tidb-v5.0.2
问题描述:
想要模拟单个tikv 节点故障后数据不可修复的整个操作流程。
操作流程可能不符合正常规范导致目前tikv 中能看到异常日志

集群部署信息:(5副本配置)

pd 中看到的信息为
» store --jq=".stores[].store | { id, address, state_name,labels}"
{"id":1,"address":"172.29.238.197:20160","state_name":"Up","labels":[{"key":"host","value":"tikv1-1"},{"key":"dc","value":"bjtx"},{"key":"zone","value":"z1"}]}
{"id":2,"address":"172.29.238.238:20160","state_name":"Offline","labels":[{"key":"host","value":"tikv2-1"},{"key":"dc","value":"bjtx"},{"key":"zone","value":"z2"}]}
{"id":3,"address":"172.29.238.146:20160","state_name":"Up","labels":[{"key":"host","value":"tikv1-2"},{"key":"dc","value":"bjtx"},{"key":"zone","value":"z1"}]}
{"id":35267,"address":"192.168.149.156:20160","state_name":"Up","labels":[{"key":"host","value":"tikv3-1"},{"key":"dc","value":"bjbd"},{"key":"zone","value":"z3"}]}
{"id":35268,"address":"192.168.149.155:20160","state_name":"Up","labels":[{"key":"host","value":"tikv4-1"},{"key":"dc","value":"bjbd"},{"key":"zone","value":"z4"}]}
{"id":35269,"address":"10.33.33.247:20160","state_name":"Up","labels":[{"key":"host","value":"tikv5-1"},{"key":"dc","value":"bjali"},{"key":"zone","value":"z5"}]}
模拟故障的操作步骤为:(172.29.238.238:20160 节点)
1.删除tikv数据目录&部署目录
2.手动kill 掉tikv 进程
