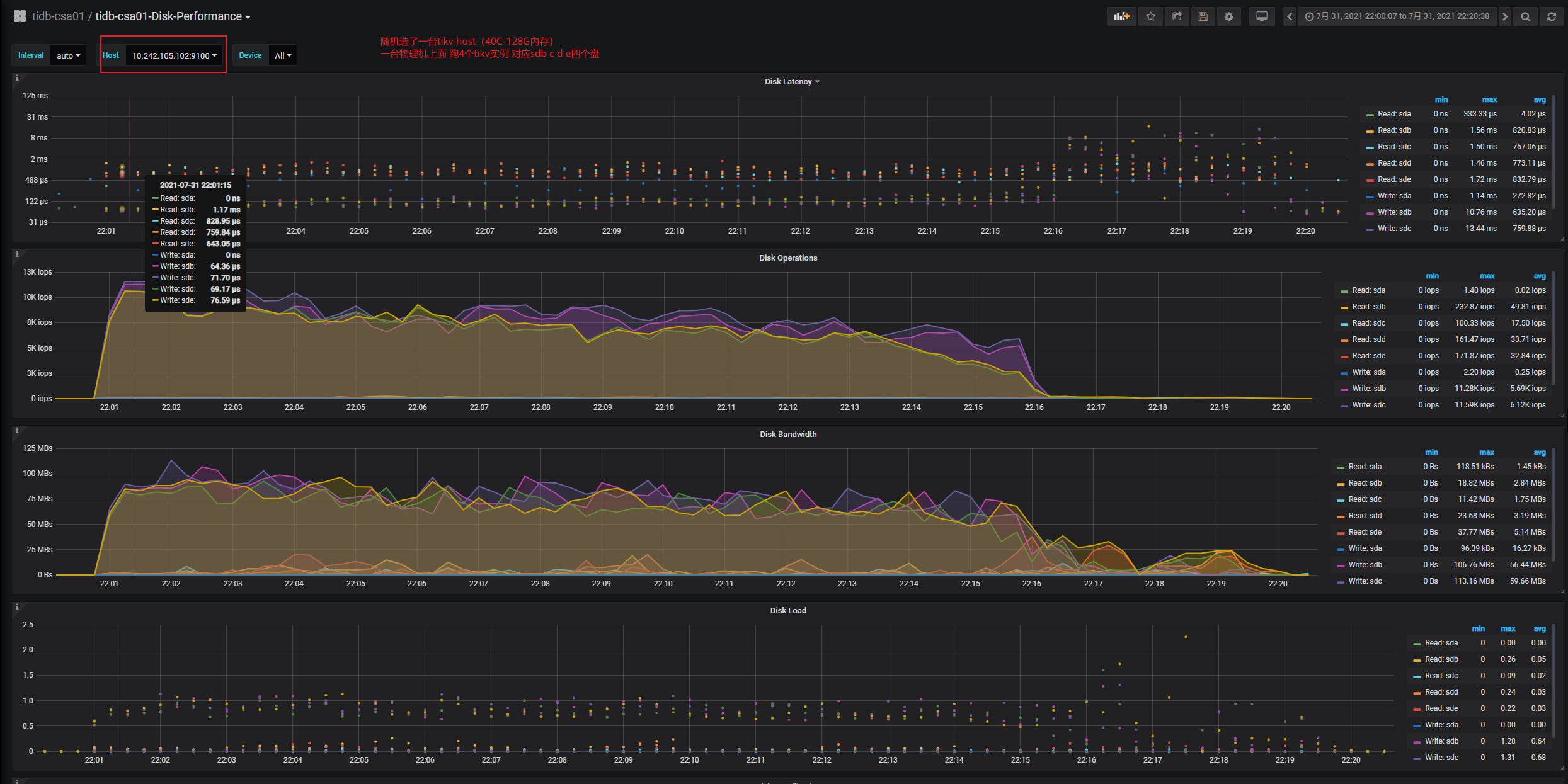
随机截了台host disk详细使用情况
你们监控做的太牛逼了。无敌!YYDS
有个问题:tikv实例关联的ssd 写的iops根本就不高,远远没达到ssd的写iops上限,怎么也得到25k iops吧,到了10k就压不上去了。是tikv cpu分少了到瓶颈了吗?
找了台物理机充当客户端 对tidb-pd2 进行了tpc-C压测:
tiup bench tpcc -H 10.242.105.2 -P 4000 -D tpcc -T 256 --warehouses 1000 run
开256线程,压测了17个小时
后续测试了三个tiup bench tpcc同时 跟三个tidb建连压测
tpmC(sum):117324
spc_monkey
(carry@pingcap.com)
26
1、一般情况下 ,cpu 可能先达到瓶颈(不过你的 tikv 有的 disk latency 已经很高了)(建议看 overview 监控面板下的 system info )
2、tidb-server 有个 token limit 参数,记得需要调大一些
3、测试 IO,其实有专门的工具 fio (具体 asktug 或官网低版本上都有介绍)(具体测试,我不敢说 IO 使用到多数是合理)
4、你的 tikv io utilization 已经很高了,可能需要注意下盘的情况(建议参考一下 读流程慢、写流程慢 2个帖子就分析一下)(2个帖子,asktug 上直接搜就ok)
1 个赞