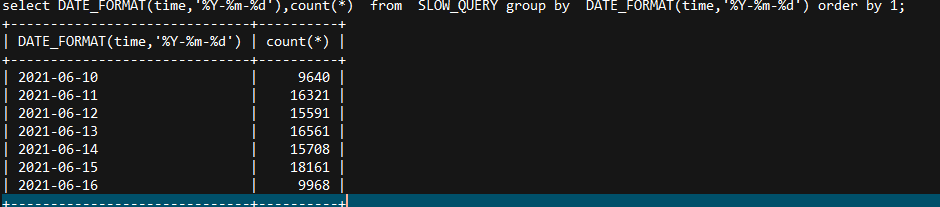
tidb版本v4.0.4
CLUSTER_SLOW_QUERY表是基于什么样的考虑,这个表没有主键索引?
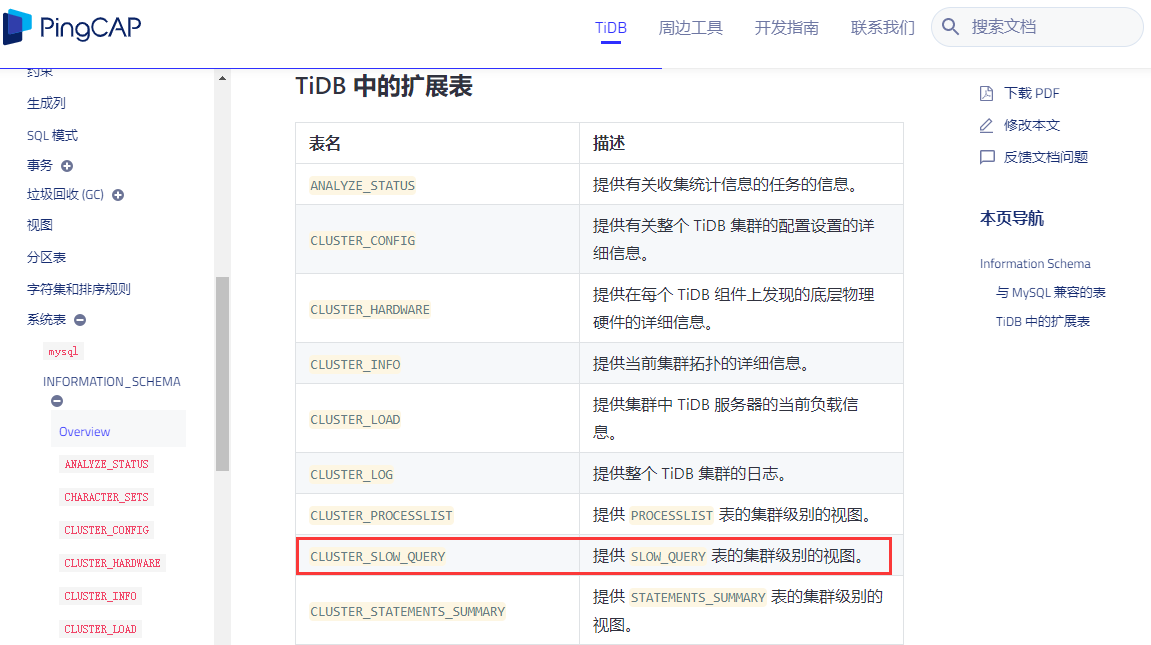
CLUSTER_SLOW_QUERY 提供 SLOW_QUERY 表的集群级别的视图。
CLUSTER_SLOW_QUERY不是视图吧,它只是一个表,而且文档中我也看了,没有说明为啥这个表没有用到索引。
另外,这个应该可以解释没有用到索引的疑问
这有点扯啊~~~怎么看也不是视图
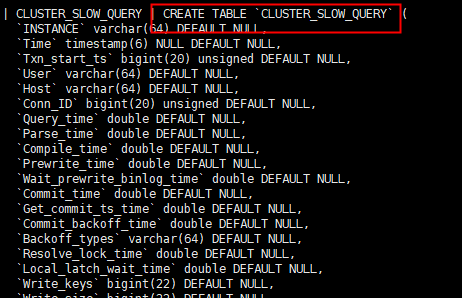
会不会是因为正常的集群,慢sql都不会很多,所以才会没有主键、索引![]()
应该只是形象化的描述,并不是说他真的是个视图~
原来我们是非正常集群。。。/笑哭~
还别说,我们生产的集群现在没有接入业务,都只是通过dm同步业务数据到tidb,然后用来出报表,很多sql跑起来都是几分钟,特别难受。
另外,还有一个问题,这个表我感觉应该是有定时清理策略的?
当一个slow.log文件达到300M的时候,会改名备份,这个过程中,相当于这部分数据就从表中删除了吗?
