为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【概述】场景+问题概述
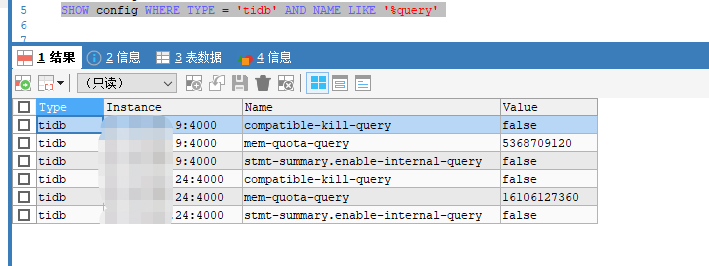
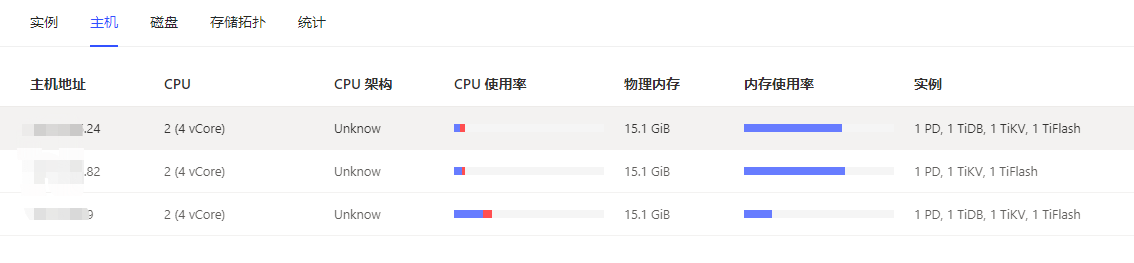
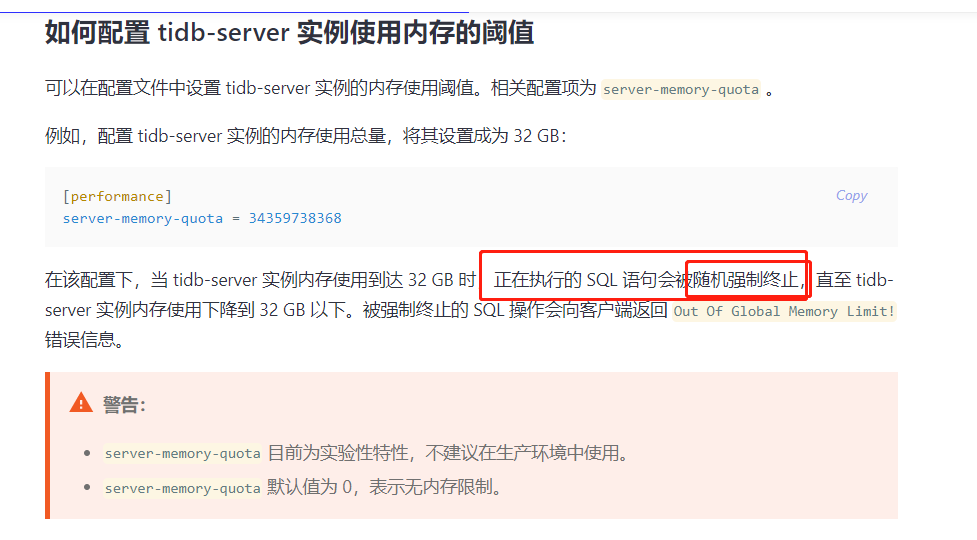
测试环境,tidb节点15G内存,设置了oom-action为cancel,performance.server-memory-quota为10个G,
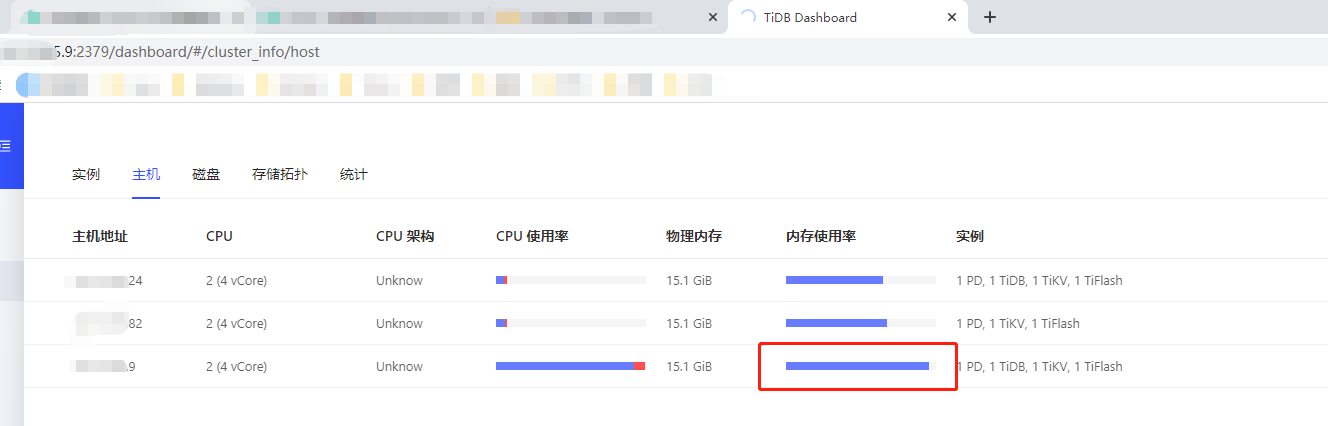
compatible-kill-query一个节点设置的5个G,一个节点设置15个G,想测下单条sql超过5G被kill掉、超过