1、tidb 4.0
2、mysql 5.7
3、tidb 全库同步到mysql,报错“”error="Error 1062: Duplicate entry ‘20607217’ for key 'PRIMARY“”
1)drainer 错误日志如下
drainer (1).log (254.6 KB)
2) 表结构信息如下
Create Table: CREATE TABLE file_info (
id bigint(20) NOT NULL AUTO_INCREMENT COMMENT ‘文件Id’,
file_checksum varchar(40) COLLATE utf8mb4_bin NOT NULL DEFAULT ‘’ COMMENT ‘文件checksum’,
file_size bigint(20) NOT NULL DEFAULT ‘0’ COMMENT ‘文件大小’,
file_status tinyint(4) NOT NULL DEFAULT ‘0’ COMMENT ‘文件状态: 0-有效, 1-待清除, 2-物理删除’,
rel_times int(11) NOT NULL DEFAULT ‘0’ COMMENT ‘被引用次数’,
oss_type varchar(20) COLLATE utf8mb4_bin NOT NULL DEFAULT ‘’ COMMENT ‘存储类型’,
oss_bucket varchar(50) COLLATE utf8mb4_bin NOT NULL DEFAULT ‘’ COMMENT ‘存储桶名’,
oss_key varchar(100) COLLATE utf8mb4_bin NOT NULL DEFAULT ‘’ COMMENT ‘OSS_KEY’,
create_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ‘创建时间’,
