【概述】场景+问题概述
1.场景描述:公司有一套tidb v5.0.1的环境(3pd+3tikv+tiflash)在云服务器上,现在想将其迁移到本地机房,云服务器与本地机房通过一条云专线连接,为了防止云专线带宽被挤爆,迁移期间不允许tidb的读写流量流入到本地机房tikv,我们采用的是同城多数据中心的方法将云服务器与本地机房当做两个数据中心,通过对tikv和pd添加labels标签的方法进行隔离。
2.问题描述:
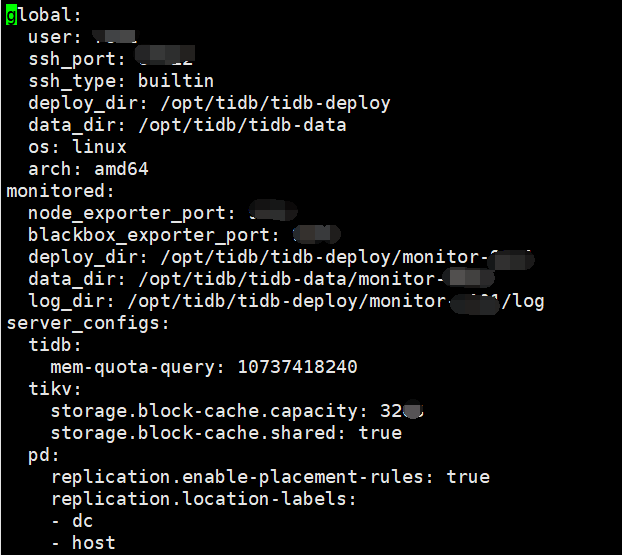
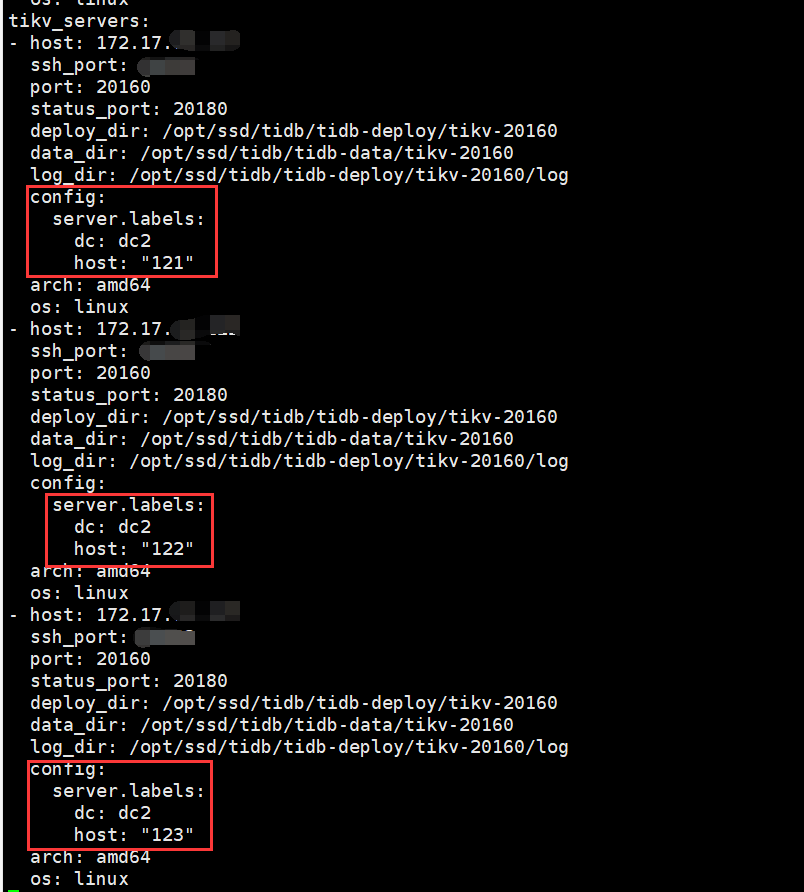
1)通过tiup cluster edit-config 命令对tikv打标签(此步骤正常);
server_configs:
pd:
replication.location-labels: [“dc”,“host”]
tikv_servers:
-host: 172.17.x.x
config:
server.labels: { dc: “d2”, host: “10” }
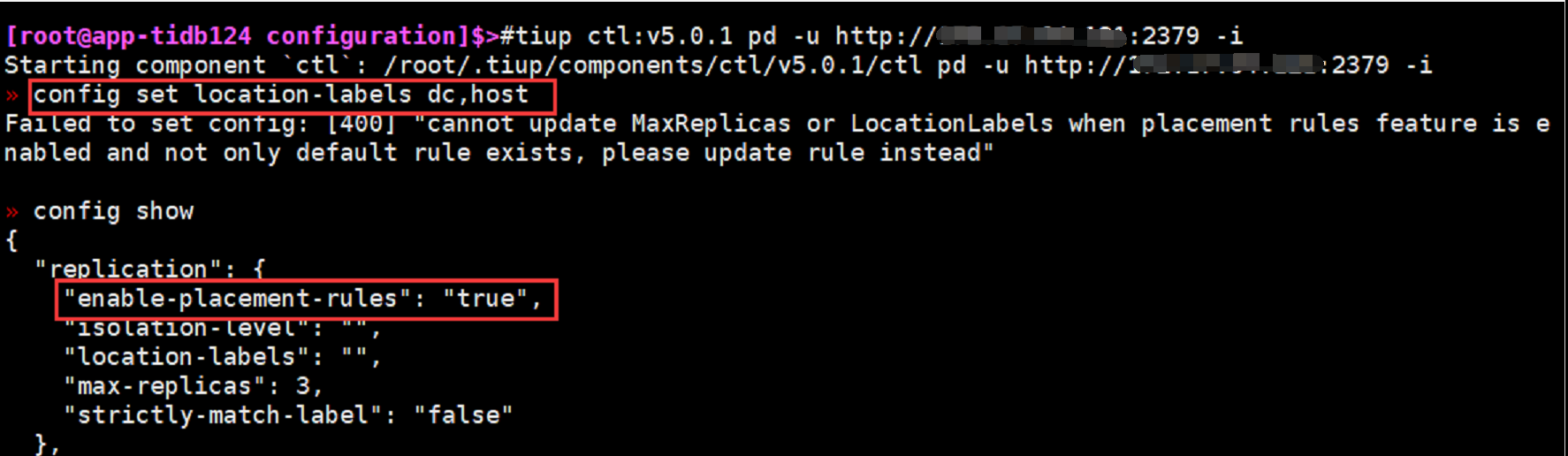
2)通过 pd-ctl config set location-labels dc,host 设置 PD 的 location-labels (此步骤异常)
我在论坛找到一篇帖子:
在原实例上进行TiKV扩容的问题 - #3,来自 qwjcool
该帖子上说需要设置config set enable-placement-rules false,但是我在设置的时候出现“cannot disable placement rules with TiFlash nodes”问题,请问这该怎么解决?