10G是performance.server-memory-quota起作用,但是发现并没有效果,在9节点执行的,跑满了15G内存,既没有被compatible-kill-query kill掉,也没有被performance.server-memory-quota kill掉,tidb节点还是挂机了
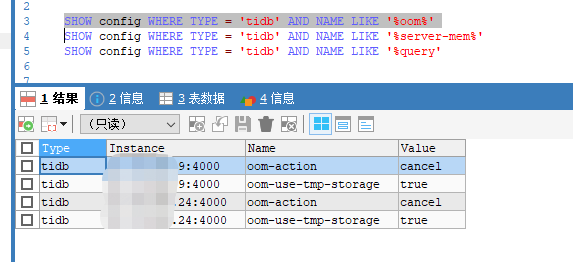
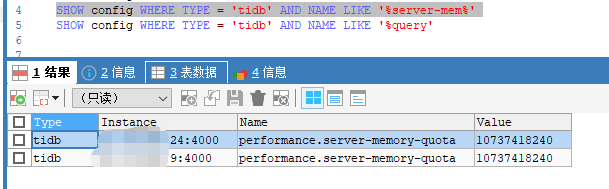
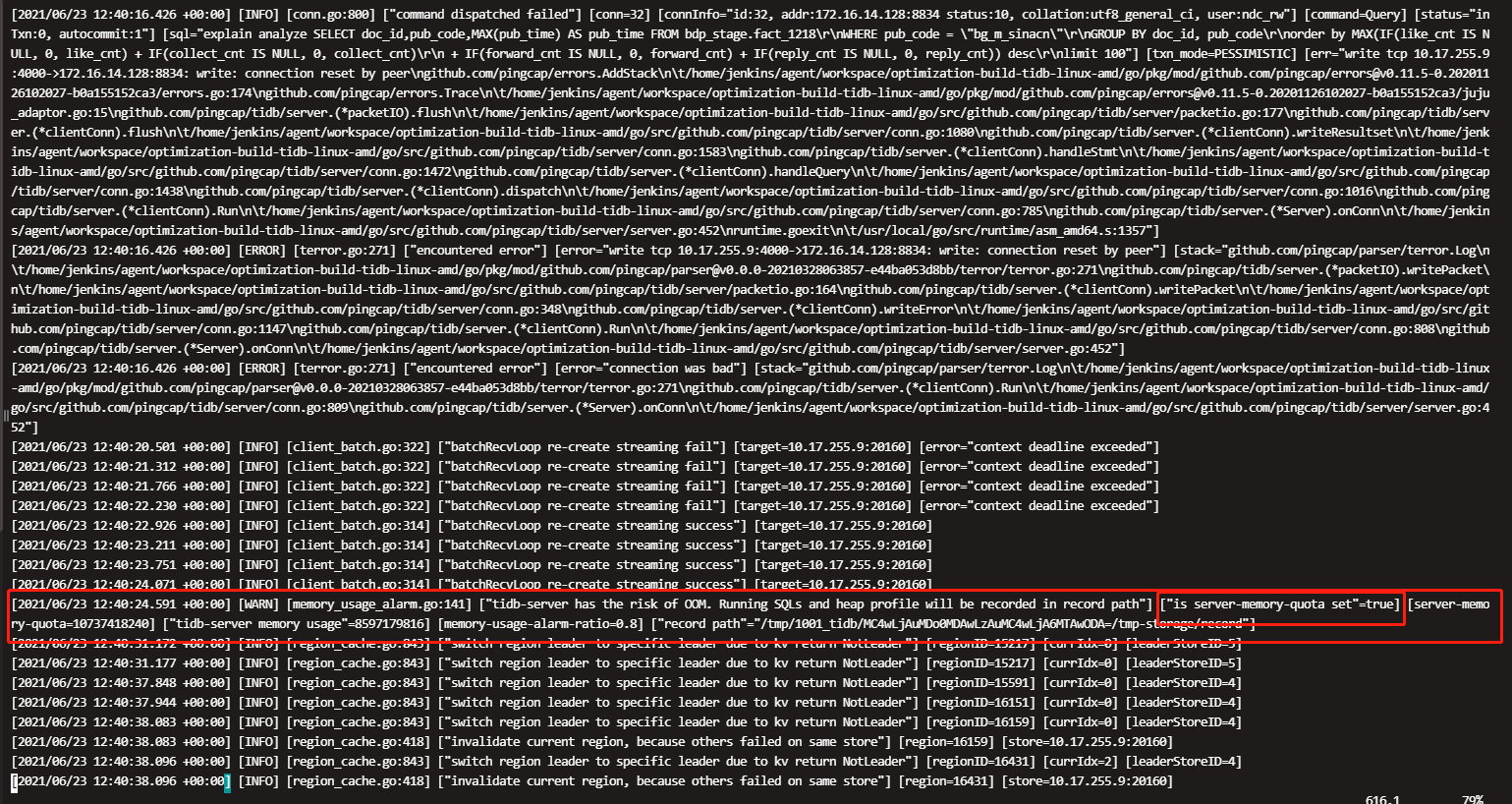
就只报了个警报:
重启:
【TiDB 版本】
V4.0.13
和这个一样,不起作用,不只是groupby,都不行。
1 个赞
yilong
(yi888long)
2