update_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT ‘更新时间’,
PRIMARY KEY (id),
KEY idx_fileChecksum (file_checksum),
KEY idx_updateTime_fileStatus (update_time,file_status),
KEY idx_createTime_fileStatus (create_time,file_status),
KEY idx_ossKey (oss_key)
) ENGINE=InnoDB AUTO_INCREMENT=21876603 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT=‘文件信息总表’
3)
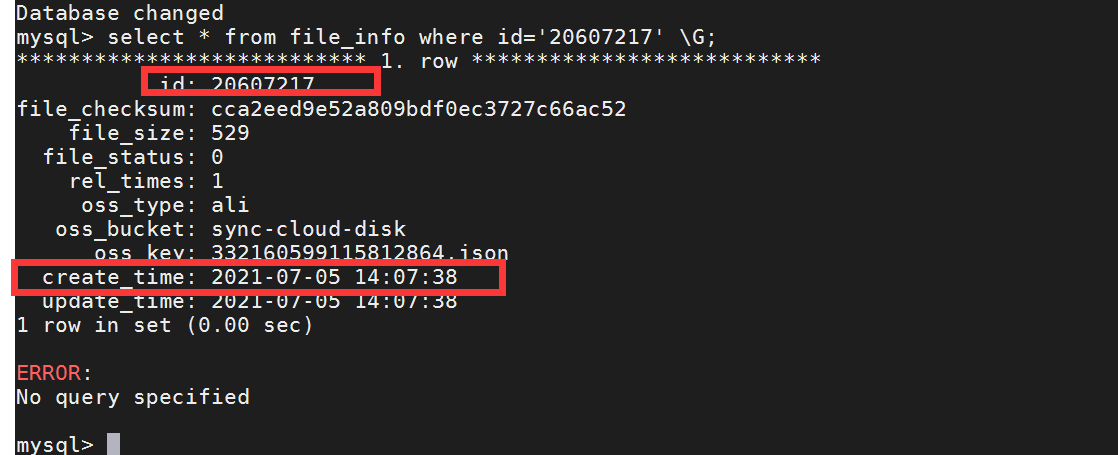
tidb 表数据查询结果:
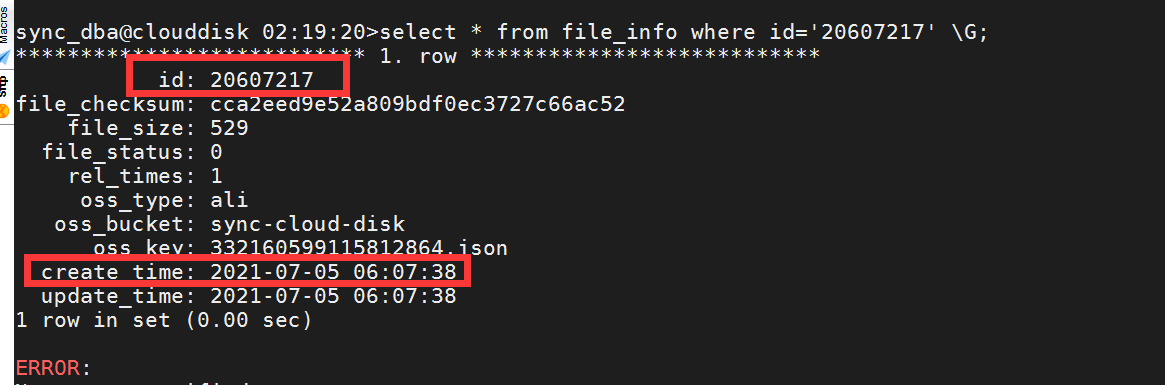
mysql表数据查询结果:
2 个赞
这道题我不会
(Lizhengyang@PingCAP)
2
下游的 MySQL 的数据来源,除了上面这个 TiDB 集群外,还有其他的来源吗?
1 个赞
没有了,这个mysql是用作tidb备份的,只有tidb数据来源
1 个赞
这道题我不会
(Lizhengyang@PingCAP)
4
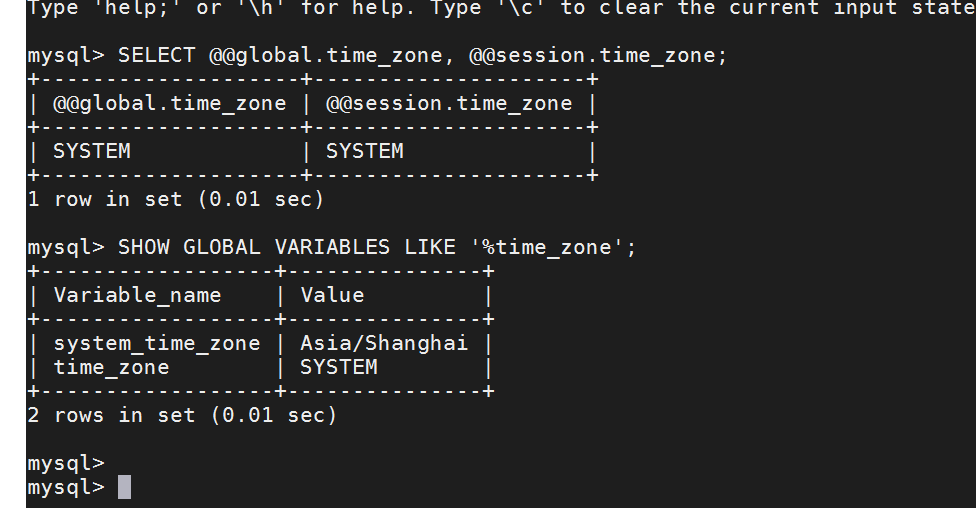
从上面截图中看,create_time 相差了 8 个小时,这里麻烦先确认上下游的时区是否不一致。
1 个赞
这道题我不会
(Lizhengyang@PingCAP)
6
方便提供下具体的 drainer 配置信息吗?另外,可以看下是否方便先临时将下游重复的记录先删除掉,然后让 drainer 进程先跑起来。
1 个赞
1、drainer.toml 文件如下
Drainer Configuration.