1 个赞
根据您的建议,我的理解是:
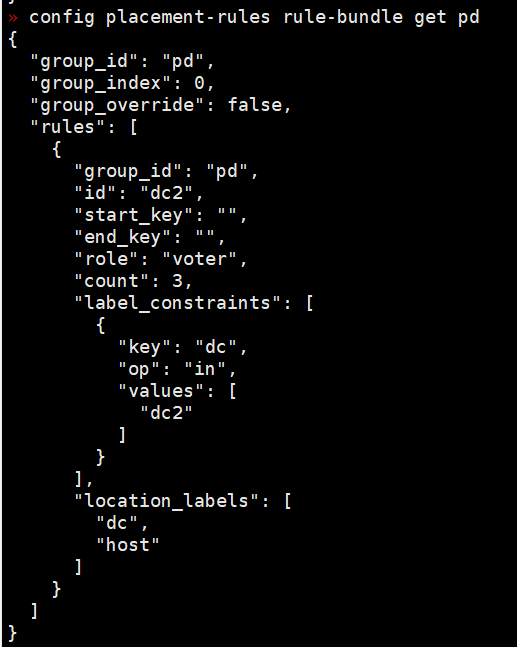
1、创建规则文件rule.json
{
“group_id”: “pd”,
“group_index”: 0,
“group_override”: false,
“rules”: [
{
“group_id”: “pd”,
“id”: “dc2”,
“start_key”: “”,
“end_key”: “”,
“role”: “voter”,
“count”: 3,
“label_constraints”: [
{“key”: “dc”, “op”: “in”, “values”: [“dc2”]}
],
“location_labels”: [“dc”, “host”]
},
{
“group_id”: “pd”,
“id”: “dc1”,
“start_key”: “”,
“end_key”: “”,
“role”: “follower”,
“count”: 3,
“label_constraints”: [
{“key”: “dc”, “op”: “in”, “values”: [“dc1”]}
],
“location_labels”: [“dc”, “host”]
}
]
}
2、使用rule-bundle添加规则
pd-ctl config placement-rules rule-bundle set pd --in=“rule.json”
请问我的理解是否正确?
