该问题在https://asktug.com/t/topic/63007有提出,但是没有后续回答。
该问题通过重启机器可以暂时解决,但后续又会出现
好,后续我们再继续观察一下看是否需要升级集群
![]()
![]()
![]()
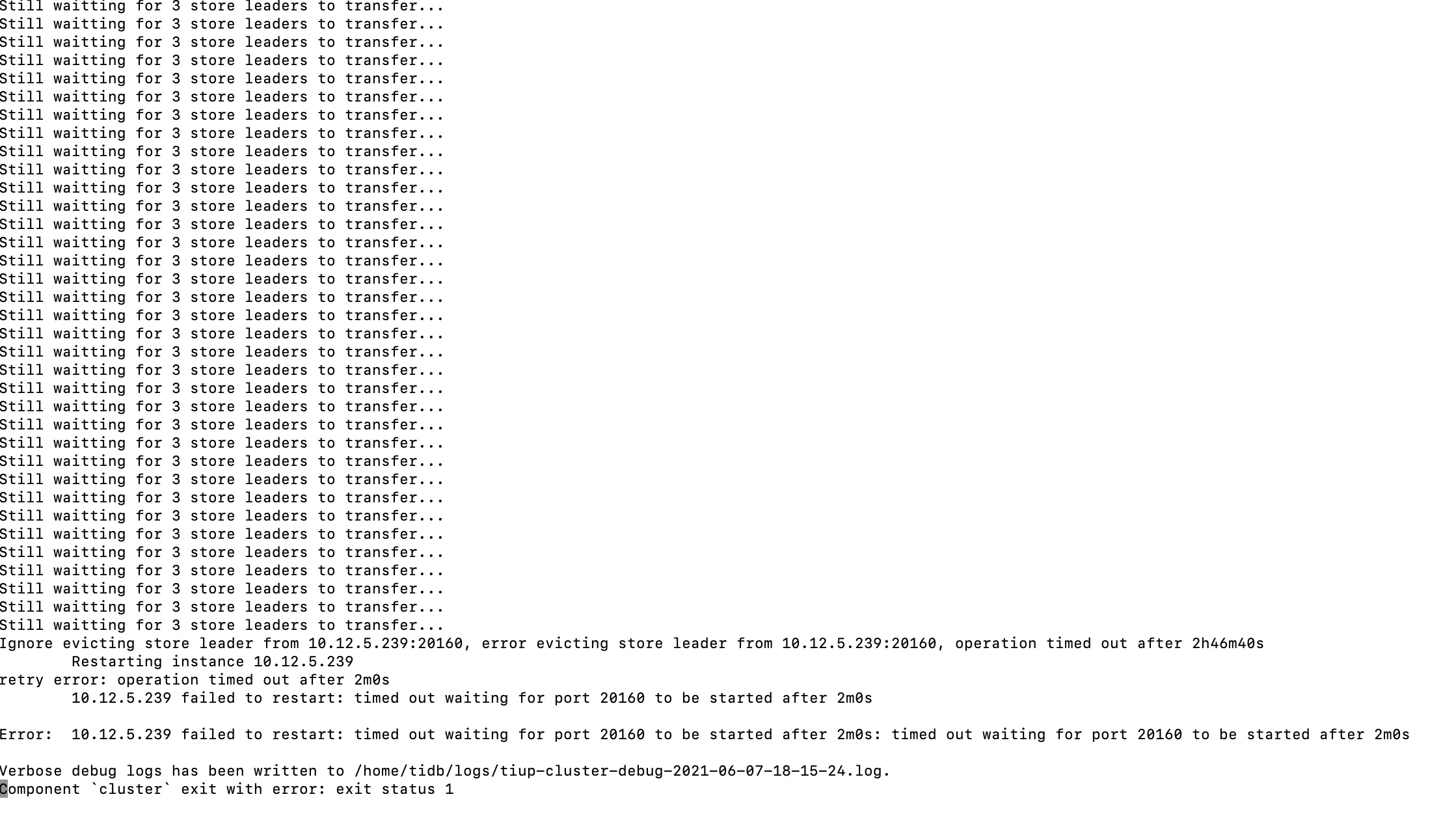
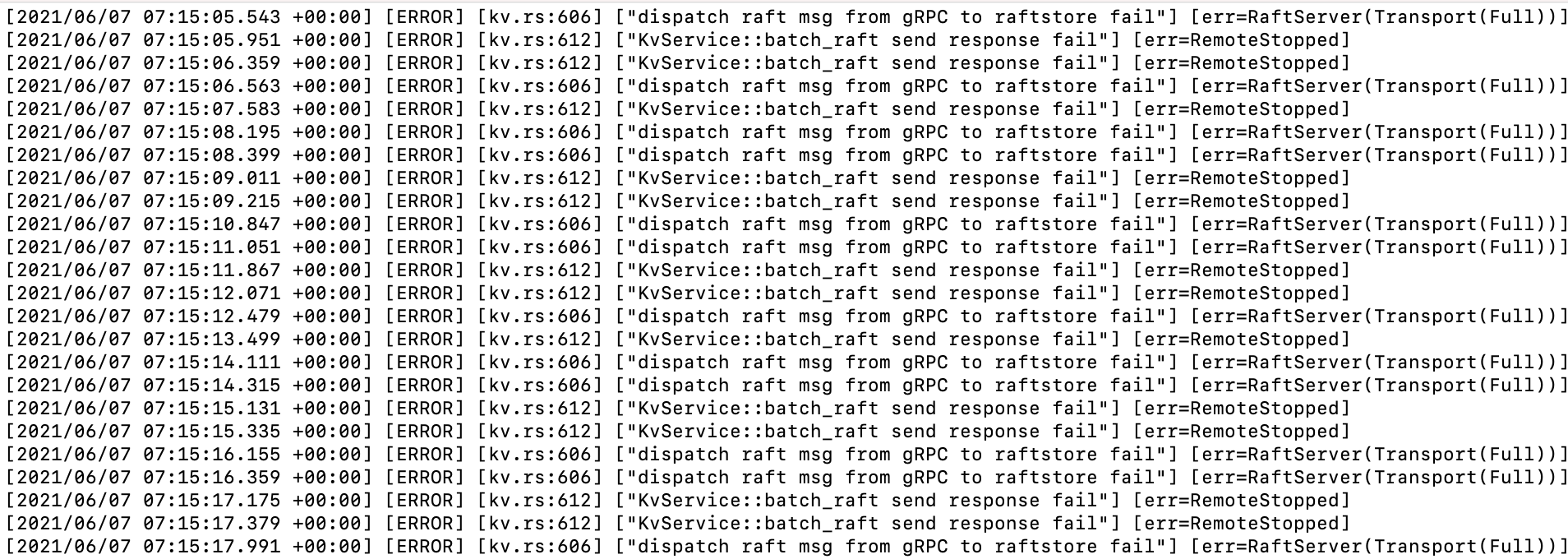
执行 nohup tiup cluster upgrade test-cluster v4.0.13 --transfer-timeout 10000,报错如图
您好,关于第二点,是否可以理解为,使用force参数升级完集群后,集群中会出现部分region没有leader,这时调度会自动执行leader选举,等leader调度完成后,集群就恢复正常了?
不是升级完集群后会有部分 region 没有 leader
是 force 的话,会直接停止 tikv 实例,也就是对应 leader 在该实例上的 region 会直接失去 leader ,需要等待重新选举出新的 leader 对外提供服务。在没有选举出 leader 的时候,应用访问到了对应的 region 的话,会出现 not leader 的 backoff ,知道 backoff 等到新 leader 选举出现,完成访问。
嗯嗯,就是force命令执行完成后需要等待选出leader才能正常提供服务,我们内部商量一下看是否要用。
您好,执行未加force命令的upgrade后,现在日志卡在如图情况
执行region --jq=".regions[] | {id: .id, leader_store_id: .leader.store_id | select(.==24478148) }"命令结果如下
{“id”:80616381,“leader_store_id”:24478148}
{“id”:80950046,“leader_store_id”:24478148}
{“id”:248731054,“leader_store_id”:24478148}
{“id”:359185,“leader_store_id”:24478148}
{“id”:6963497,“leader_store_id”:24478148}
{“id”:112293,“leader_store_id”:24478148}
{“id”:93992158,“leader_store_id”:24478148}
对每个region查看具体情况如下
region 80616381
{
“id”: 80616381,
“start_key”: “7480000000000204FFF75F728000000005FFE80F6E0000000000FA”,
“end_key”: “7480000000000204FFF75F728000000005FFEA52750000000000FA”,
“epoch”: {
“conf_ver”: 18585,
“version”: 52318
},
“peers”: [
{
“id”: 245278358,
“store_id”: 24478148
},
{
“id”: 246648589,
“store_id”: 38833310
},
{
“id”: 268592857,