Drainer 提供服务的地址(“192.168.0.13:8249”)
addr = “10.129.3.242:8249”
Drainer 对外提供服务的地址
advertise-addr = “10.129.3.242:8249”
向 PD 查询在线 Pump 的时间间隔 (默认 10,单位 秒)
detect-interval = 10
Drainer 数据存储位置路径 (默认 “data.drainer”)
data-dir = “data.drainer”
PD 集群节点的地址 (英文逗号分割,中间不加空格)
pd-urls = “http://10.129.4.72:2379,http://10.129.3.241:2379,http://10.129.3.243:2379”
log 文件路径
log-file = “drainer.log”
Drainer 从 Pump 获取 binlog 时对数据进行压缩,值可以为 “gzip”,如果不配置则不进行压缩
compressor = “gzip”
[security]
如无特殊安全设置需要,该部分一般都注解掉
包含与集群连接的受信任 SSL CA 列表的文件路径
ssl-ca = “/path/to/ca.pem”
包含与集群连接的 PEM 形式的 X509 certificate 的路径
ssl-cert = “/path/to/pump.pem”
包含与集群链接的 PEM 形式的 X509 key 的路径
ssl-key = “/path/to/pump-key.pem”
Syncer Configuration
[syncer]
如果设置了该项,会使用该 sql-mode 解析 DDL 语句,此时如果下游是 MySQL 或 TiDB 则
下游的 sql-mode 也会被设置为该值
sql-mode = “STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION”
输出到下游数据库一个事务的 SQL 语句数量 (默认 20)
txn-batch = 20
同步下游的并发数,该值设置越高同步的吞吐性能越好 (默认 16)
worker-count = 4
是否禁用拆分单个 binlog 的 SQL 的功能,如果设置为 true,则按照每个 binlog
顺序依次还原成单个事务进行同步(下游服务类型为 MySQL, 该项设置为 False)
disable-dispatch = false
safe mode 会使写下游 MySQL/TiDB 可被重复写入
会用 replace 替换 insert 语句,用 delete + replace 替换 update 语句
safe-mode = false
Drainer 下游服务类型(默认为 mysql)
参数有效值为 “mysql”,“tidb”,“file”,“kafka”
db-type = “mysql”
事务的 commit ts 若在该列表中,则该事务将被过滤,不会同步至下游
ignore-txn-commit-ts = []
db 过滤列表 (默认 “INFORMATION_SCHEMA,PERFORMANCE_SCHEMA,mysql,test”),
不支持对 ignore schemas 的 table 进行 rename DDL 操作
ignore-schemas = “INFORMATION_SCHEMA,PERFORMANCE_SCHEMA,mysql”
replicate-do-db 配置的优先级高于 replicate-do-table。如果配置了相同的库名,支持使用正则表达式进行配置。
以 ‘~’ 开始声明使用正则表达式
replicate-do-db = ["~^b.*",“s1”]
replicate-do-db = [“clouddisk”]
[syncer.relay]
保存 relay log 的目录,空值表示不开启。
只有下游是 TiDB 或 MySQL 时该配置才生效。
log-dir = “”
每个文件的大小上限
max-file-size = 10485760
[[syncer.replicate-do-table]]
db-name =“test”
tbl-name = “log”
[[syncer.replicate-do-table]]
db-name =“test”
tbl-name = “~^a.*”
忽略同步某些表
[[syncer.ignore-table]]
db-name = “test”
tbl-name = “log”
db-type 设置为 mysql 时,下游数据库服务器参数
[syncer.to]
host = “10.192.14.103”
user = “rep”
如果你不想在配置文件中写明文密码,则可以使用 ./binlogctl -cmd encrypt -text string 生成加密的密码
如果配置了 encrypted_password 且非空,那么配置的 password 不生效。encrypted_password 和 password 无法同时生效。
password = “Rep1234!”
