【概述】 DM版本v2.0.4,增量同步,压测工具sysbench
【问题】 当出现延迟后,此时停止sysbench脚本,通过query-status查询任务状态secondsBehindMaster不会变化,一直处于延时状态。信息如下:
{
“result”: true,
“msg”: “”,
“sources”: [
{
“result”: true,
“msg”: “”,
“sourceStatus”: {
“source”: “test”,
“worker”: “dm-168.16.150.18-8264”,
“result”: null,
“relayStatus”: null
},
“subTaskStatus”: [
{
“name”: “dm_benchmark”,
“stage”: “Running”,
“unit”: “Sync”,
“result”: null,
“unresolvedDDLLockID”: “”,
“sync”: {
“totalEvents”: “37301686”,
“totalTps”: “10191”,
“recentTps”: “0”,
“masterBinlog”: “(mysql-bin.002936, 167409578)”,
“masterBinlogGtid”: “eb43405a-f309-11ea-b2d3-00163e13a19d:1-561521970”,
“syncerBinlog”: “(mysql-bin.002936, 167409014)”,
“syncerBinlogGtid”: “eb43405a-f309-11ea-b2d3-00163e13a19d:1-561521968”,
“blockingDDLs”: [
],
“unresolvedGroups”: [
],
“synced”: false,
“binlogType”: “remote”,
“secondsBehindMaster”: “127”
}
}
]
}
]
}
监控截图如下:
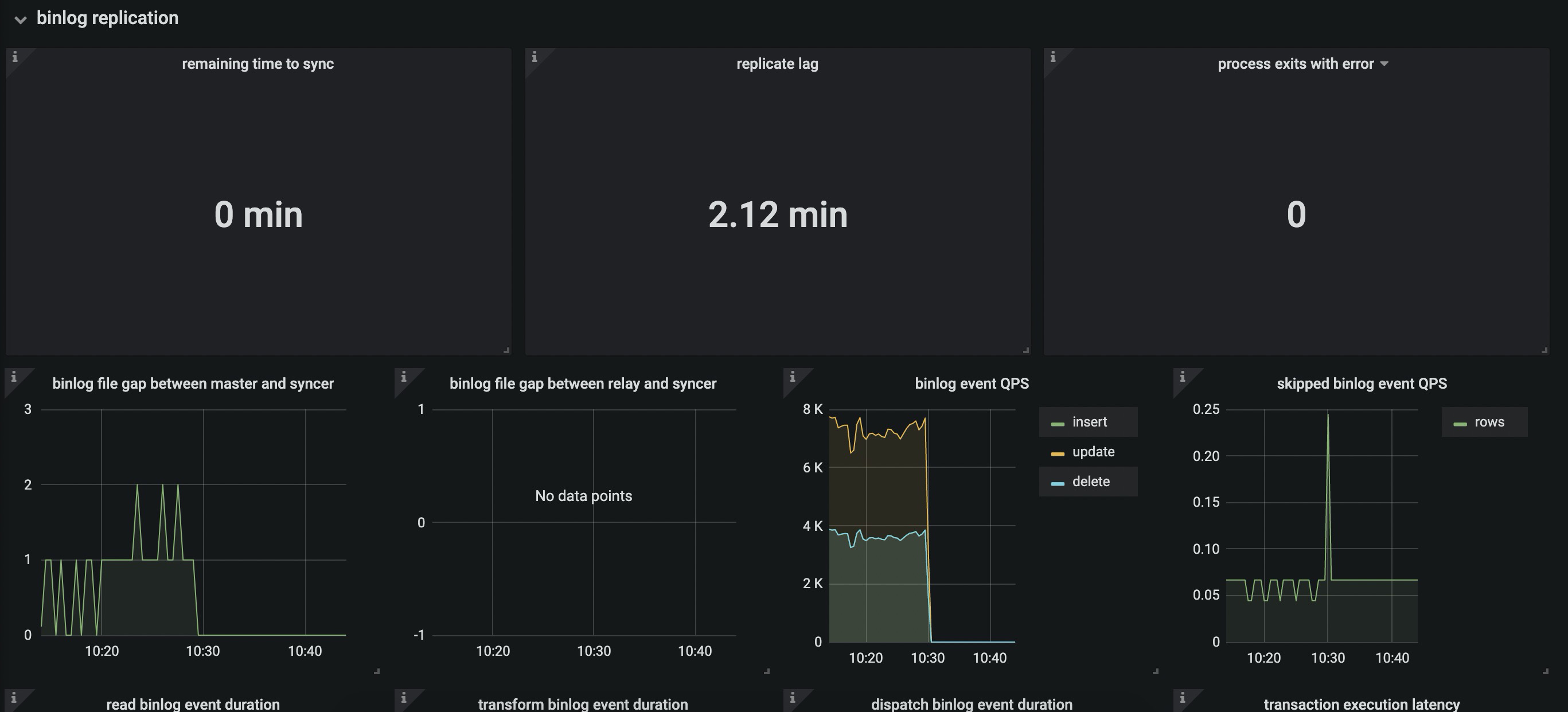
补充:当重新开始压测后,secondsBehindMaster的值恢复正常
压测脚本:sysbench /usr/share/sysbench/oltp_write_only.lua --tables=4 --threads=64 --mysql-host=xxx --mysql-port=3306 --mysql-user=xxx --mysql-password=xxx --mysql-db=dm_benchmark --db-driver=mysql --report-interval=10 --time=720000 run
任务配置:
