为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
【概述】:场景 + 问题概述
服务器长时间运行,某段时间服务器负载比较高
【背景】:做过哪些操作
【现象】:业务和数据库现象
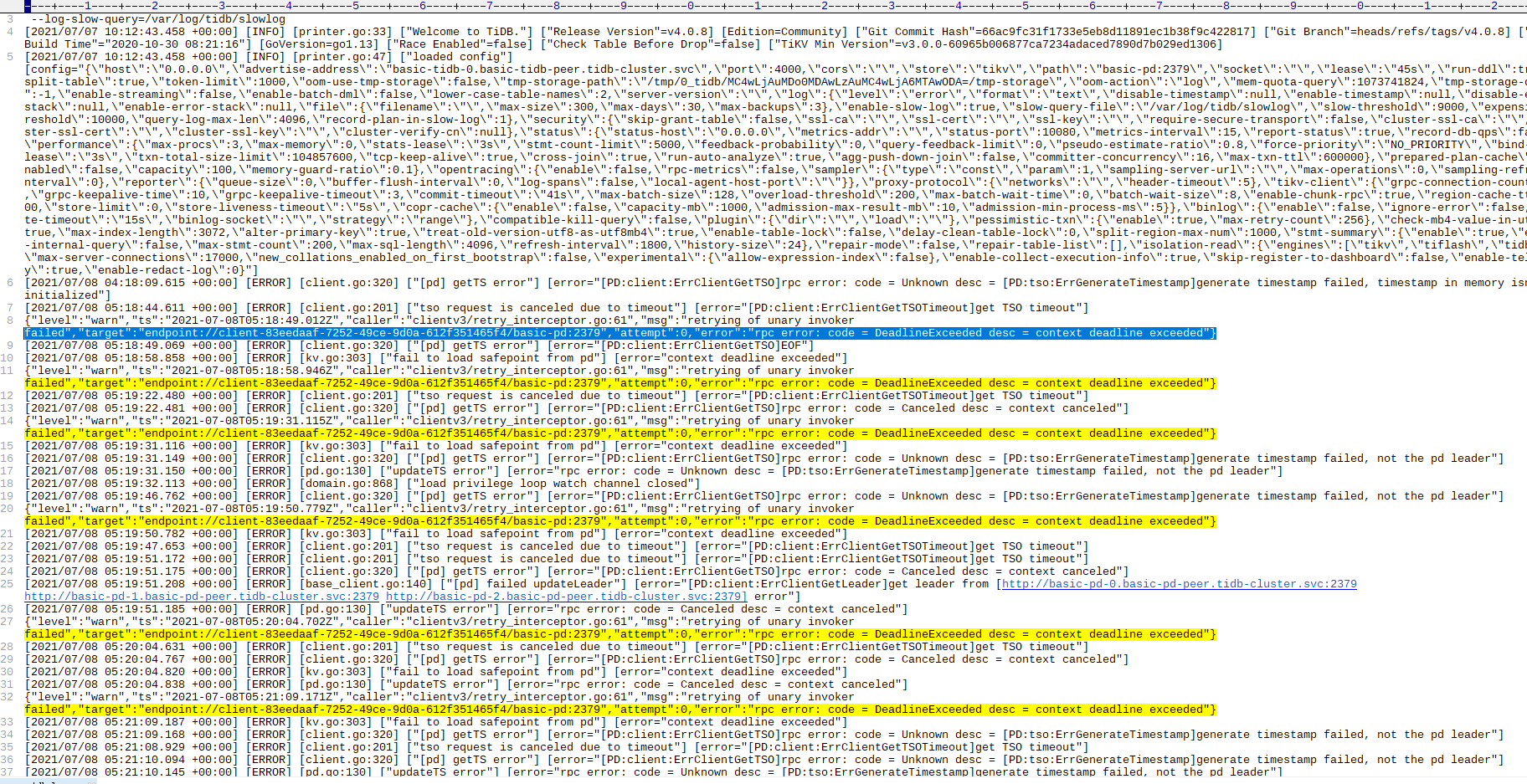
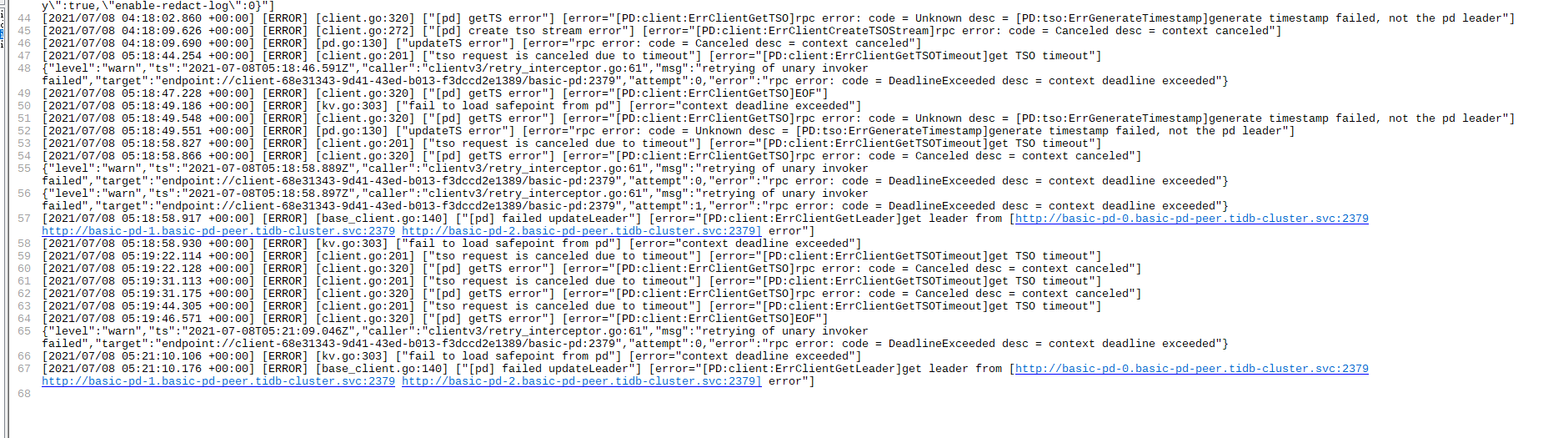
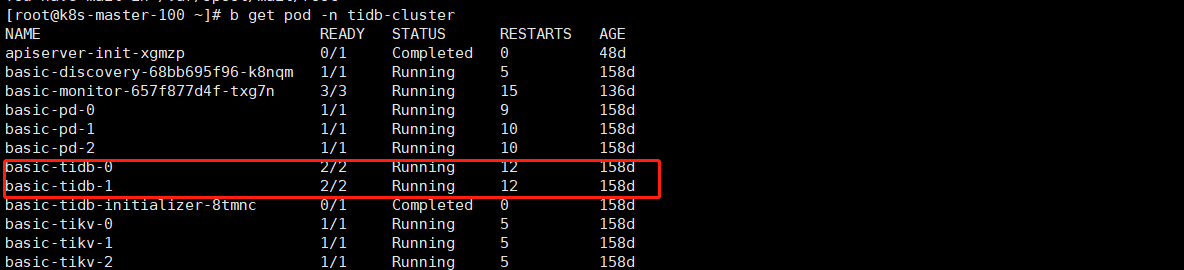
使用mysql命令行登录tidb数据库,一直卡顿在登录界面,观察tidb容器也没有新的日志刷新出来,观察pd,tikv,discovery没有错误日志,判断tidb出了问题,通过重启tidb容器解决。
【问题】:当前遇到的问题
【业务影响】:tidb数据库无法正常工作,导致以来tidb的业务都出了问题。
【TiDB 版本】:4.0.8
【TiDB Operator 版本】:1.1
【K8s 版本】:
1.14
【附件】:
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
1 个赞
xfworld
(魔幻之翼)
2
你提供的日志上,描述PD 挂了呢… 业务没受影响么?
pd leader 都丢了…
但是PD 的日志,没看出什么异常…
对,在那段时间机器负载比较高,但是后来我查看问题的时候是16点,这个日志是下午15点的,在我查看这个问题的时候pd已经正常了,并且在pd16点后的日志也没有错误信息,tidb的日志就停止到15点多就没有新的了
后来通过重启tidb容器解决的,所以感觉是tidb是不是有协程阻塞,或者卡死的逻辑,另外集群中网络检查过是正常的
@xfworld 或者说我认为有没有可能,tidb在连接pd出错超过某个阈值后就不会重试,或者重试的时间周期会变得很长
xfworld
