@chenwh 今天重新测试了下tikv 故障的场景
1.节点信息:3个tikv 节点, 删除其中一个节点的tikv 数据(store 7)
» store --jq=".stores[].store | { id, address, state_name,labels}"
{"id":1,"address":"172.29.238.238:20192","state_name":"Up","labels":[{"key":"host","value":"tikv1"}]}
{"id":2,"address":"172.29.238.146:20192","state_name":"Up","labels":[{"key":"host","value":"tikv2"}]}
{"id":7,"address":"192.168.134.144:20192","state_name":"up","labels":[{"key":"host","value":"tikv3"}]}
2.查看pd-leader 的日志如下: 节点挂掉之后很快会进行leader 的重新选举
[2021/07/06 16:32:17.627 +08:00] [ERROR] [heartbeat_streams.go:122] ["send keepalive message fail"] [target-store-id=94] [error=EOF]
[2021/07/06 16:32:19.502 +08:00] [INFO] [cluster.go:563] ["leader changed"] [region-id=32] [from=94] [to=1]
[2021/07/06 16:32:20.503 +08:00] [INFO] [cluster.go:563] ["leader changed"] [region-id=90] [from=94] [to=1]
3.经过max-store-down-time 时间后,节点状态变成了down。但是region count 不会减少
– 此处需要注意: 如果3个tikv 节点挂掉了一个,剩下的两个tikv 节点,不能满足3副本的隔离需求,因此在tikv 节点变成down 的状态后并不会在其他节点进行副本补充。因此此时需要先进行tikv 的扩容
4.使用api 将store 状态变成tombstone( 因为 down 的节点并不会自动变成tombstone)
