为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【概述】 场景 + 问题概述
oltp场景下 ,我们迁移新集群后,io utilization 过高, 。
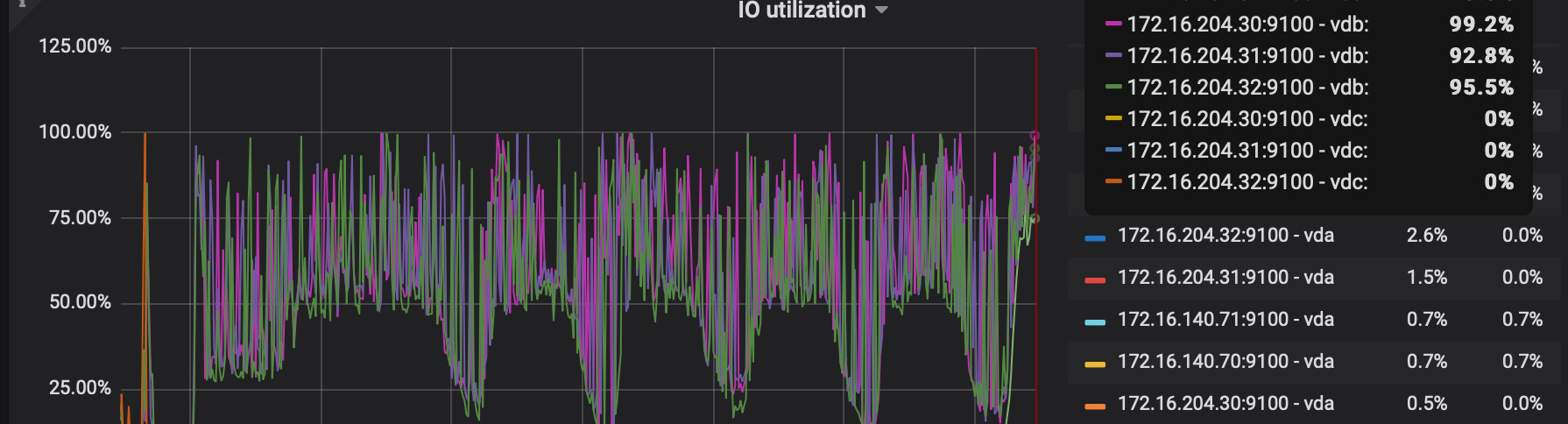
查询发现 raft append 和 apply 都是10ms甚至更低。
【背景】 做过哪些操作
tidblightning 导入数据
【现象】 业务和数据库现象
暂无异常现象
【问题】 当前遇到的问题
io utilization 过高
【业务影响】
其他都很正常,日志也没异常,系统负载偏低, 有点担心,io应该会导致cpu利用率 不高。
【TiDB 版本】
v4.0.9
【应用软件及版本】
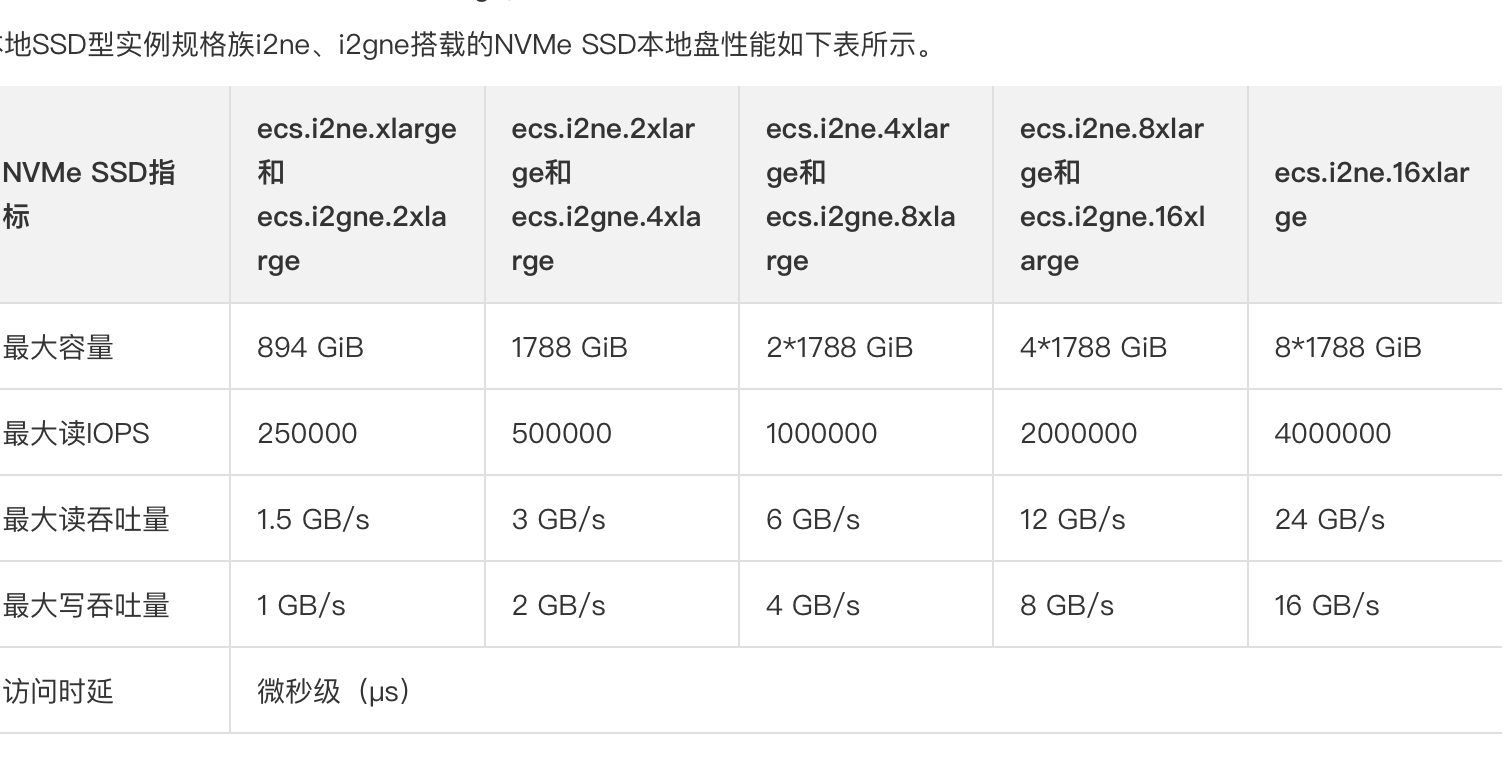