********* 任务信息配置 *********
name: dm_benchmark # 任务名称,需要全局唯一
task-mode: incremental # incremental
online-ddl-scheme: “gh-ost”
******** 数据源配置 **********
mysql-instances:
- source-id: “test”
block-allow-list: “rule-1”
meta:
binlog-gtid: “eb43405a-f309-11ea-b2d3-00163e13a19d:1-18955826”
mydumper-config-name: “global”
loader-config-name: “global”
syncer-config-name: “global”
******** 目标 TiDB 配置 **********
target-database: # 目标 TiDB 配置
host: “xxx”
port: xx
user: “root”
password: “” # 如果密码不为空,则推荐使用经过 dmctl 加密的密文
block-allow-list: # 如果 DM 版本早于 v2.0.0-beta.2 则使用 black-white-list。
rule-1:
do-dbs: [“dm_benchmark”] # 非 ~ 字符开头,表示规则是通配符;v1.0.5 及后续版本支持通配
# do-tables:
# - db-name: “dm_benchmark”
# tbl-name: “sbtest1”
mydumpers:
global:
threads: 16
# chunk-filesize: 8
rows: 10000
skip-tz-utc: true
extra-args: “”
loaders:
global:
pool-size: 16
dir: “./dumped_data”
syncers:
global:
worker-count: 32
batch: 100
safe-mode: true
@Hacker_HdbFy82e
能手动改一下 grafana 的图表类型为 graph 么? 然后看看这个指标是不是在停止压测脚本之后就没动过了
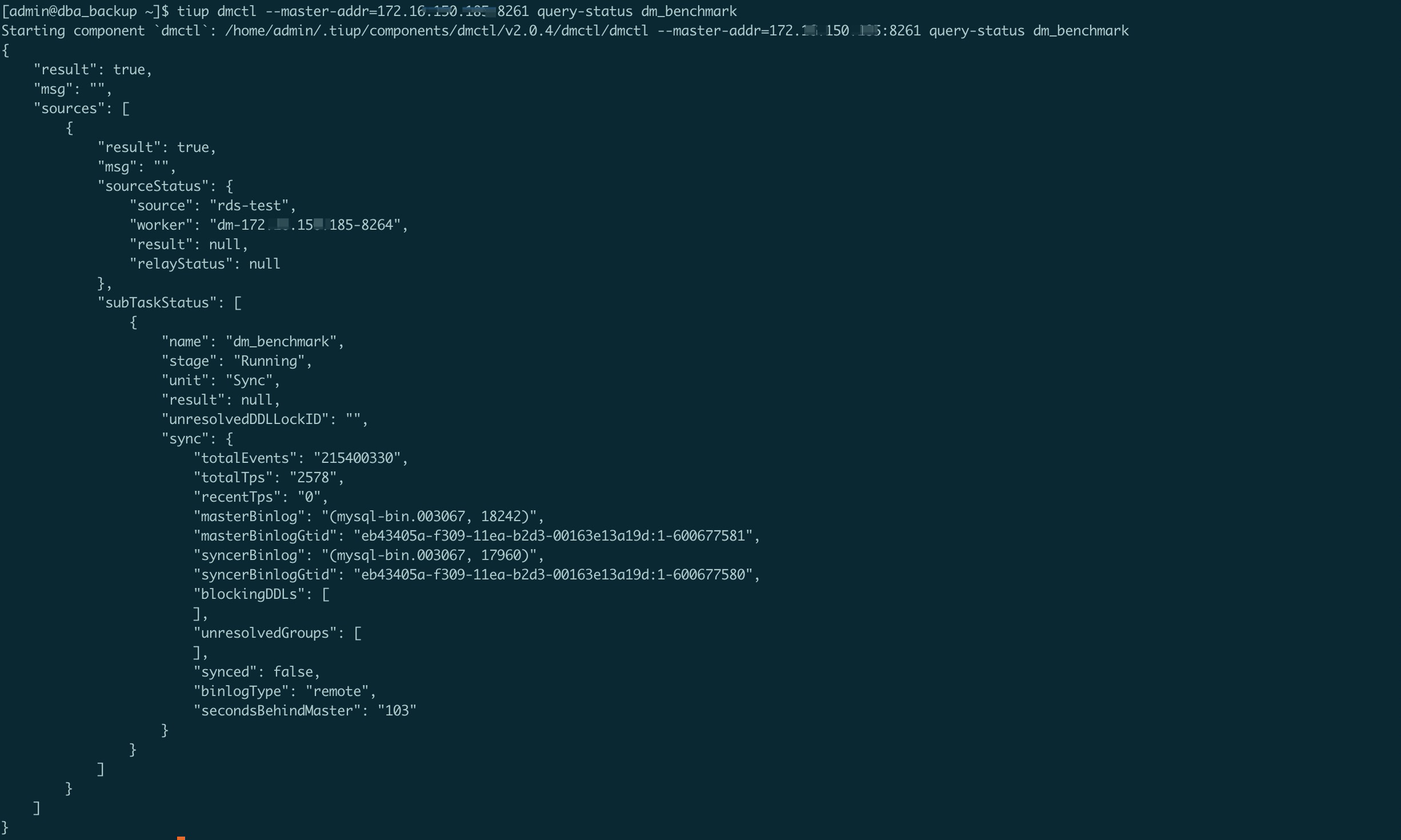
我这里尝试复现了一下 没复现出来,压测任务结束后,worker 跑一段时间后,lag 会重新变成 0
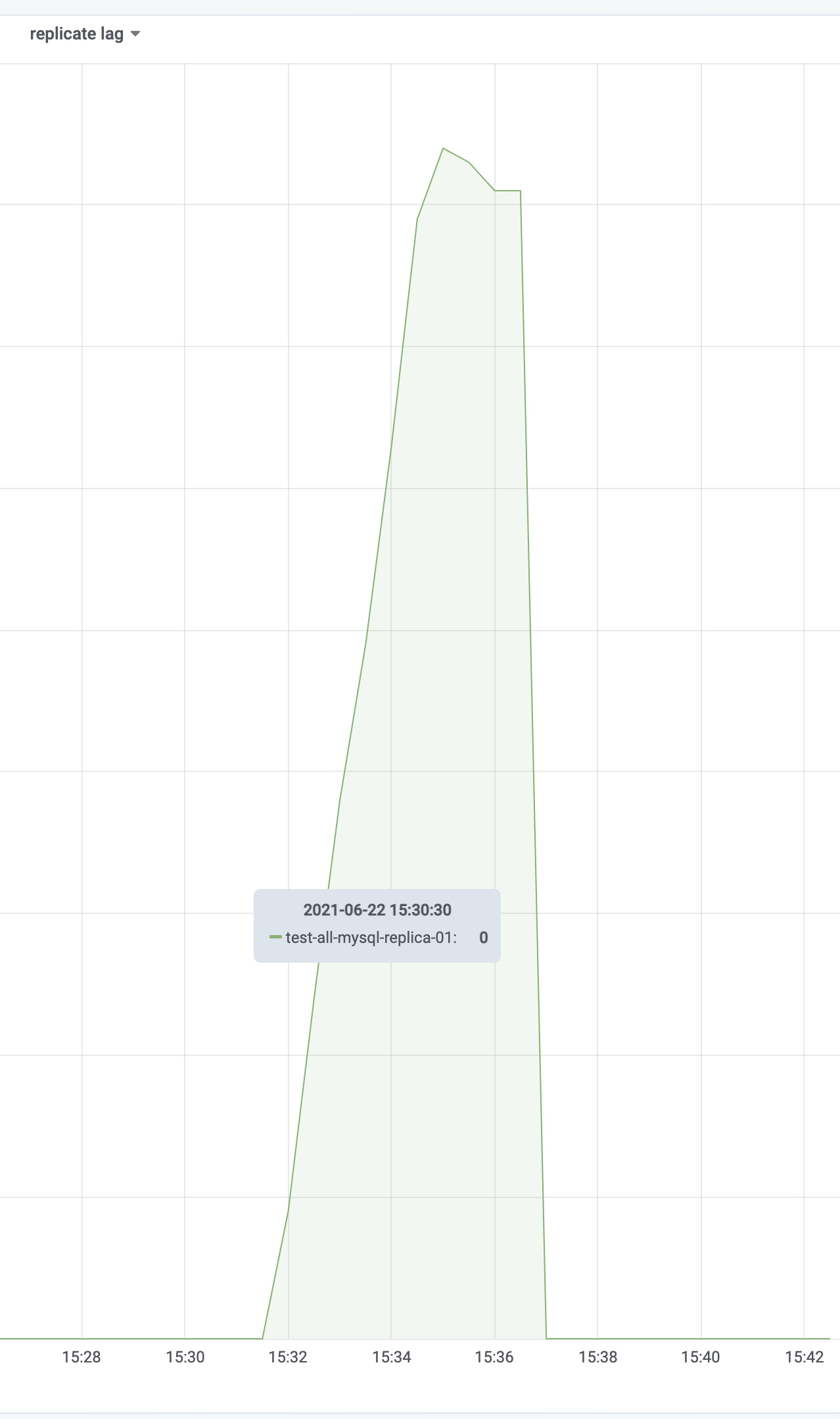
不要等结束,有延迟后,压测脚本直接手动退出
我就是有延迟后直接停止压测脚本的
你停止压测脚本之后,过了多久再去query-status的?