“store_id”: 24590972
}
],
“leader”: {
“id”: 245278358,
“store_id”: 24478148
},
“written_bytes”: 0,
“read_bytes”: 0,
“written_keys”: 0,
“read_keys”: 0,
“approximate_size”: 97,
“approximate_keys”: 163840
}
» region 80950046
{
“id”: 80950046,
“start_key”: “7480000000000204FFF75F728000000025FF64E9AC0000000000FA”,
“end_key”: “7480000000000204FFF75F728000000025FF670E300000000000FA”,
“epoch”: {
“conf_ver”: 18603,
“version”: 55903
},
“peers”: [
{
“id”: 80950048,
“store_id”: 24590972
},
{
“id”: 248315125,
“store_id”: 24478148
},
{
“id”: 484725795,
“store_id”: 24480822
}
],
“leader”: {
“id”: 248315125,
“store_id”: 24478148
},
“pending_peers”: [
{
“id”: 484725795,
“store_id”: 24480822
}
],
“written_bytes”: 0,
“read_bytes”: 0,
“written_keys”: 0,
“read_keys”: 0,
“approximate_size”: 97,
“approximate_keys”: 158669
}
» region 248731054
{
“id”: 248731054,
“start_key”: “7480000000000001FF745F728000000025FF3F4CCB0000000000FA”,
“end_key”: “7480000000000001FF745F728000000025FF3F606B0000000000FA”,
“epoch”: {
“conf_ver”: 63807,
“version”: 19744
},
“peers”: [
{
“id”: 248731055,
“store_id”: 24478148
},
{
“id”: 248731057,
“store_id”: 38833310
},
{
“id”: 315144887,
“store_id”: 24590972
}
],
“leader”: {
“id”: 248731055,
“store_id”: 24478148
},
“written_bytes”: 0,
“read_bytes”: 0,
“written_keys”: 0,
“read_keys”: 0,
“approximate_size”: 137,
“approximate_keys”: 0
}
» region 359185
{
“id”: 359185,