(魔幻之翼)
6
超过某个时间周期,心跳失败会认为那个节点已经死了…
PD 上记录了所有节点的心跳周期信息… 实际上 PD 就是大脑…
我这么解释,你应该能理解了吧~
谢谢,那对于这个case,除了重启,有没有什么更优雅的方式
xfworld
(魔幻之翼)
8
分布式环境网络应该是最重要的了,如果出现这种情况,只能重启了吧
没得其他优雅的方式了 
超过某个时间周期,心跳失败会认为那个节点已经死了…
如果不认为节点已经死了,只是使用最大重试时间一直重试应该也是可以把
xfworld
(魔幻之翼)
10
大脑和其他之间的链接都断开了,这个时候依靠什么来判断重试的周期呢?
如果是 tidb 或者 tikv 断开了,PD ok,这个时候还有重试的机会…
好吧,那我想这个也可以通过kubernetes健康检测来规避吧,检索到不可用之后就重启pod,也可以避免掉这种某段时间高负载,等负载降下来集群无法恢复的问题
我是通过tidb-operator部署的,再tidb-operator有关配置中似乎没有看到健康检测的配置
https://docs.pingcap.com/zh/tidb-in-kubernetes/stable/tidb-cluster-chart-config
xfworld
(魔幻之翼)
12
Prometheus 可以提供监控,但是无法解决周期重试性的问题,你可以通过k8s 其他的规则来配置资源追加的方式,比如 必须保持 PD正常,如果少于 多少个节点,就启动几个节点,保持正常
死掉的就直接收回就好了
这个也是弹性方案的一种,比较靠谱
1 个赞
现在是通过tidb-operator安装的tidb集群,但是这种方式好像不能很灵活的添加配置,我想加一些k8s的健康检测
system
(system)
关闭
14
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。