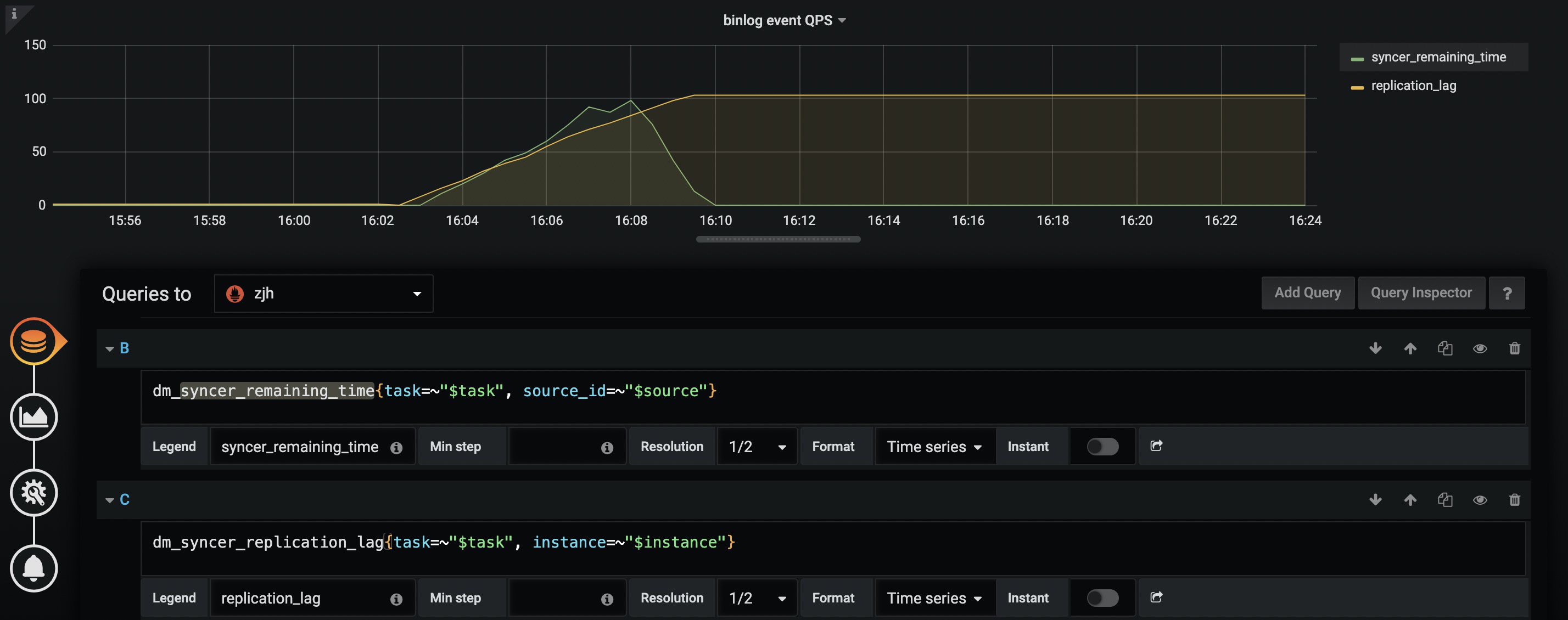
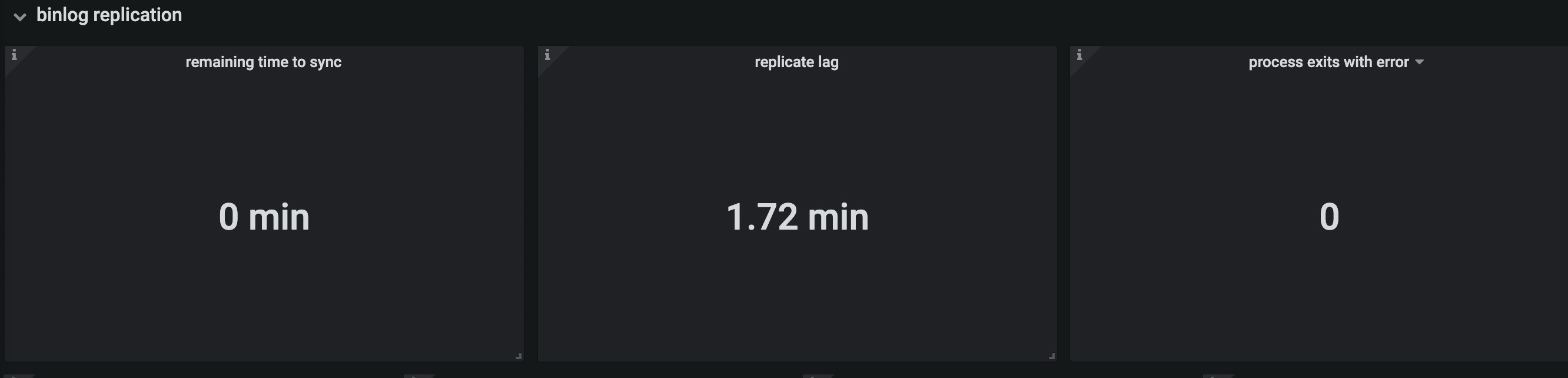
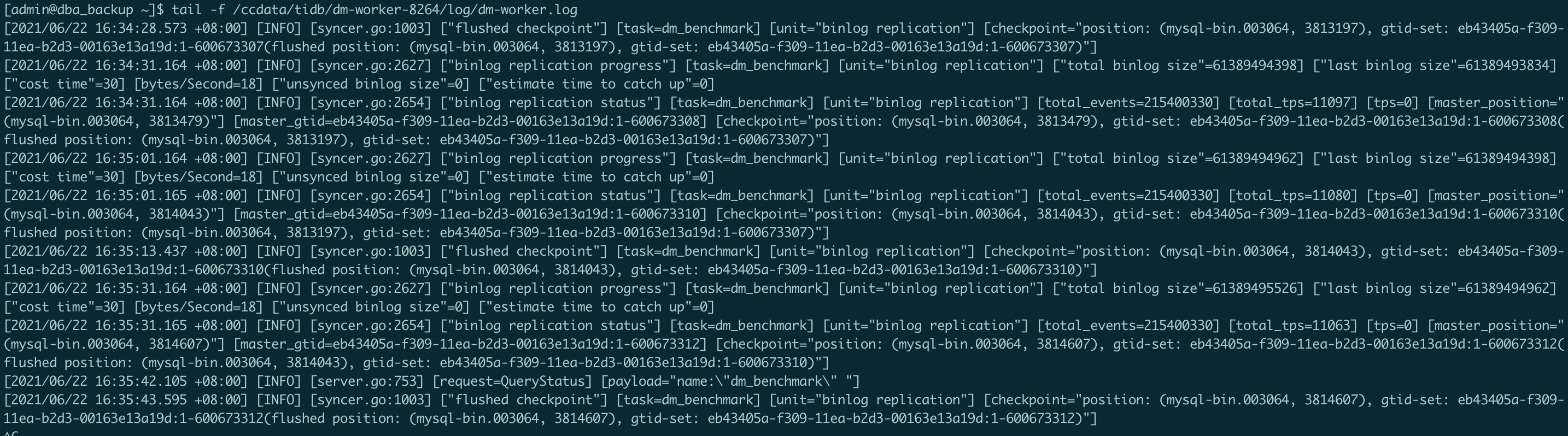
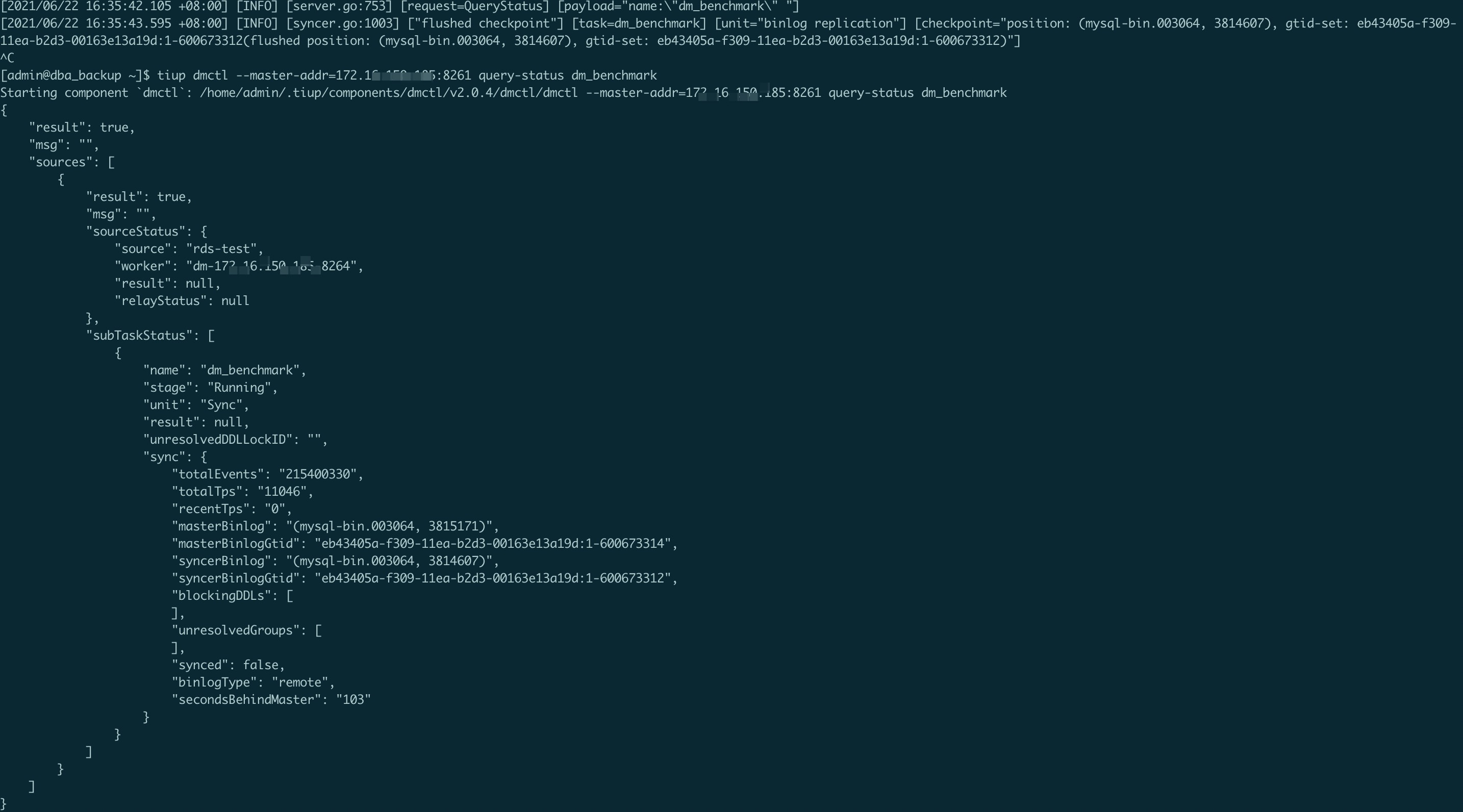
上游gtid一直有变化的,只不过不是同步库上的事物,query-status看masterBinlogGtid和syncerBinlogGtid也在变化,就是secondsBehindMaster一直没变
目前 DM 会依赖这个时间间隔去更新延迟数据,最坏的情况下应该 60s 之后会更新一次
请问你之前复现之后发现延迟指标一直不更新,这个时间段持续了多久呢?
我这里一直都还没复现出…
能提供一下 dm-worker 的日志么
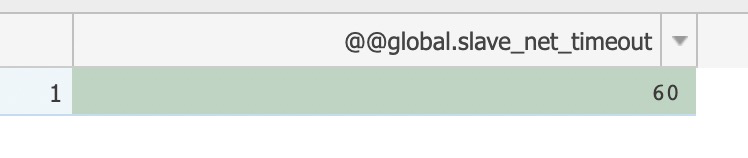
我看上游你用的是阿里云的 rds?