encrypted_password = “”
port = 3306
[syncer.to.checkpoint]
当 checkpoint type 是 mysql 或 tidb 时可以开启该选项,以改变保存 checkpoint 的数据库
schema = “tidb_binlog”
目前只支持 mysql 或者 tidb 类型。可以去掉注释来控制 checkpoint 保存的位置。
db-type 默认的 checkpoint 保存方式是:
mysql/tidb -> 对应的下游 mysql/tidb
file/kafka -> file in data-dir
type = “mysql”
host = “127.0.0.1”
user = “root”
password = “”
使用 ./binlogctl -cmd encrypt -text string 加密的密码
encrypted_password 非空时 password 会被忽略
encrypted_password = “”
port = 3306
db-type 设置为 file 时,存放 binlog 文件的目录
[syncer.to]
dir = “data.drainer”
db-type 设置为 kafka 时,Kafka 相关配置
[syncer.to]
kafka-addrs 和 zookeeper-addrs 只需要一个,两者都有时程序会优先用 zookeeper 中的 kafka 地址
zookeeper-addrs = “127.0.0.1:2181”
kafka-addrs = “127.0.0.1:9092”
kafka-version = “0.8.2.0”
kafka-max-messages = 1024
保存 binlog 数据的 Kafka 集群的 topic 名称,默认值为 _obinlog
如果运行多个 Drainer 同步数据到同一个 Kafka 集群,每个 Drainer 的 topic-name 需要设置不同的名称
topic-name = “”
2、启动命令
nohup ./drainer -config drainer.toml -initial-commit-ts 426254952726265858 &
1 个赞
这道题我不会
(Lizhengyang@PingCAP)
8
上面的 initial-commit-ts 的值是从哪里获取到的?
1 个赞
mydumper,metadata文件
先根据mydumper备份文件,loader恢复到mysql,然后drainer 增量更新
1 个赞
这道题我不会
(Lizhengyang@PingCAP)
10
1.请问上游是是只配置了一个 drainer 进程还是有其他多个 drainer 进程,如果有多个可能会导致重复数据产生;
2.麻烦在上游 tidb 集群中查询下冲突记录的 MVCC 信息,命令如下:
curl http://{TiDBIP}:{status_port}/mvcc/key/clouddisk/file_info/20607217
1 个赞
1、只有这一个进程
2、
5.7.25-TiDB-v4.0.0▒Y?C%z▒▒.[o/PHH|mysql_native_passwordtinvalid sequence 32 != 1
1 个赞
这道题我不会
(Lizhengyang@PingCAP)