试试把 oom-use-tmp-storage 设置为 false 能否 kill ,多谢。

以改为false,并吧所有的参数全部调低,server内存只能用3G,query内存一个设置的1G,一个设置的5G,仍然不管用
最开始状态:
过程中:

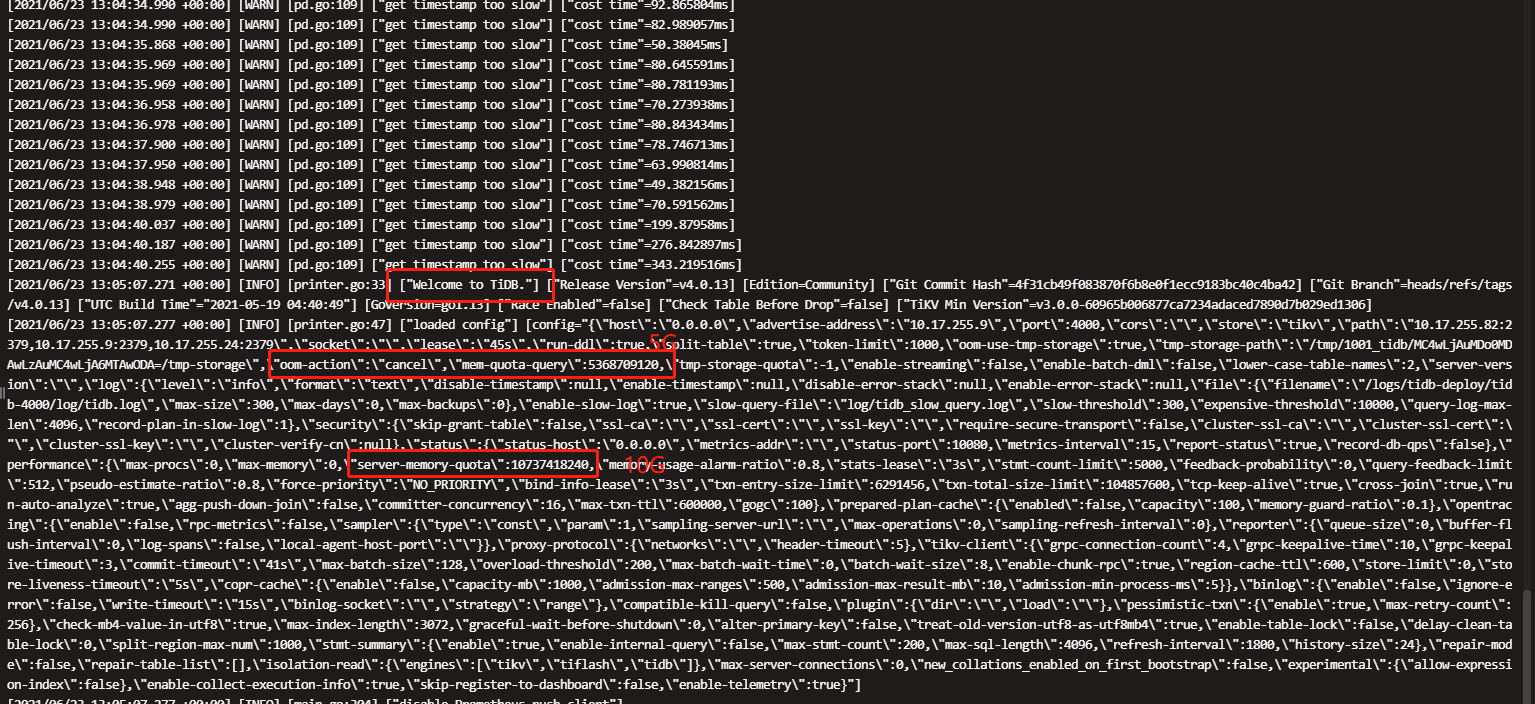
配置参数:
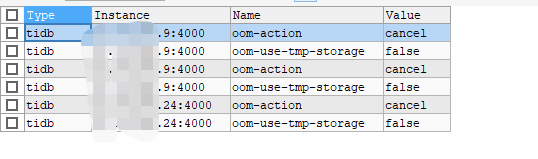


日志:
tidb (1).zip (7.0 KB)
yilong
(yi888long)
4
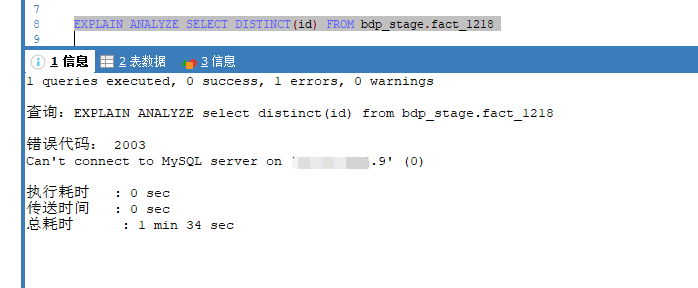
麻烦发一下你的sql 和 explain analyze sql 的结果,建表语句。
如果 explain analyze sql 无法执行成功就先不上传了。