另外我还有两点没搞明白,
a)我用tiup cluster edit-config 命令将6个tikv节点分别标注了dc1、dc2,而6个pd节点并没有打标签,如何防止本地机房的pd将流量转到云服务器tikv上面呢?
b) config set label-property reject-leader LabelName labelValue驱逐leader与 上面json文件中的"role": "follower"有什么区别?
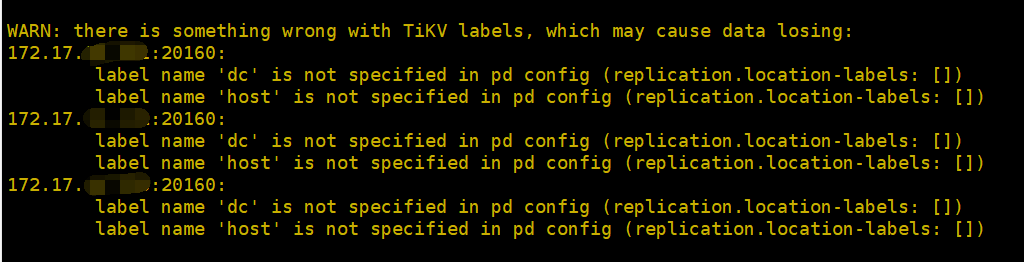
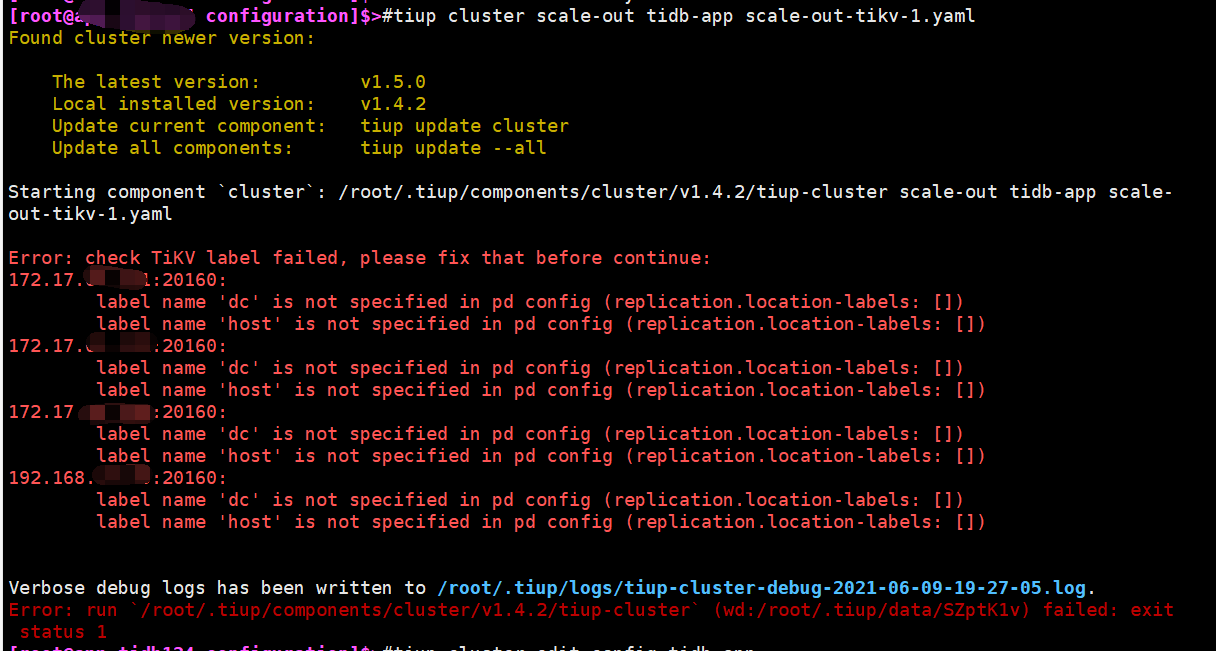
您好,我给tikv和pd打完标签后运行tiup cluster display tidb-xxx报错:
不能进行扩容操作,我在扩容一台tikv时报错如下:
我的操作步骤如下:
1)通过tiup cluster edit-config 命令对tikv打标签
2)更改Placement Rules配置文件规则
QBin
(Bin)
6
请问一下对于原来的 store 通过 edit-config 打标签之后有没有 reload 呢?