12
第二个命令中端口不对,应该填写 tidb 的状态端口,如果没有专门设置过的话默认是 10080
[root@AB-LESYNC-PRO-tidb-1 ~]# curl http://10.129.4.73:10080/mvcc/key/clouddisk/file_info/20607217
{
“key”: “74800000000000003E5F7280000000013A70F1”,
“region_id”: 29270,
“value”: {
“info”: {
“writes”: [
{
“start_ts”: 426105964678086658,
“commit_ts”: 426105964691193858,
“short_value”: “gAAJAAAAAgMEBQYHCAkKIAAiACMAJAAnADYATQBVAF0AY2NhMmVlZDllNTJhODA5YmRmMGVjMzcyN2M2NmFjNTIRAgABYWxpc3luYy1jbG91ZC1kaXNrMzMyMTYwNTk5MTE1ODEyODY0Lmpzb24AAADmYQqqGQAAAOZhCqoZ”
}
]
}
}
}[root@AB-LESYNC-PRO-tidb-1 ~]#
这道题我不会
(Lizhengyang@PingCAP)
14
上面的 commit_ts 解析之后的时间为 2021-07-05 14:07:38.374 +0800 CST ,而且也只有一条记录,说明上游 tidb 确实不存在重复写入问题,现在问题原因还不太好定位,还需要再分析下,如果着急将完成数据同步的话,可以考虑将冲突的 4 条记录在下游 MySQL 中删除,或者直接重新同步下数据。
删除了的话,drainer 跑起来。这条数据就不会在同步了吧
这道题我不会
(Lizhengyang@PingCAP)
16
如果 drainer 从报冲突的 ts 点开始同步,数据应该是可以同步到下游的;当然最简单直接的方法是重新同步下表数据。
drainer 我先同步到文件file,看下是否有冲突,生成的binlog-0000000000000000-20210713160118 这个文件,用啥工具可以查看内容呢
这道题我不会
(Lizhengyang@PingCAP)
18
1、reparo.toml
data-dir = “/data/apps/tidb-v4.0.0/bin/relaylog”
log-level = “debug”
dest-type = “print”
txn-batch = 20
worker-count = 4
safe-mode = false
2、drainer.toml 配置了relaylog存放位置
[syncer.relay]
log-dir = “/data/apps/tidb-v4.0.0/bin/relaylog”
max-file-size = 1048576000
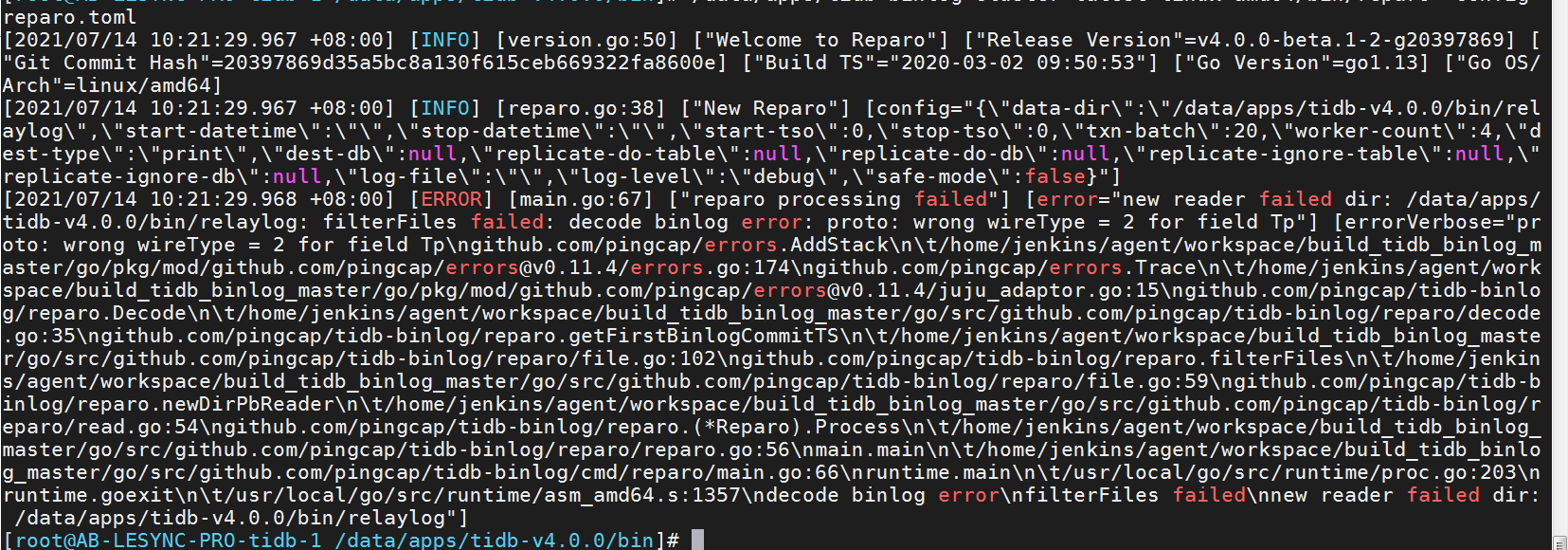
3、执行/data/apps/tidb-binlog-cluster-latest-linux-amd64/bin/reparo -config reparo.toml报错呢
spc_monkey
(carry@pingcap.com)
20
这个问题解决了吗?咱们不是有 safe mode 模式嘛