我稍微有点怀疑是上游没发心跳包过来

方便的话能在日志里搜索有没有这个关键词么 meet heartbeat event and then flush jobs
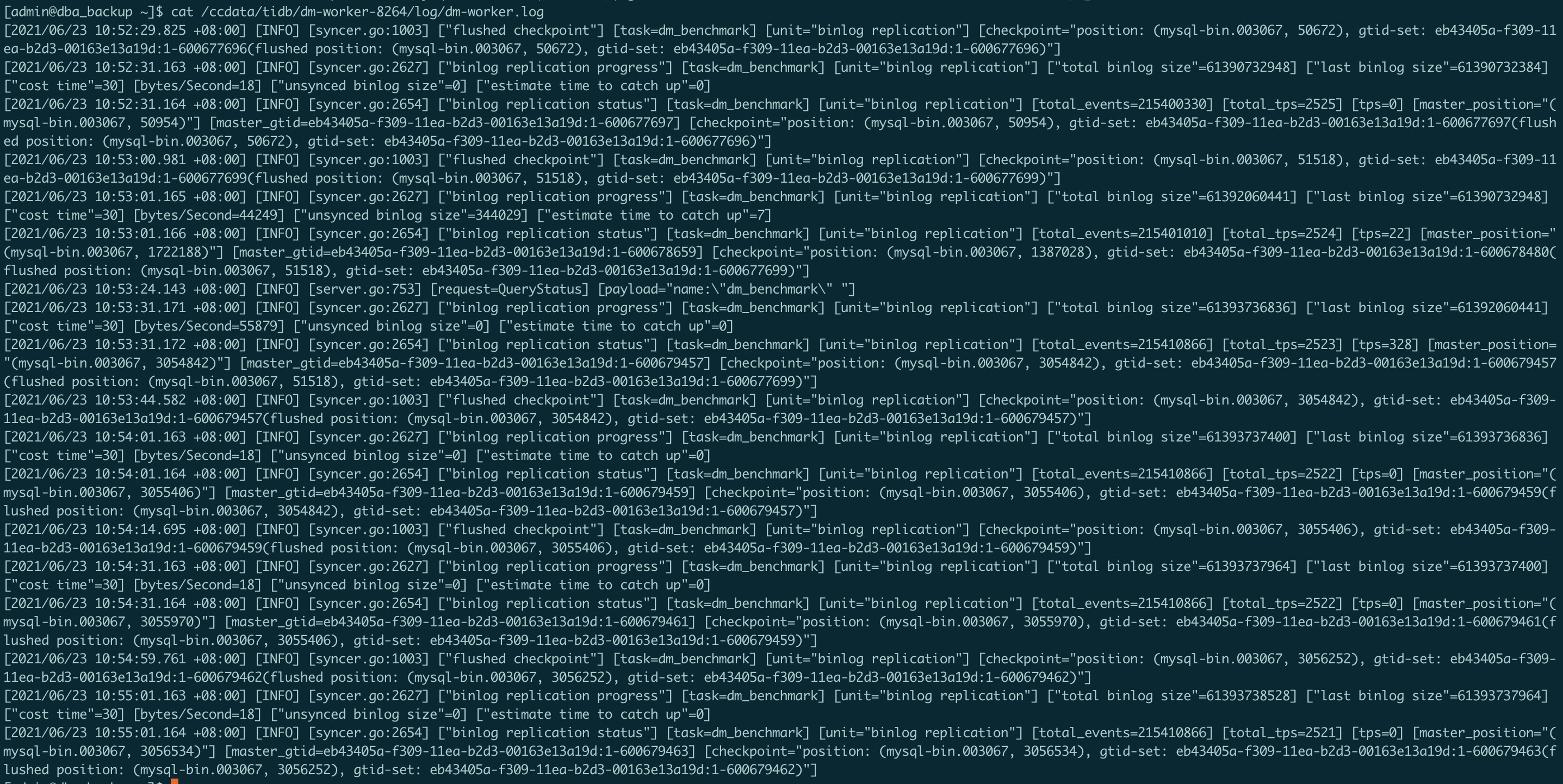

感谢,我研究一下日志,
重新开始压延迟数据恢复正常是符合预期的,因为延迟计算的大概原理是在每条 sql 执行到下游之后会重新计算
通过日志定位到问题了,的确是没收到 rds 的心跳包导致的,
我们想想办法看看能不能绕开这个限制,另外该问题关联到这个 issue 里了,
https://github.com/pingcap/dm/issues/1798
之后的修复和进度都会同步在这里,有需要的可以关注一下
好的,多谢