reload过了:
tiup cluster reload cluster-name -R pd
tiup cluster reload cluster-name -R tikv
tiup cluster reload cluster-name -R tidb
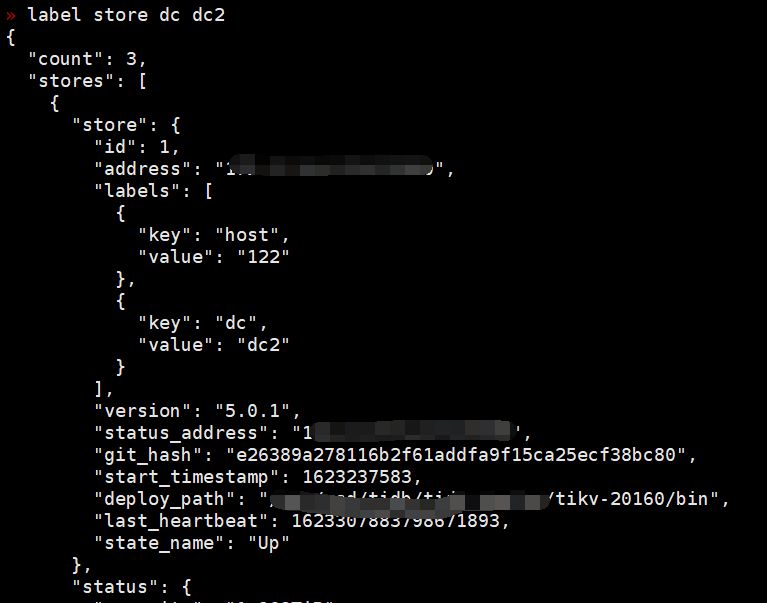
您好,我用label store dc dc2命令看了,都已经打上标签了:
QBin
(Bin)
10
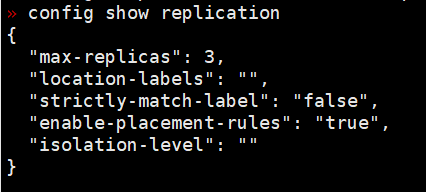
pd-ctl config show replication 的结果也看看。
QBin
(Bin)
12
看起来是 tiup 的一个已知的 label 的判断的 bug 。应该是 1.4.4 fix 的。建议先升级 tiup 再尝试。具体 fix 的 pr:
https://github.com/pingcap/tiup/pull/1378
QBin
(Bin)
14
升级到 1.5.0 吧。1.4.4 之后才 fix 的这个问题。
