提示这个
line 168: field per_table_memory_quota not found in type spec.CDCSpec
per-table-memory-quota 这个我也试过 一样
170M,400W条的数据, 这随便select into, 都会碰到吧。 咋就过不去了, 蛋疼。。。
1、额参数确实写法格式有问题
2、问一下,着急吗(我这边也没头绪了,看日志都是正常的,我得问问其他人有没有遇到过)
从监控看 table resolved ts 都已经正常推进;有 424万行数据堆积在 sink buffer (Sink rows buffer size)监控项;结合这两点可以推断事务已经开始向下游执行
大事务向下游执行是在一个 transaction 里,请问下游是 TiDB 还是 MySQL,对于大事务会执行比较久
下游是mysql, 这有什么办法优化吗,。
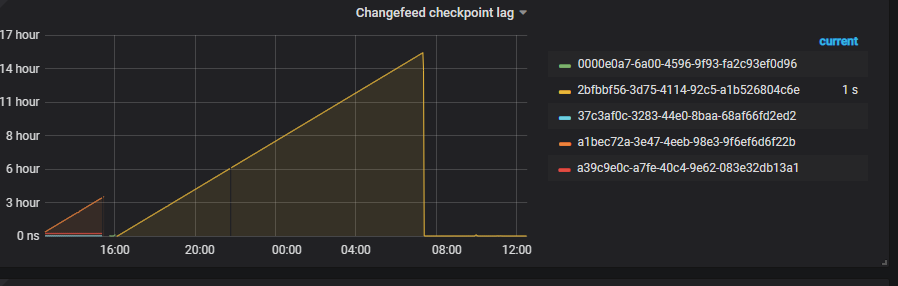
同步过来了 , 400W条 执行了15个小时,,, 数据大小才170M,
1、先确认是否有大事物,另外看看下游的消费速度吧
大事务是有的 insert into 一次提交就是400W,我觉得时间不是花在消费上面,看这图 几下就执行完了, 你们要不要测试下 这方面的情况?
我今天在测试一次提交2000条, 但是这种 大事务使用过程中一定会碰到的。。
“sorter”:{“num-concurrent-worker”:4,“chunk-size-limit”:999,“max-memory-percentage”:30,“max-memory-consumption”:17179869184,“num-workerpool-goroutine”:16,“sort-dir”:"/tmp/sorter"},“security”:{“ca-path”:"",“cert-path”:"",“key-path”:"",“cert-allowed-cn”:null},“per-table-memory-quota”:20971520,“kv-client”:{“worker-concurrent”:8,“worker-pool-size”:0,“region-scan-limit”:40}}`
就这几个参数,不过针对咱们这个场景,我这边也没有最佳实践
其实就是一个简单的 insert into select xxx FROM tbl
tbl 里面有 400w条记录,然后总共数据量也就是 180MB
主要是,因为这个语句导致了所有的cdc都会卡住,等待它
目前 ticdc 在 mysql sink 没有支持事务拆分,确实有这种问题,以后 ticdc 里会对此做优化。
当前阶段建议上游执行事务时做一下拆分。
那这个CDC对场景使用下适应性也太差了点
我觉得 insert into select 的这种日常太常见了.
按照这个说法.我如果随便一个统计结果做一个 insert,正好启用cdc
直接就挂了…
![]() ,可以关注 cdc 后面的表现,cdc 最近优化进度还是很快的
,可以关注 cdc 后面的表现,cdc 最近优化进度还是很快的
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。