“start_key”: “7480000000000001FFF15F698000000000FF0000020131353735FF37383838FF323100FF0000000000F90380FF0000000003FEFA00FE”,
“end_key”: “7480000000000001FFF15F698000000000FF0000020131353736FF30383939FF343600FF0000000000F90380FF00000000A3C7D600FE”,
“epoch”: {
“conf_ver”: 953,
“version”: 2859
},
“peers”: [
{
“id”: 24488100,
“store_id”: 24478148
},
{
“id”: 115818100,
“store_id”: 38833310
},
{
“id”: 268660874,
“store_id”: 24590972
}
],
“leader”: {
“id”: 24488100,
“store_id”: 24478148
},
“written_bytes”: 251,
“read_bytes”: 0,
“written_keys”: 1,
“read_keys”: 0,
“approximate_size”: 77,
“approximate_keys”: 1067125
}
» region 6963497
{
“id”: 6963497,
“start_key”: “7480000000000001FF745F728000000010FF85586A0000000000FA”,
“end_key”: “7480000000000001FF745F728000000010FF85D7110000000000FA”,
“epoch”: {
“conf_ver”: 1481,
“version”: 8276
},
“peers”: [
{
“id”: 248506405,
“store_id”: 38833310
},
{
“id”: 249024553,
“store_id”: 24478148
},
{
“id”: 330268746,
“store_id”: 24480822
}
],
“leader”: {
“id”: 249024553,
“store_id”: 24478148
},
“pending_peers”: [
{
“id”: 330268746,
“store_id”: 24480822
}
],
“written_bytes”: 0,
“read_bytes”: 0,
“written_keys”: 0,
“read_keys”: 0,
“approximate_size”: 78,
“approximate_keys”: 0
}
» region 112293
{
“id”: 112293,
“start_key”: “7480000000000001FF745F728000000005FF04BF420000000000FA”,
“end_key”: “7480000000000001FF745F728000000005FF04FB3B0000000000FA”,
“epoch”: {
“conf_ver”: 908,
“version”: 3548
},
“peers”: [
{
“id”: 246079850,
