为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
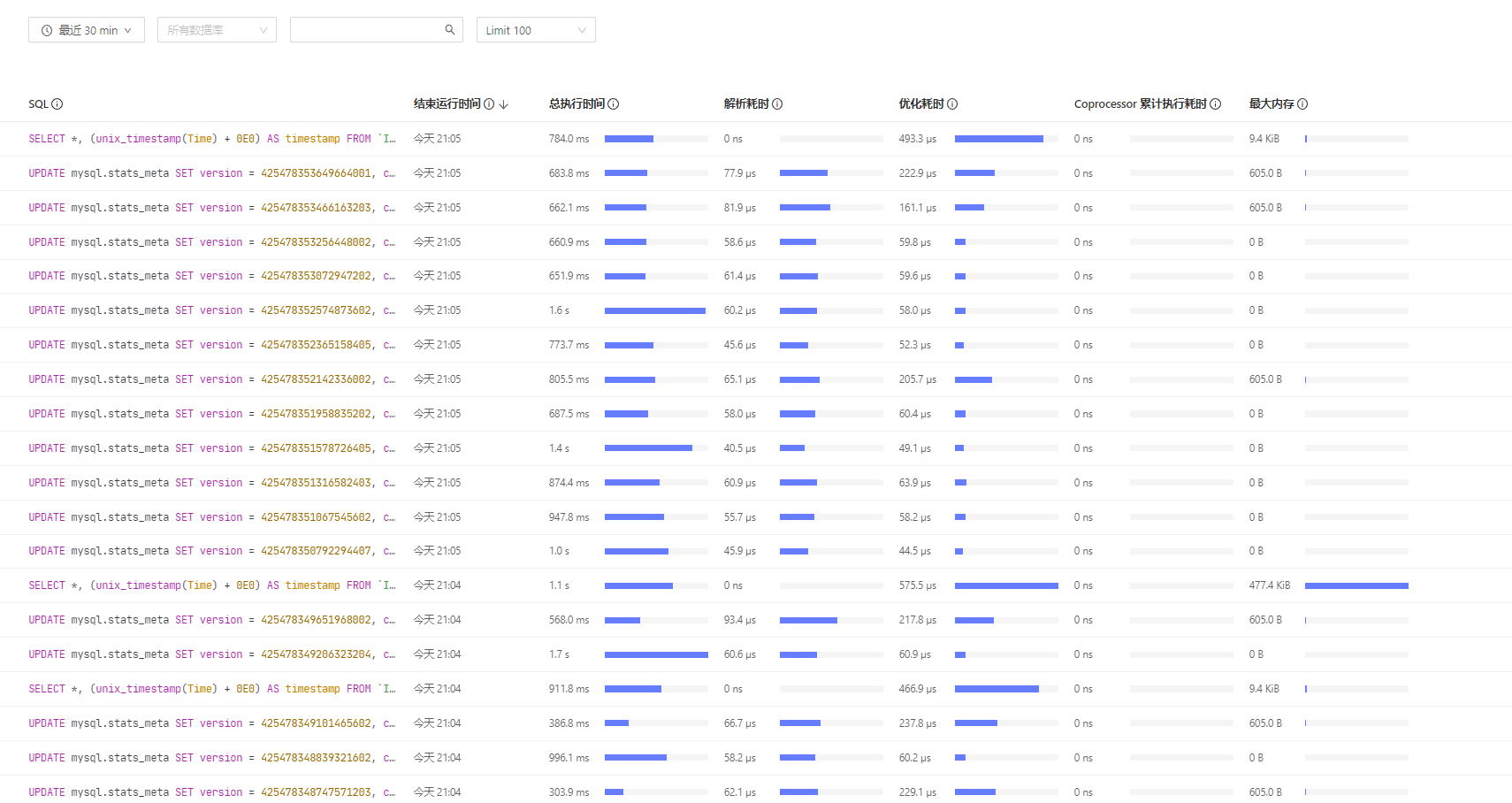
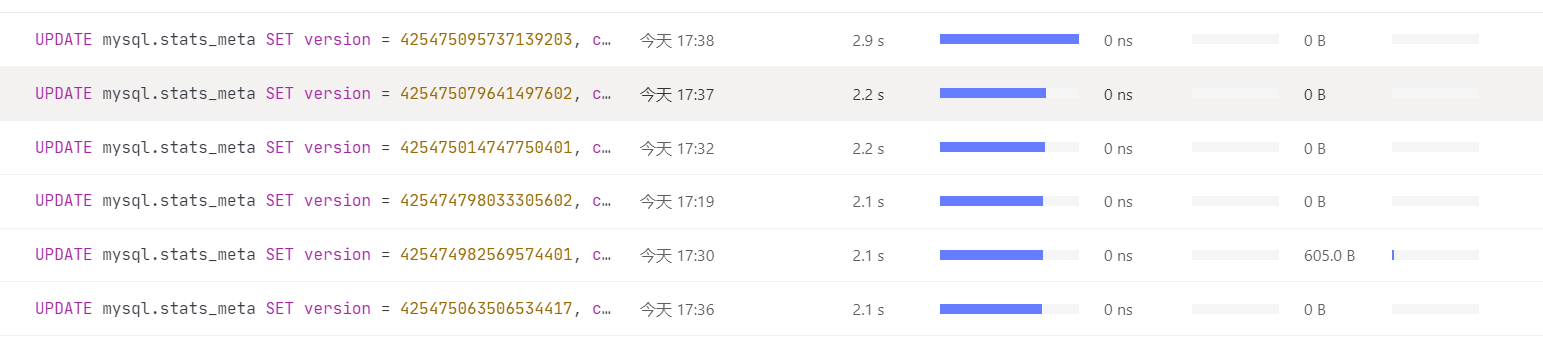
【问题概述】 tidb内部的更新sql超时
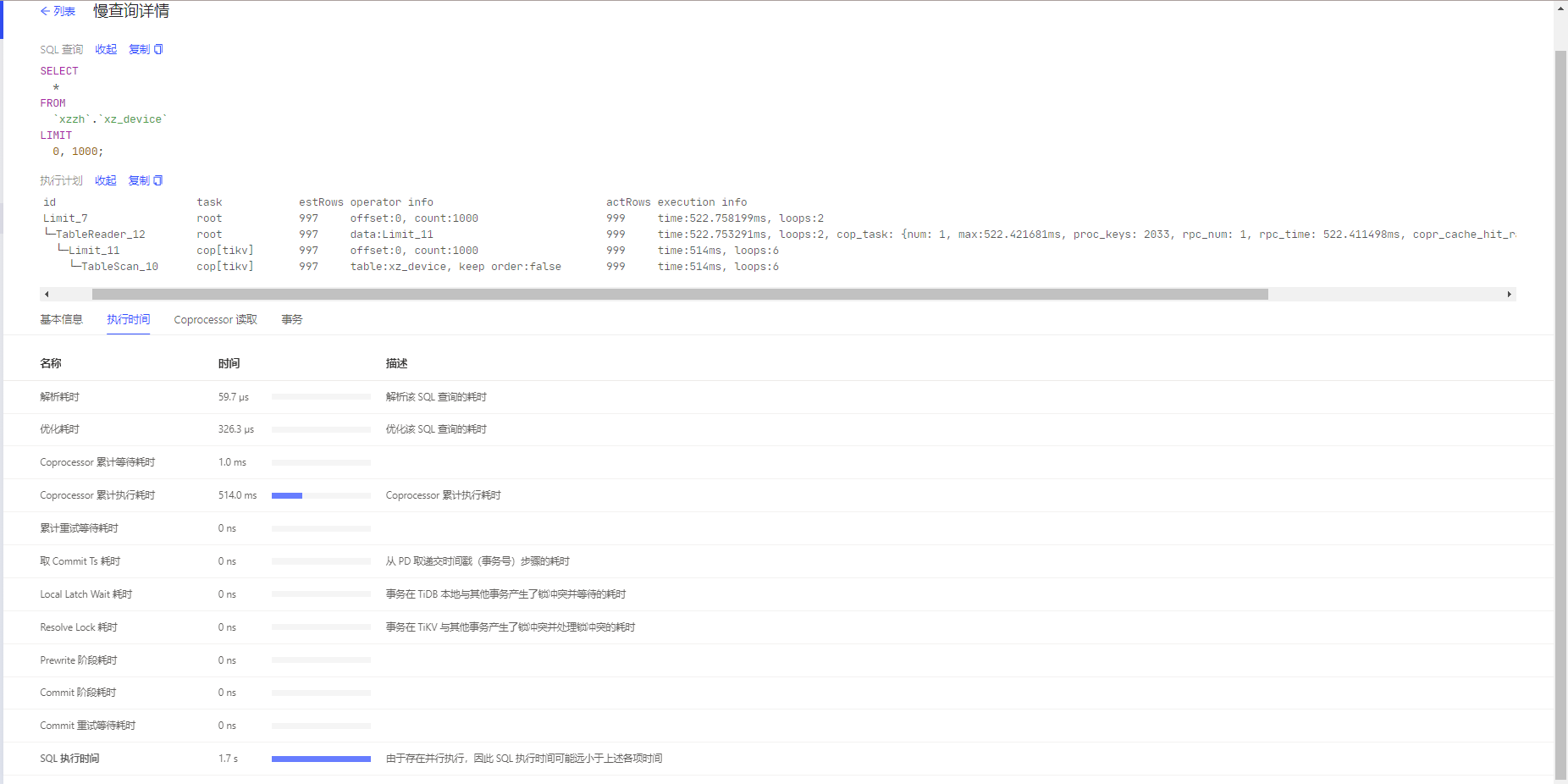