您好,
按照您提供的方法已经解决label问题,非常感谢。有一个新的问题需要再咨询下:
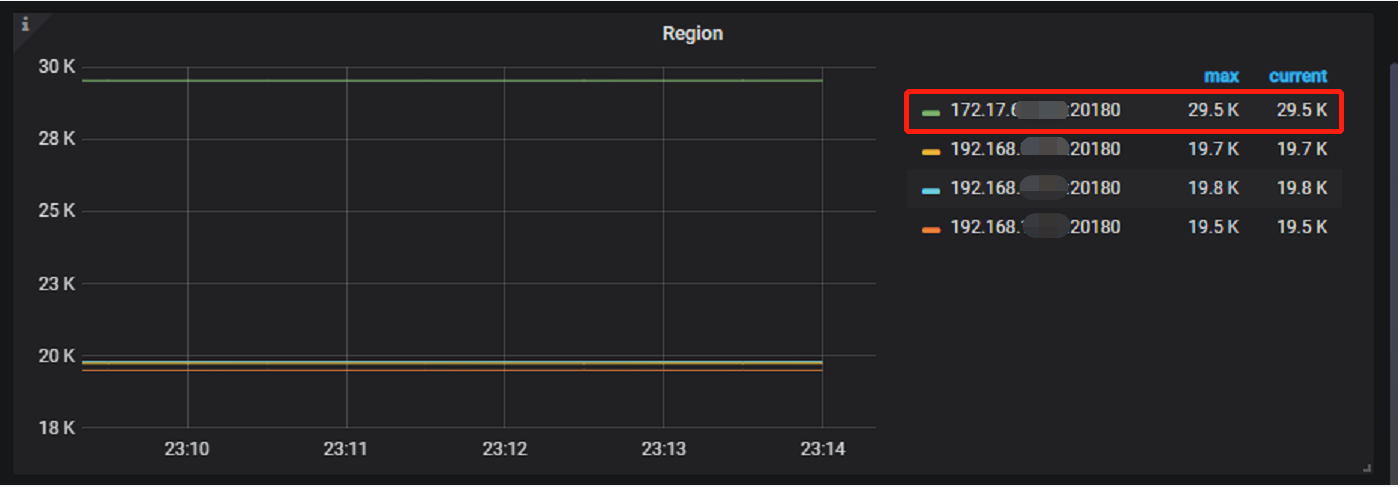
PD leader和Region leader已经切换到本地机房服务器,云服务器上有3台tikv节点,使用tiup cluster scale-in --node xx.xx.xx.xx:20160命令已经正常缩容了2台tikv,但是使用该命令在缩容第3台tikv节点时发现服务器长时间没有数据迁移的流量产生,观察监控里面的region也没有变化,于是加了个–force参数强制下线了,请问这对现有的集群有什么影响?
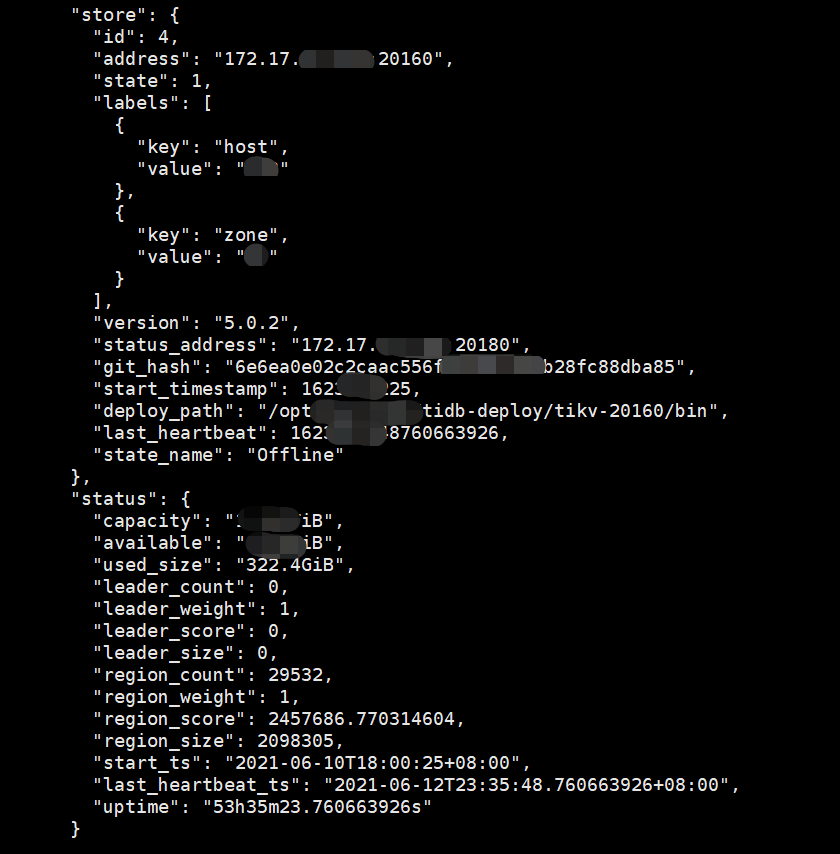
用pd-ctl store查看到该节点的store还存在,是否需要使用store delete 4删除该节点的store呢?从中还看到有29532个region没有迁移到本地机房的tikv上,这是否意味着本地机房中再有一台tikv挂掉整个集群都会挂掉?这些丢失的region应该怎么在本地机房的tikv节点上补齐呢?