我理解的是没有删除,只是相当于做了分表。 查询慢可以考虑用TiFlash,速度飞起
我查了一下我们这边其中一个节点的,是保留了近一个月的。
最后两个个问题,
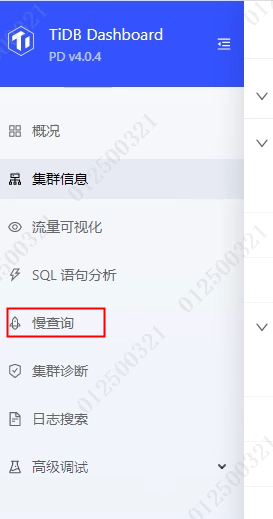
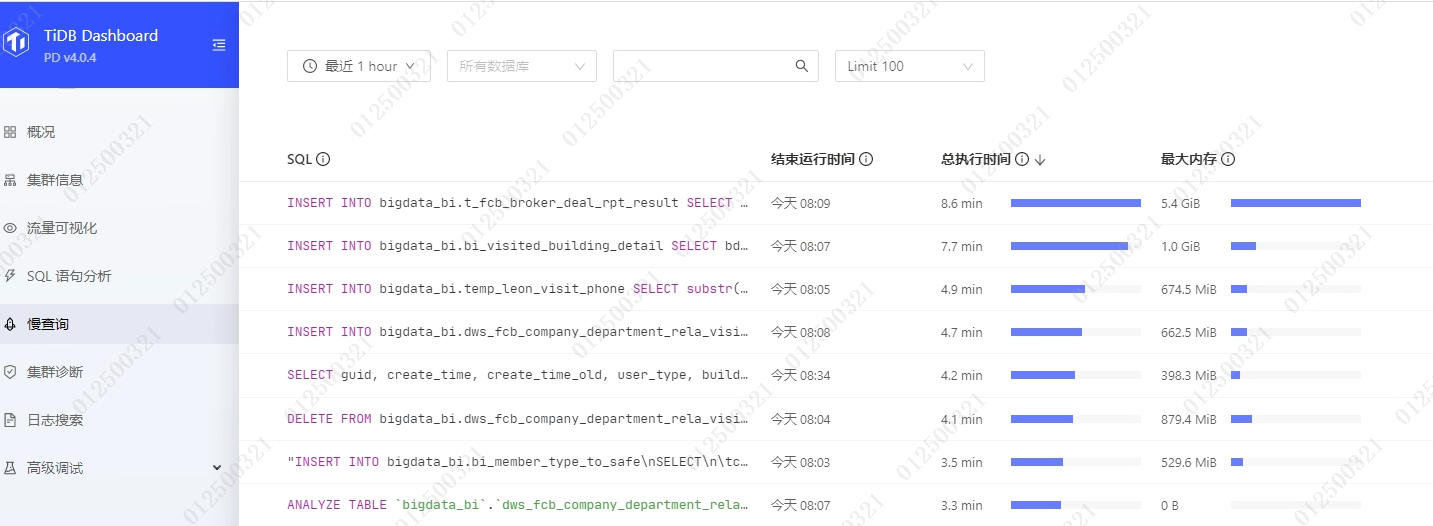
1、针对dashboard上的慢查询菜单,对应的sql是怎么样的?能提供下吗
1、参考大神主题
2、没看明白
1,这个帖子我昨天看过了,里面的sql在我们集群15分钟都跑不出来,所以我很纠结这个问题,想知道dashboard上的“慢查询”是用的什么语句,因为平时这个菜单点击后是可以查出慢sql的,比如
这个是我自己整理的
SELECT
Time,REPLACE(Query,’ ‘,’’),Query,
case when Query_time < 1 then CONCAT(ROUND(Query_time*1000,1),‘ms’)
when Query_time < 60 then CONCAT(ROUND(Query_time,1),‘s’)
when Query_time < 3600 then CONCAT(ROUND(Query_time/60,1),‘min’) end Query_time,
case when Mem_max < 1024 then CONCAT(Mem_max,‘B’)
when Mem_max < 1048576 then CONCAT(ROUND(Mem_max/1024,1),‘KiB’)
when Mem_max < 1073741824 then CONCAT(ROUND(Mem_max/1048576,1),‘MiB’)
when Mem_max < 1099511627776 then
CONCAT(ROUND(Mem_max/1073741824,1),‘GiB’) end Mem_max
FROM INFORMATION_SCHEMA.CLUSTER_SLOW_QUERY
WHERE time BETWEEN ‘2021-05-22 16:26:00’ AND ‘2021-05-22 17:00:00’
ORDER BY Query_time DESC
LIMIT 1000;
多谢哈
![]()
![]()
![]()
我们这边大部分采用的是最小集群部署方案,即三台服务器,每台服务器同时部署TiDB\PD\Tikv,数据量单表不过亿,目前没有出现你说的这种情况。很好奇你们那边的服务器情况。