【概述】 大量 AP SQL 并发下, tidb_projection_concurrency 参数设置较大是否会将 TiDB CPU 打满危及生产
【背景】 POC 一原 MyCat 主 AP 业务系统下迁 TiDB 场景,发现主要压力在 TiDB 测做 Projection 部分。
【现象】 单条 SQL 单并发下最高内存从 Grafana 观察消耗 40G 左右内存。使用 tidb_projection_concurrency = 16 可达到最佳优化效果。
【问题】 依据 tidb_projection_concurrency 官网介绍,该业务最高可达 400 并发(虽可在应用层限制),被客户问及如果该参数设置过大,会不会出现生产 TiDB 实例因为 CPU 占用过高导致崩溃?
【业务影响】 如果 TiDB 实例崩溃可能影响 TP 部分业务。
【TiDB 版本】 V4.0.13
我大概看了下 github代码位置,发现该参数的实现方式为 ProjectionExec.prepare 实例化该 numWorkers 数量的结构体保存到数组中,成为 ProjectionExec 的属性。
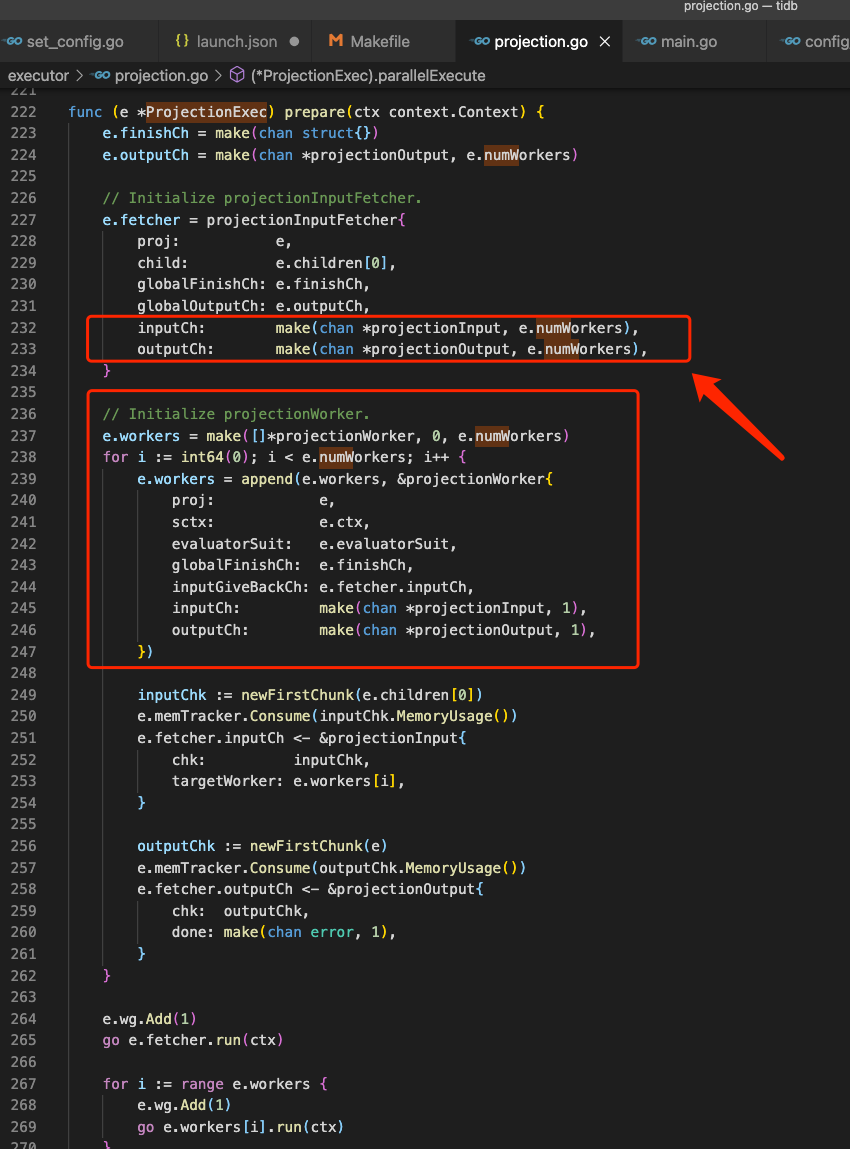
每个 worker (*projectionWorker) 都有自己的 Channel (inputCh) 属性,在 recoveryProjection 中被用于接收来自 Chunk 的数据交给 targetWorker 处理,targetWorker 在 prepare “下面代码阶段” 被分配,一旦 mysql client session 连接成功该变量值就被初始化完毕,这也该系统变量是 session 级变量的原因吧!!!
func (e *ProjectionExec) prepare(ctx context.Context) {
......
......
e.fetcher.inputCh <- &projectionInput{
chk: inputChk,
targetWorker: e.workers[i],
}
......
......
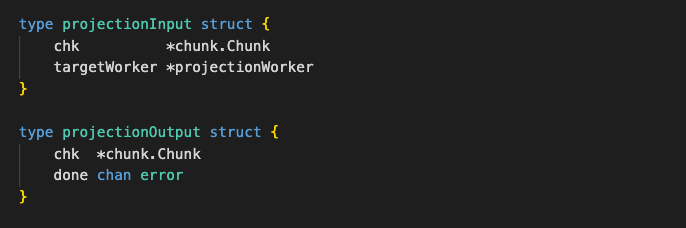
每个 session 初始化 numWorkers 数量的 projectionInputFetcher.inputCh ,也就对应 numWorkers 数量的 Workers,所以当 session 并发非常高时,还是可能会出现把 CPU 打满的情况。
如:
400 AP 并发,每个 session 的 tidb_projection_concurrency 均为 16,1 个 TiDB 实例;
则总 numWorkers 数量 400 * 16 = 4600,可能会造成服务器 CPU 非常繁忙的;
了解了一下 go 的 GPM 并发模型,虽然存在 Processor 的调度,理论上还是会出现 Machine 每非常繁忙,也就是 CPU 用于计算 AP SQL 非常繁忙的情况。
// Initialize projectionInputFetcher.
e.fetcher = projectionInputFetcher{
proj: e,
child: e.children[0],
globalFinishCh: e.finishCh,
globalOutputCh: e.outputCh,
inputCh: make(chan *projectionInput, e.numWorkers),
outputCh: make(chan *projectionOutput, e.numWorkers),
}
问题总结
当然,我上面的论述与 TIDB 的 CPU vCore 数量强相关,而且还可以通过扩充 TiDB 来解决。
我想问下,我上面的分析是否正确?求 review !