3.在pd ctl中执行: store delete 2
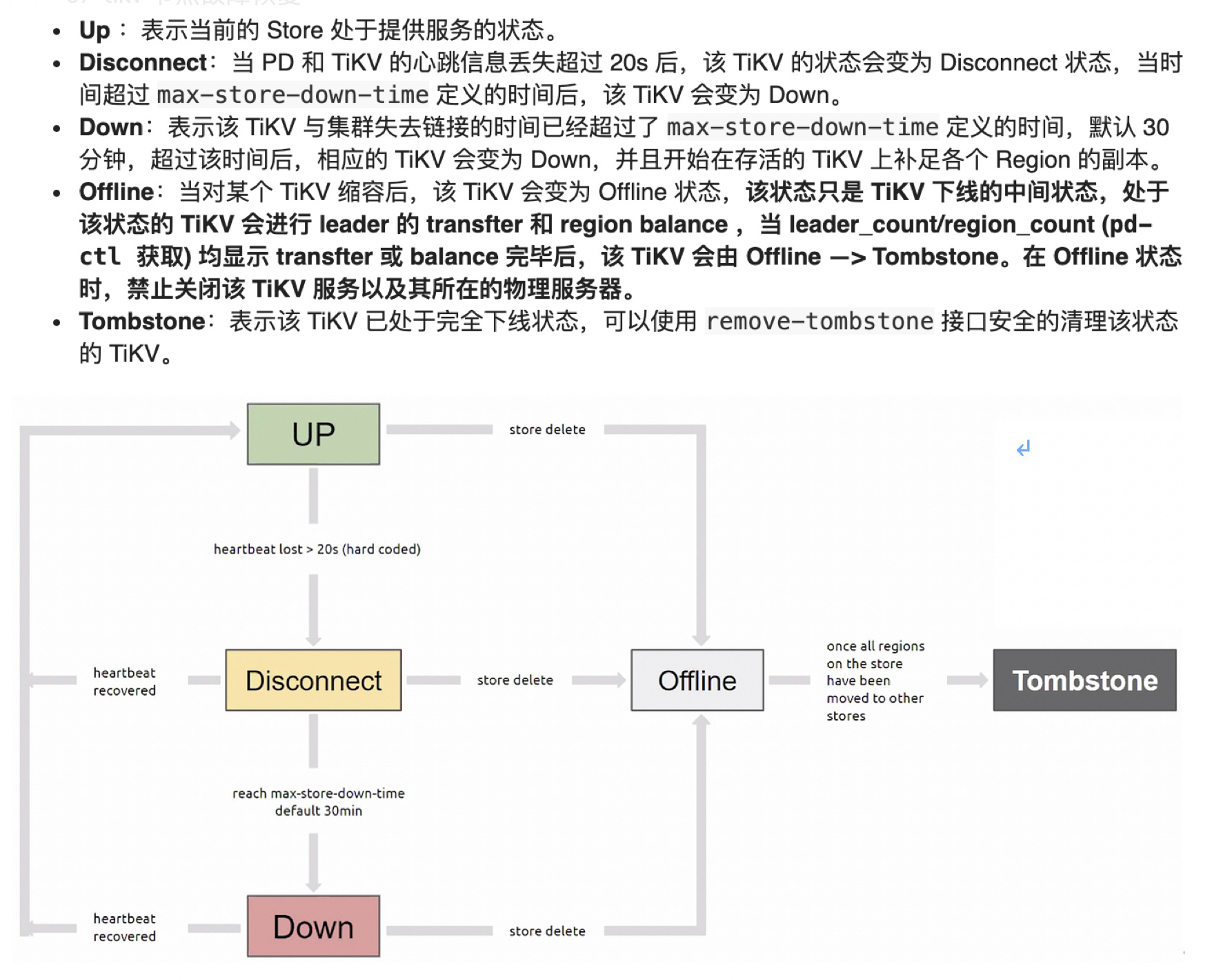
已经过了一天后故障的tikv 节点一直是处于offline 的状态
» store 2
{
"store": {
"id": 2,
"address": "172.29.238.238:20160",
"state": 1,
"labels": [
{
"key": "host",
"value": "tikv2-1"
},
{
"key": "dc",
"value": "bjtx"
},
{
"key": "zone",
"value": "z2"
}
],
"version": "5.0.1",
"status_address": "172.29.238.238:20180",
"git_hash": "e26389a278116b2f61addfa9f15ca25ecf38bc80",
"start_timestamp": 1625036503,
"deploy_path": "/data/tidb/deploy/tikv-20160/bin",
"last_heartbeat": 1625144514928999215,
"state_name": "Offline"
},
"status": {
"capacity": "0B",
"available": "0B",
"used_size": "0B",
"leader_count": 0,
"leader_weight": 1,
"leader_score": 0,
"leader_size": 0,
"region_count": 2726,
"region_weight": 1,
"region_score": 190072,
"region_size": 190072,
"start_ts": "2021-06-30T15:01:43+08:00",
"last_heartbeat_ts": "2021-07-01T21:01:54.928999215+08:00",
"uptime": "30h0m11.928999215s"
}
}
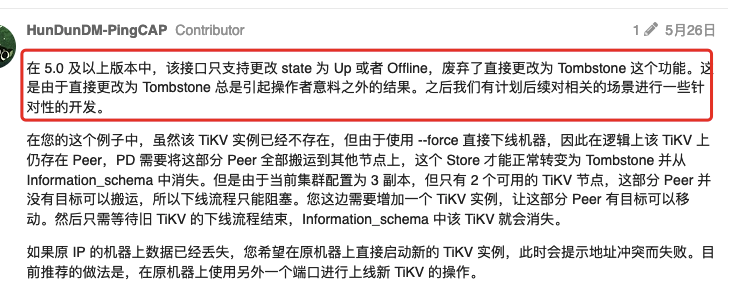
4.第二天发现状态未变成tombstone 。于是使用scale-in --force 删除了节点
目前集群状态display 显示正常,监控如下图
(目前只剩下scale-in 之后的监控大盘数据了。之前未观察被删除的tikv 的region count 是否在下降,不知道是因为副本调度太慢还是什么原因导致的tikv 一直处于offline 状态)
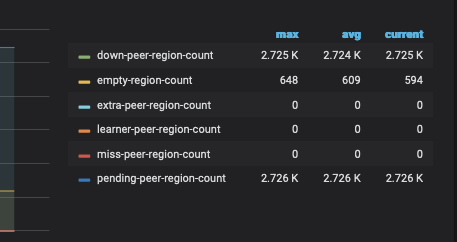

请问现在应该如何处理现在的状态,让pd 中不再显示store 2的状态