为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
上面的问题,请提供下下面的信息:
1、当前集群的拓扑,tiup cluster display {cluster_name} 即可
2、12:00 ~ 13:00 grafana 监控信息导出
1)tidb 监控
2)pd 监控
4)node-exporter 监控:tidb server ,pd leader
3)blackbox_exporter 监控:tidb → pd leader 以及 pd leader → tidb 的网络延时
使用下面的方式导出:
3、参考下面的命令抓一个 tidb server 的 debug 信息:
curl -G http://{TiDBIP}:10080/debug/zip?seconds=30" > profile.zip
收到,这里先看下,如果有消息,会及时跟帖回复 ~
另外,再确认下,如果是多 IDC 部署,前端的流量是从一个 IDC 进来的吗?换句话说,比如只有部署在 IDC 1 的 TiDB Server 承担前端的业务请求,其他 IDC 2,IDC 3 的 TiDB Server 是备份机器,没有业务流量 ~
你好,有一个问题再确认下:
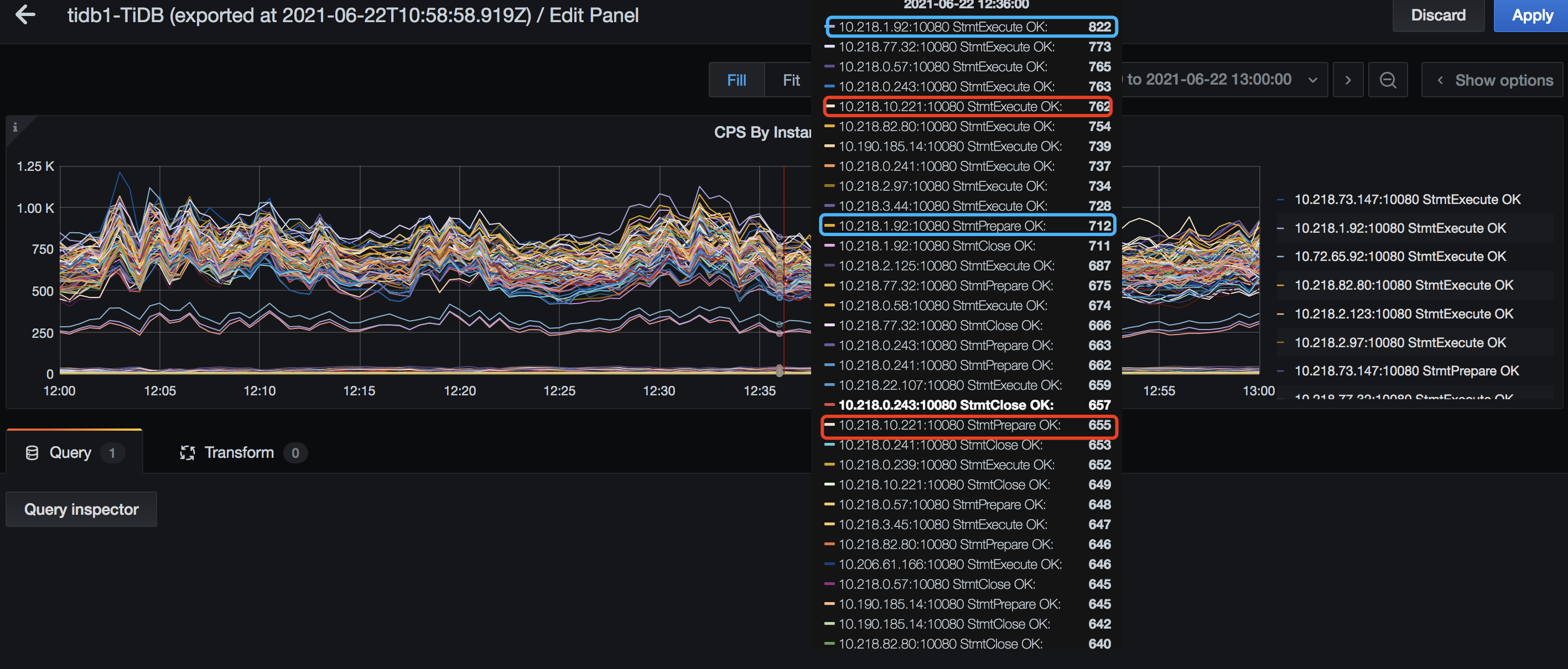
当前我们的业务代码逻辑中,有使用到 prepare stmt 吗?如果有使用到,请看下当前的代码逻辑。这边发现 TiDB Server 的监控中,同一台 TiDB Server prepare 、execute、close 的次数没有太大差异,推测可能是 prepare 一次,execute 一次,最后 close:
在现有的版本中,有一个已知问题(https://github.com/pingcap/tidb/pull/24371),在 prepare 的时候会每次生成一次 parser 对象,分配开销是比较高,有可能对这个造成影响。所以,如果 prepare stmt 业务代码调整后,辛苦再提供下下面的信息:
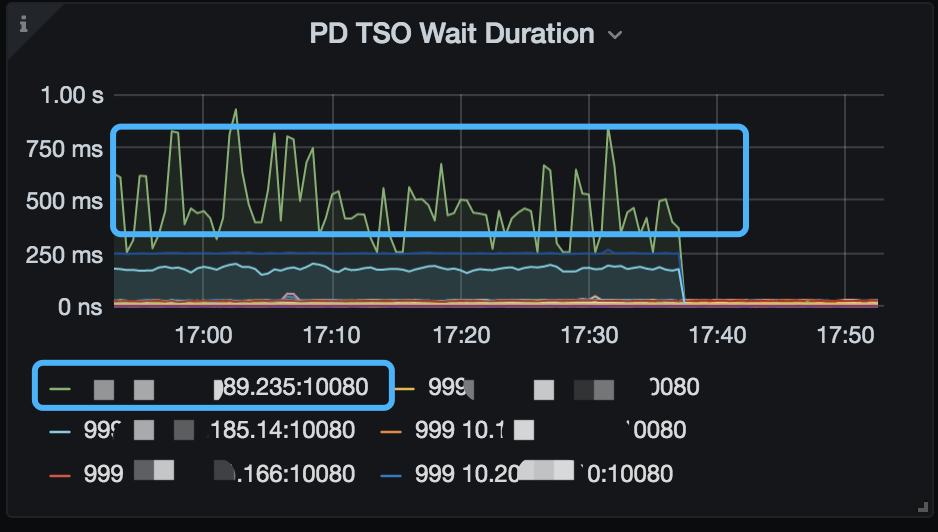
我们最终要解决的问题是 TiDB Duration 高,只是在看监控时发现 PD TSO wait duration 高的问题,然后以这个为契机进行排查吗?
如果是,那么也辛苦把这个时间段的 tikv-details 监控也导出下哈?
23 号 12:00 ~ 13:00 tidb server 的监控,下面的面板 by instance 后,看到只有一个 TiDB Server 的相关耗时比较高,该 TiDB Server 重启后,TSO 整体恢复正常:
在重启前,没有抓这个 TiDB Server 的火焰图,后面再遇到类似的问题可以在重启前抓下火焰图,我们再一起定位下问题 ~
欢迎持续关注 asktug ~
参考这里排查下
你好~这是一个已解决的旧问题,请你重新发帖提问,避免问题被掩盖哟~
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。