tikv虚拟机配置: 本地 SSD 网络增强型 i2gne / ecs.i2gne.8xlarge(32vCPU 128GiB)
【附件】 相关日志及配置信息

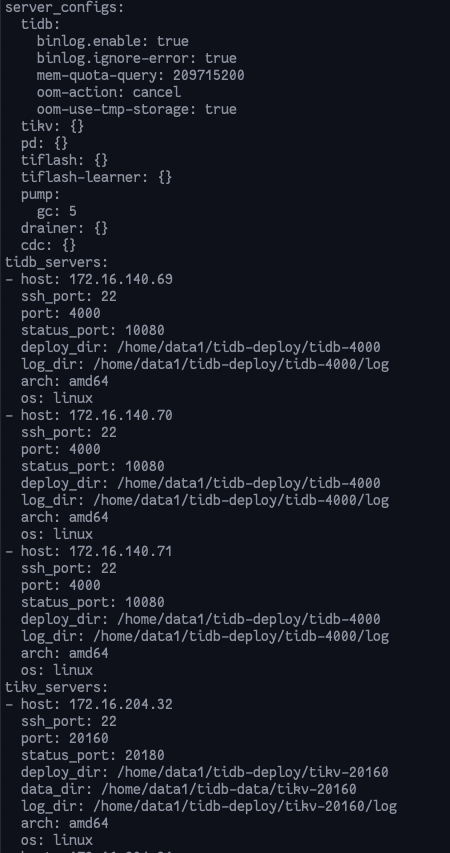
- TiUP Cluster Display 信息
- TiUP CLuster Edit config 信息

监控(https://metricstool.pingcap.com/)
- TiDB-Overview Grafana监控
- TiDB Grafana 监控
- TiKV Grafana 监控
- PD Grafana 监控
- 对应模块日志(包含问题前后 1 小时日志)
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。