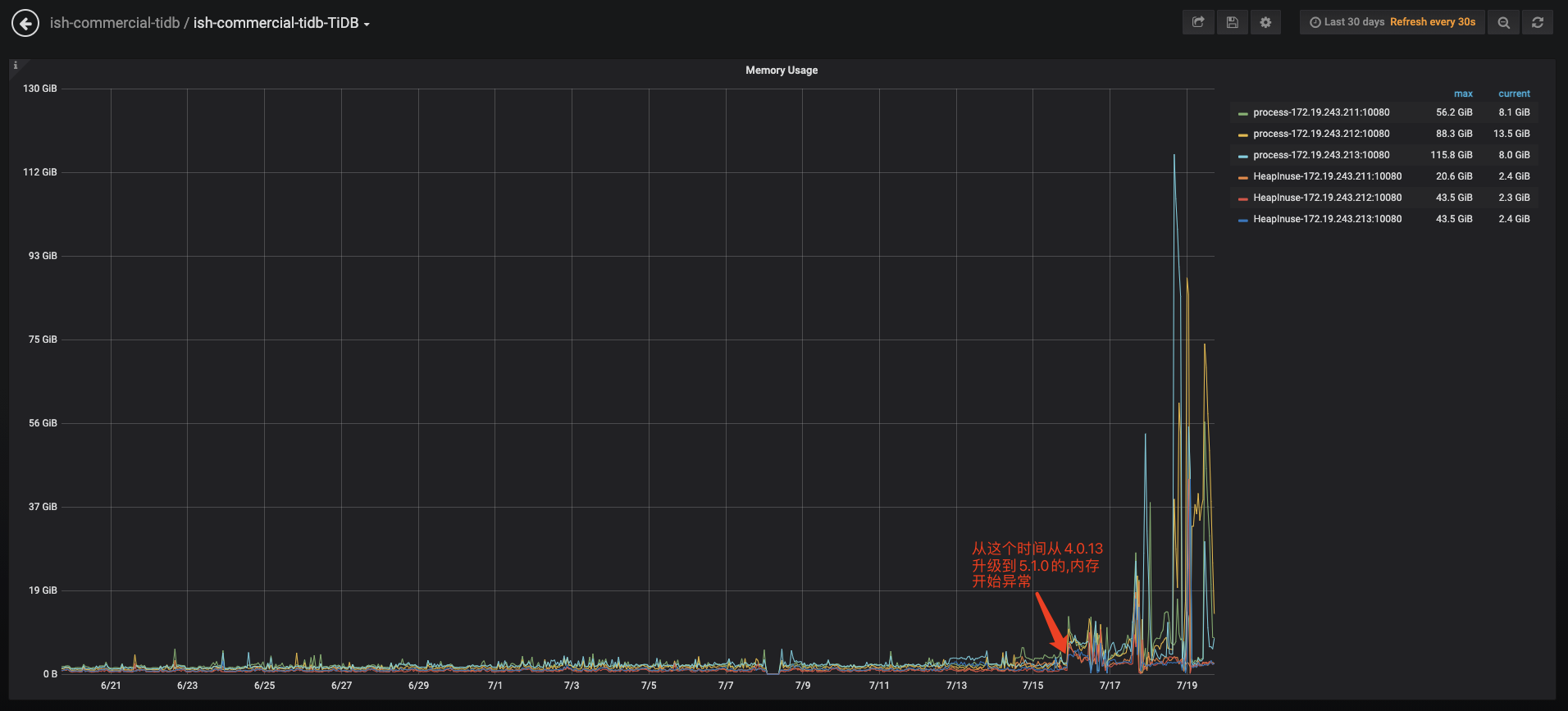
TIDB集群从4.0.13 升级到 5.1.0 后 TIDB 节点经常OOM
heap文件分析截图如下:

请问何解?
补上TIDB的内存监控图
我也想知道怎么打开这个文件
@niegang 问一下,现在咱们集群还经常 oom吗?方便给一下监控不(尤其是 tidb- server的,可参考:https://asktug.com/t/topic/37248)
google 浏览器就OK,也有单独的插件/工具之类(可以百度一下)
还是有OOM 我抓取监控后发给您帮忙分析下哈
监控抓了 您看看grafana-monitor.zip (3.4 MB)
好的。收到
有个兜底: 配置下 oom_action: cancel
好的 感谢 等集群空闲,我配置下看看效果
@niegang 看了一下 tidb-server 的监控,发现咱们集群慢日志是非常多的,而且有较多的 失败的 SQL(所以建议,咱们先看看慢SQL 问题,oom 的问题主要还是内存使用太高导致)
1、建议分析慢日志,可以用pt 工具,也可以直接查询 慢日志的系统表(根据内存使用排序),然后优化一下这些慢日志
2、关于 oom 问题,有相关的几个参数,咱们可以看一下官网,根据咱们的情况来配置一下( oom-use-tmp-storage、 mem-quota-query 、 memory-usage-alarm-ratio、 oom-action 等参数)可以直接进入这个连接,搜一下 oom 关键字就可https://docs.pingcap.com/zh/tidb/stable/tidb-configuration-file#oom-use-tmp-storage
3、咱们这有个问题:就是升级后,出现了较多的慢日志(这个应该是问题原因,但这个需要咱们先找一下变 慢 的 SQL,我们在一起分析一下)
感谢! 我们正在修改、优化SQL语句 有进展和您反馈
另: 我们升级后 慢日志和 失败的 SQL变多,是应为新版本对某些SQL不兼容导致的吗?
这个我不敢确定,应该不全是,其他客户没有太多类似反馈,还是需要咱们提供 具体 的 SQL 我来确认一下(其实 慢日志中,会有记录 这个 SQL 的执行计划的)
好的 等下次OOM, 我通过慢日志找出相应SQL语句提供您一起分析下
![]()
![]() 别啊,这个看监控,并不是只有一个2个 SQL 变慢,我建议可以找个时间统一分析一下 慢日志文件
别啊,这个看监控,并不是只有一个2个 SQL 变慢,我建议可以找个时间统一分析一下 慢日志文件
关键是 之前一次OOM时,我担心可能是慢日志造成的 把它给关闭了。。。
重新打开生效,需要滚动重启DB的吧
咋关闭的,可以参考在线修改参数:https://docs.pingcap.com/zh/tidb/dev/dynamic-config#在线修改集群配置
之前我是用tiup edit-config 写在配置文件里滚动重启生效的 如下:
server_configs:
tidb:
log.enable-slow-log:
用下面的方法也是可以的, 对吧
SET GLOBAL tidb_enable_slow_log = true;
对,不过不建议经常使用(目前还是实验特性)
收到~
好的![]()