【概述】
使用sync-diff-inspector校验分库分表场景下的数据:
上游数据库
库名:sandbox
表名:box_{0-127} # 共128张分表
下游TiDB
库名:sandbox
表名:box
【问题】
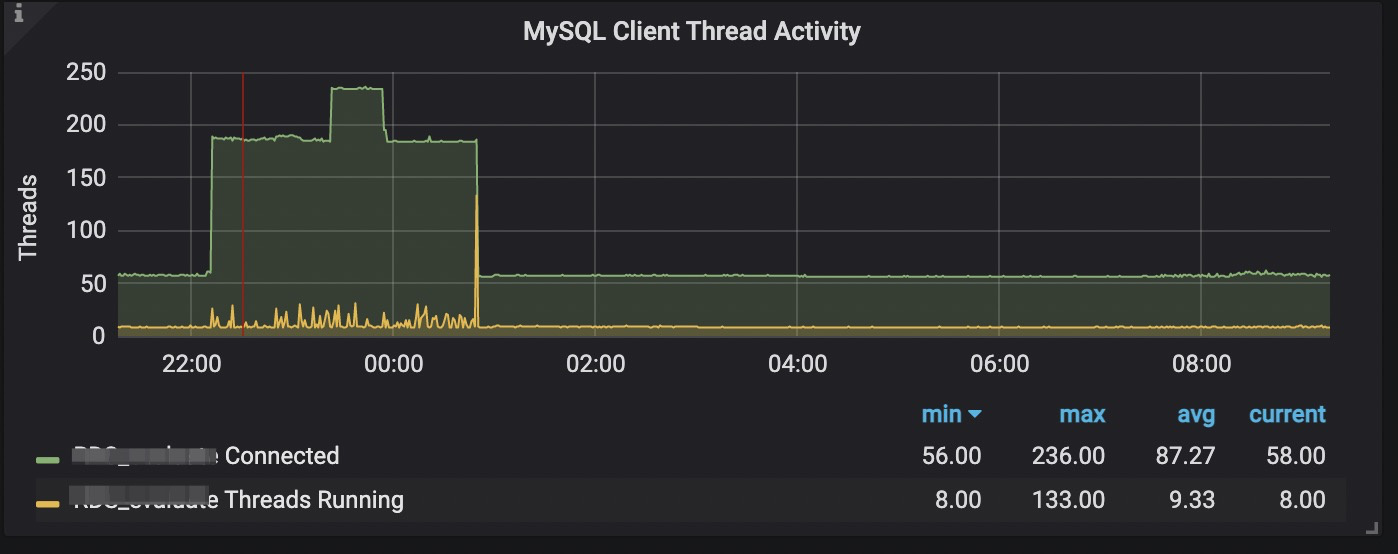
- 检查数据的线程数量(check-thread-count)设置为1,上游数据库压力大,监控发现多了128个并发:
在分库分表的情况下,如何控制上游数据库的线程数?
- 全量对比的时候,最后一个chunk的range没有upper界限,这样会可能导致最后拉取的数据很大,造成性能突刺:
【版本】
sync_diff_inspector: v5.0.3
1 个赞
QBin
(Bin)
2
辛苦上传一下 sync-diff-inspector 的校验日志。
日志太大,我截取了前面和后面,中间都是相似的
diff.log (38.4 KB)
附上配置:
合库合表的场景我们是需要根据check-thread-count或者其他的参数来精确控制连接数的,要不然分表太多,容易把上游数据库打爆,能否帮忙提下这个需求?
QBin
(Bin)
6
system
(system)
关闭
7
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。