curl -X POST http://192.168.134.145:2409/pd/api/v1/store/94/state?state=Tombstone
pd 中日志如下
[2021/07/06 16:55:01.636 +08:00] [WARN] [cluster.go:1093] ["store update state"] [store-id=94] [new-state=Tombstone]
根据第三点的描述,此时依然不会为缺失的region 增加副本.(在监控大盘overview-pd 下也能看到相关信息)
5.扩容tikv 节点并清理Tombstone的信息.并使用–force 强制下线tikv 节点
curl -X DELETE http://192.168.134.145:2409/pd/api/v1/stores/remove-tombstone
display 还是会显示N/A 节点信息,进行强制缩容--force
tiup cluster scale-in tidb-oooom -N 192.168.134.144:20192 --force
强制删除后新节点的监控才显示出来。。。。。
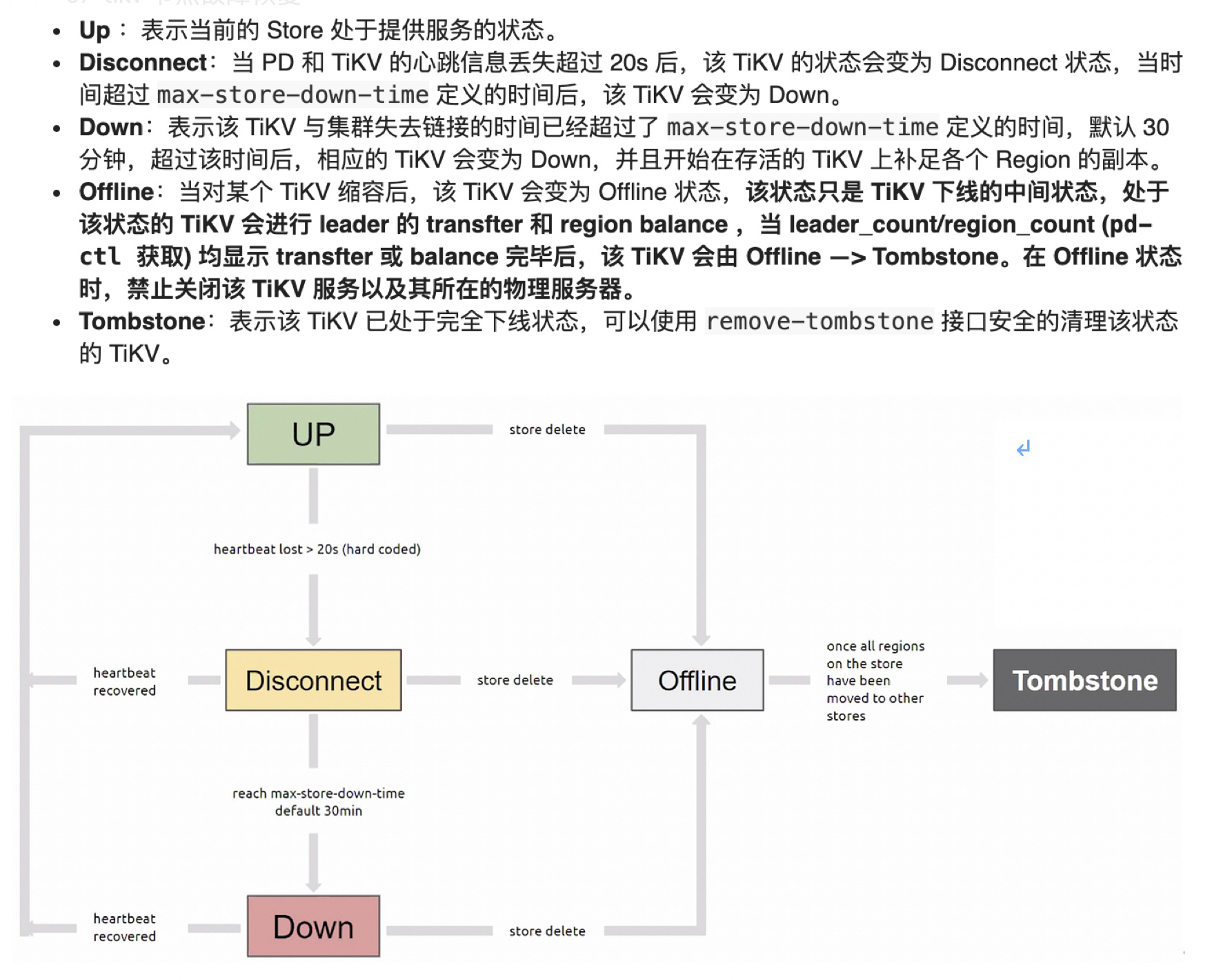
tikv 故障场景总结:
1.当对线上tikv 节点 进行scale-in 操作时, 如果tikv 剩余节点数不能满足副本的标签隔离级别,则不会进行副本的调度,节点会一直处于offline 的状态
2.当一个tikv 节点故障时, 经过max-store-down-time 后,节点变成down 的状态。
– 如果tikv 节点数不足,则不会进行region 的副本增加
– 如果tikv 节点数足够,则会进行region 副本的增加
3.对于down 的tikv 需要使用api 将tikv 节点的状态从down 改成tombstone 并使用–force 强制下线
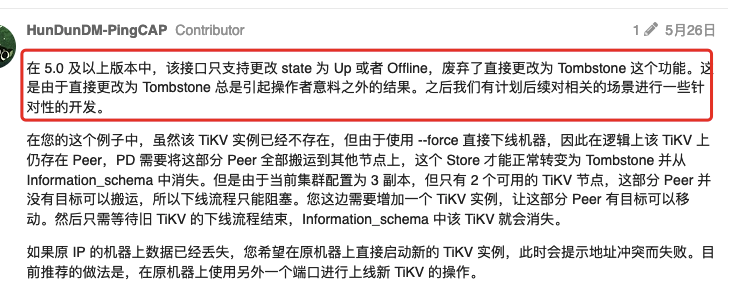
此处有个问题:
在其他帖子中看到如下描述如何删除已下线实例在information_schema中信息 - #11,来自 GangShen
请问在5.x 版本中tikv 节点异常的处理流程应该是怎样的 ?
建议能在官方文档中将tikv 节点异常的几种情况增加更多详细的说明和操作文档