天赐小郑
(天赐小郑)
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
TiDB版本v4.0.11
lighting版本:v5.1.0
【概述】
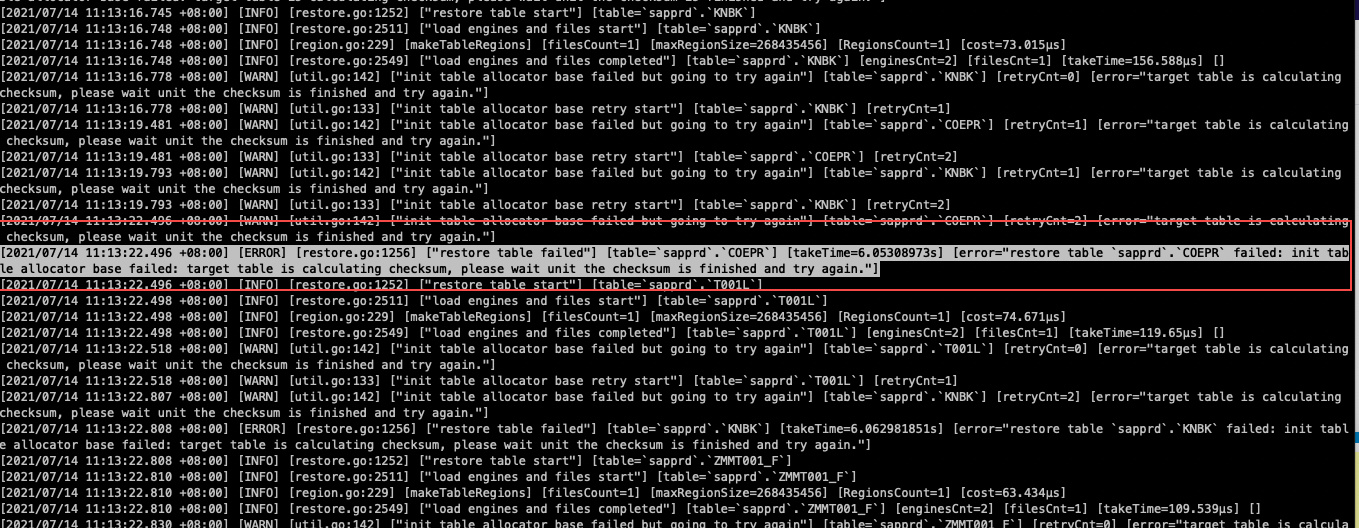
导入500G数据,中途发生错误
[2021/07/14 11:13:22.496 +08:00] [ERROR] [restore.go:1256] [“restore table failed”] [table=sapprd.COEPR] [takeTime=6.05308973s] [error=“restore table sapprd.COEPR failed: init table allocator base failed: target table is calculating checksum, please wait unit the checksum is finished and try again.”]
【备份和数据迁移策略逻辑】
dumpling备份
【问题】 无法继续回复数据
[日志]
tidb-lightning-10800.log.zip (2.1 MB)
3 个赞
懂的都懂
(wangtianyi)
4
我是指,导入之前,这些表在集群中就已经存在了是吗?
2 个赞
天赐小郑
(天赐小郑)
7
1.之前在A机器lighting导入 内存不足 ,删库
2.换备份机器
3.在新备份机器lighting导入,开始显示这个问题
想问的问题
1.这是操作流程,这个库比较大500G,我现在如果重新导入测试是否可行
2.这个checksum是怎么发生的
2 个赞
懂的都懂
(wangtianyi)
8
麻烦看一下是否有 lightning_metadata 库,有的话可以删除这个库,然后尝试导入
2 个赞
gaolei
(Gaolei)
12
@天赐小郑 这个应该是 lightning v5.1.0 新添加的特性导致的。手动把下游 tidb 集群里面 lightning_metadata 这个库删除就可以了
system
(system)
关闭
16
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。