执行计划:
id task estRows operator info actRows execution info memory disk
Update_2 root 0 N/A 0 time:2.866076013s, loops:1 0 Bytes N/A
└─Point_Get_1 root 1 table:stats_meta, index:tbl(table_id), lock 0 time:2.866068086s, loops:1, Get:{num_rpc:1, total_time:26.858798ms} N/A N/A
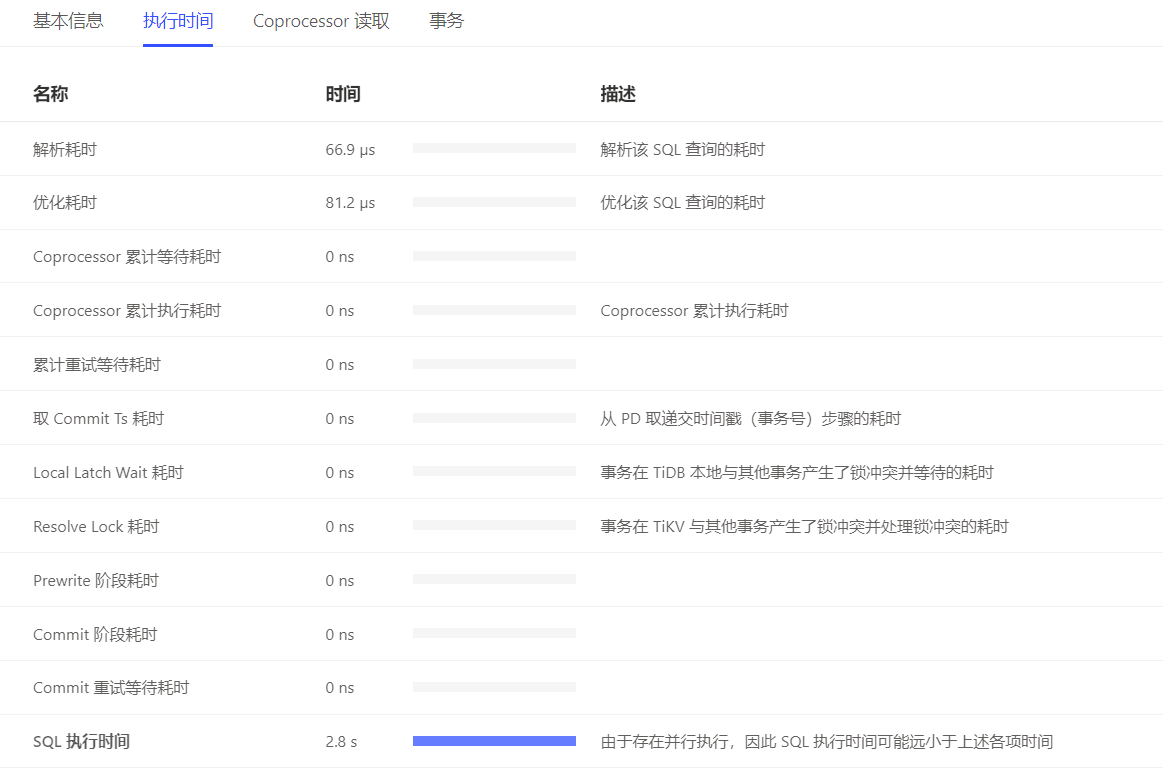
获取悲观锁的时间也比较长:

【TiDB 版本】 v4.0.8
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。