版本 4.0.10
Time: 2021-06-07T21:58:52.573896122+08:00
Txn_start_ts: 425479196896657415
Conn_ID: 12343962
Query_time: 3.570202119
Parse_time: 0.000069923
Compile_time: 0.000146251
Rewrite_time: 0.000018139
Prewrite_time: 3.565945997 Commit_backoff_time: 3.561 Backoff_types: [txnLock txnLock txnLock txnLock txnLock] Resolve_lock_time: 0.001535063 Write_keys: 3 Write_size: 1088 Prewrite_region: 2 Txn_retry: 1
DB: product
Is_internal: false
Digest: 50f2f2d5624ca96ad880d112448c731ff95362563a4ef75dff252b0237c3301b
Num_cop_tasks: 0
Mem_max: 8545
Prepared: false
Plan_from_cache: false
Has_more_results: false
KV_total: 0.007867307
PD_total: 0.000450151
Backoff_total: 3.561
Write_sql_response_total: 0
Succ: true
update table a=m where xx=yy;
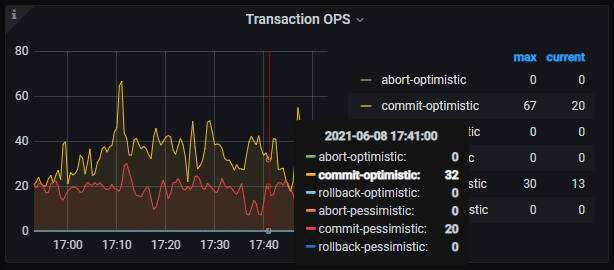
这种是因为写写冲突后导致后续的事务backoff事件,从而耗时增加。
1、请问如何能找到跟这个事务写冲突的另外一个事务或者对应的sql语句?
2、写写冲突txnlock后,backoff单次最低100ms,最多3000ms,请问这个需要怎么优化下? try_time=3,每次backoff=500ms ?