建表语句和sql:
sub3.sql (144.3 KB)
yilong
(yi888long)
6
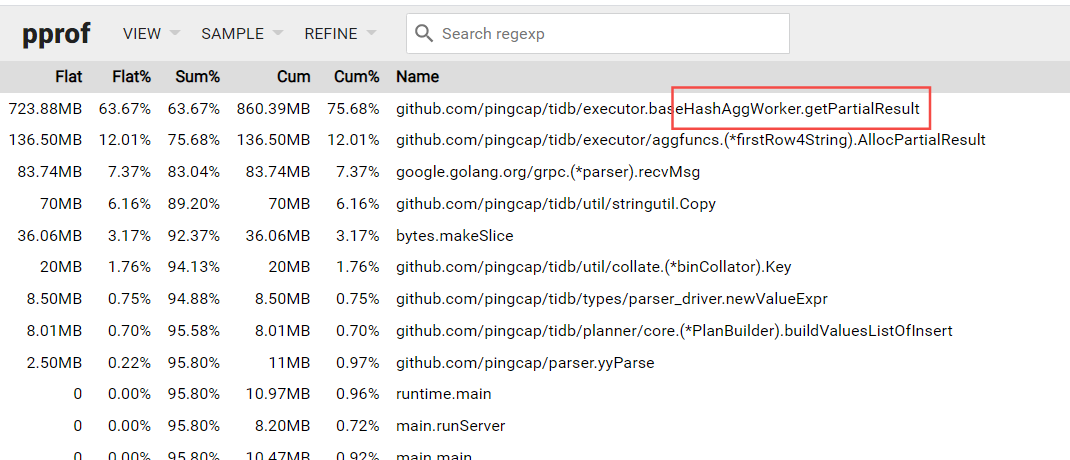
目前如果是走 hashagg 内存可能trace不上,导致无法正常 cancel.
你再执行一次这个sql,再执行过程中,采集以下profile文件。
curl -G http://{TiDBIP}:10080/debug/zip?seconds=30" > profile.zip
ip地址为tidb服务器的ip,端口为tidb_status_port的端口
profile如下:
profile.zip (155.6 KB)
1 个赞
另外即使是hashagg的trace不上,那整个tidb机器的内存使用好监控到吧,为啥没被这个规则kill掉呢