1 个赞
问题解决了,自问自答:
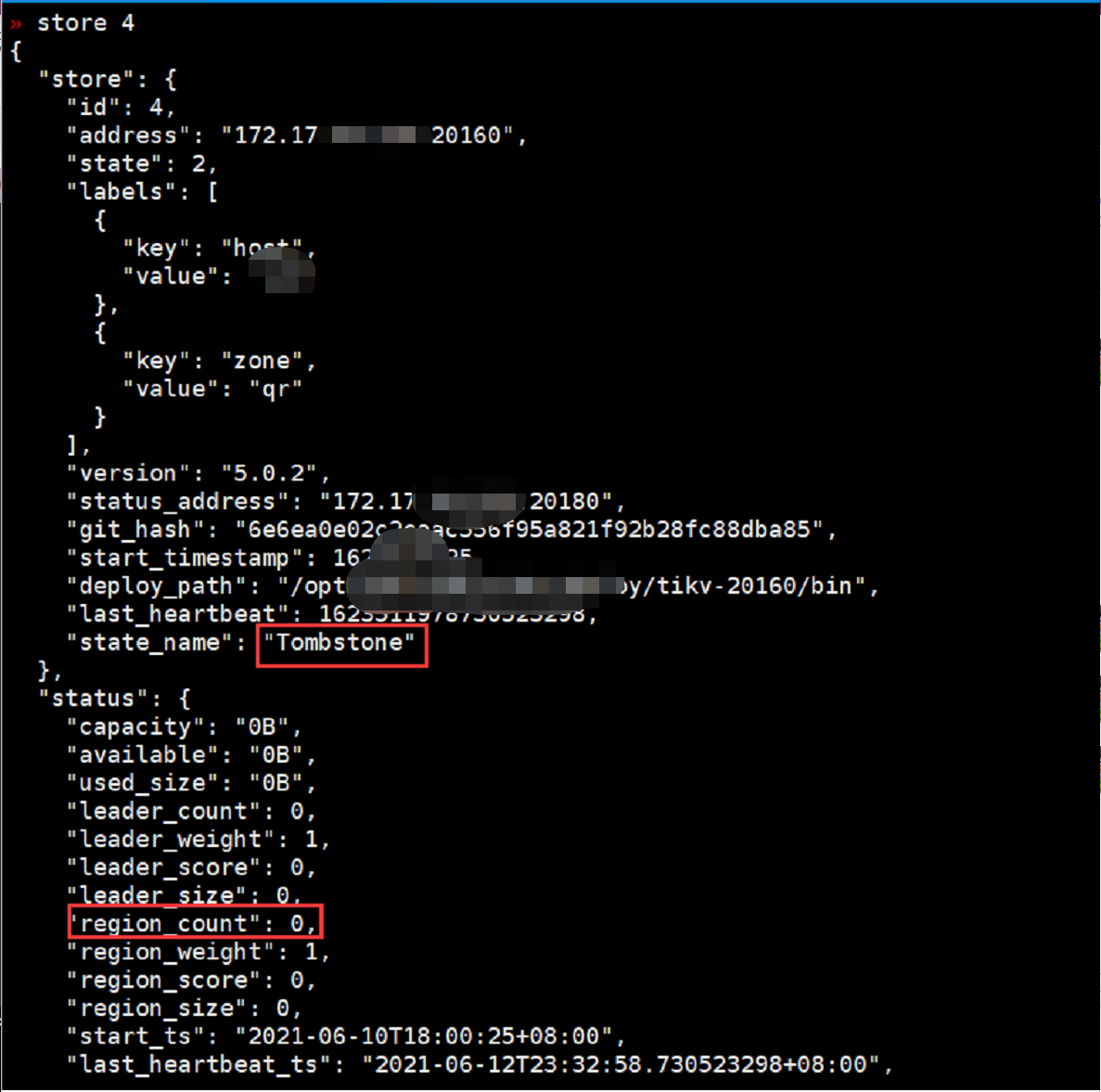
由于使用label将云服务器与本地机房做了隔离,所以不在同一区域的tikv无法进行region自动迁移,这就导致云服务器上最后一台tikv缩容失败。虽然使用–force参数强制删除了云服务器上第三台tikv节点,但是该节点上的region并没有迁移到本地机房,在pd-ctl store中仍能看到该tikv节点的信息,如上面问题中的截图,该节点state_name为Offline(共有三种状态: Up、Offline、Tombstone,只有在Tombstone状态下才能使用store remove-tombstone清理),region_count为29532(该节点有29532个region)。
刚开始是想通过store delete 4下线该store,但是由于该节点已经被强制下线,store delete 4运行的结果虽然是success,但是并不会删除残存的store 4。
最后的解决方法是:
1)将最小隔离级别设置为host(之前为了隔离云服务器与本地机房设置为了zone(最开始规划是dc,后面改成了zone)):
pd-ctl config set isolation-level host
2)将云服务器上第三台Tikv的zone label(hw)更改为本地机房的zone label(qr):
pd-ctl store label 4 zone qr
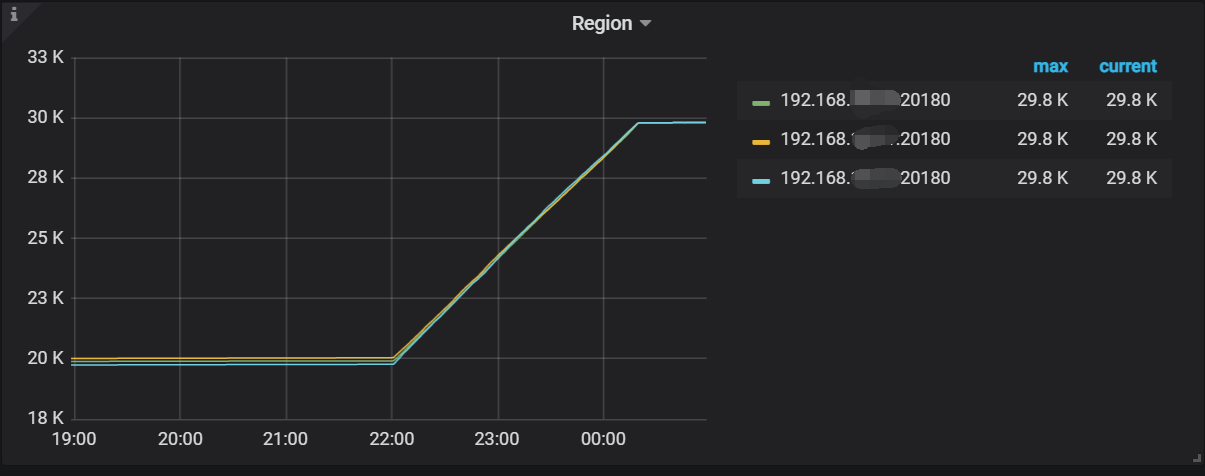
3)更改完后region就开始自动迁移了
4)等待region迁移完后,查看store 4的state状态变成了Tombstone,region_count则为0
5)最后使用pd-ctl store remove-tombstone清理掉即可。
1 个赞
system
(system)
关闭
18
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。