“store_id”: 38833310
},
{
“id”: 248331895,
“store_id”: 24478148
},
{
“id”: 326423698,
“store_id”: 24590972
}
],
“leader”: {
“id”: 248331895,
“store_id”: 24478148
},
“written_bytes”: 0,
“read_bytes”: 0,
“written_keys”: 0,
“read_keys”: 0,
“approximate_size”: 49,
“approximate_keys”: 40960
}
» region 93992158
{
“id”: 93992158,
“start_key”: “7480000000000204FFF75F698000000000FF0000010130783437FF39643336FF656363FF6435653862FF6264FF633937646331FF39FF38653232383933FFFF3164393331333538FFFF65646236346137FF31FF643630326438FF3937FF3363393837FF656664FF64320000FF00000000F9000000FC”,
“end_key”: “7480000000000204FFF75F698000000000FF0000010130783437FF65313838FF666133FF3739303061FF3035FF333564326137FF35FF35333231613935FFFF3339666634623961FFFF65623362313832FF39FF383865313138FF3834FF6364663366FF323066FF64640000FF00000000F9000000FC”,
“epoch”: {
“conf_ver”: 18585,
“version”: 51663
},
“peers”: [
{
“id”: 99404516,
“store_id”: 38833310
},
{
“id”: 160011777,
“store_id”: 24478148
},
{
“id”: 318613622,
“store_id”: 262397455
}
],
“leader”: {
“id”: 160011777,
“store_id”: 24478148
},
“written_bytes”: 0,
“read_bytes”: 0,
“written_keys”: 0,
“read_keys”: 0,
“approximate_size”: 101,
“approximate_keys”: 732440
}
参考https://asktug.com/t/topic/63377的方法对其中有down和pending的region执行remove-add操作
operator add remove-peer 80950046 24480822
operator add remove-peer 6963497 24480822
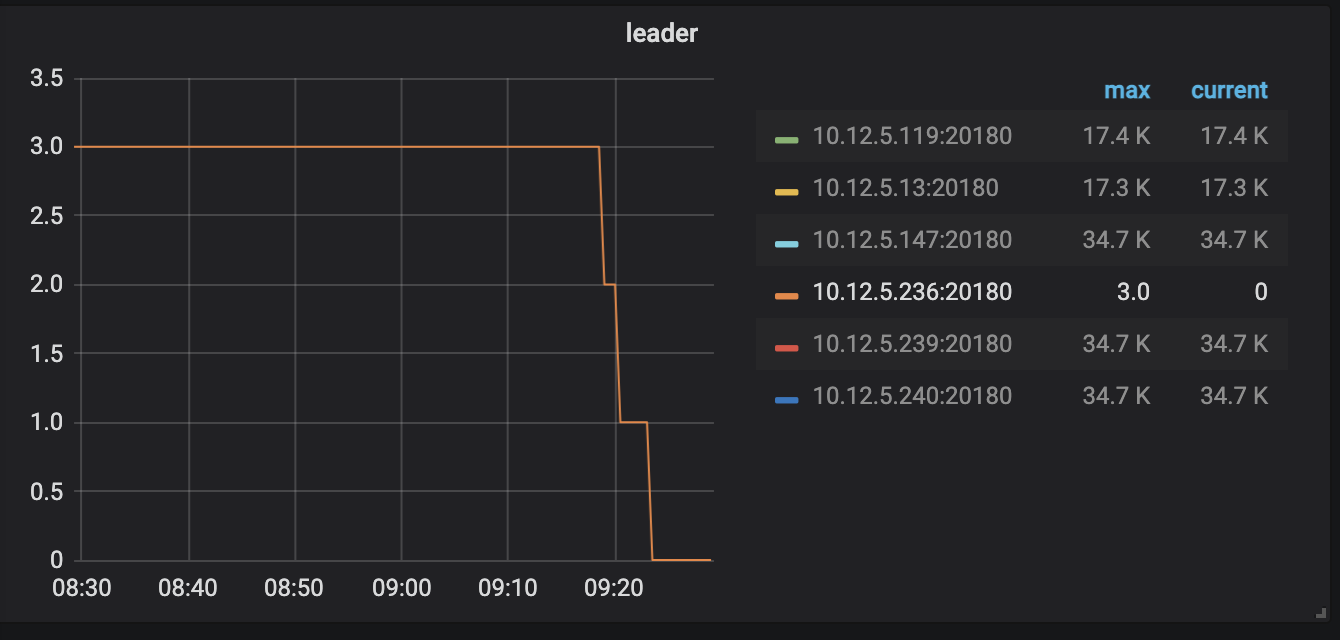
发现region状态无变化,升级进度也未推进,但监控显示236的leader数量已经降到0
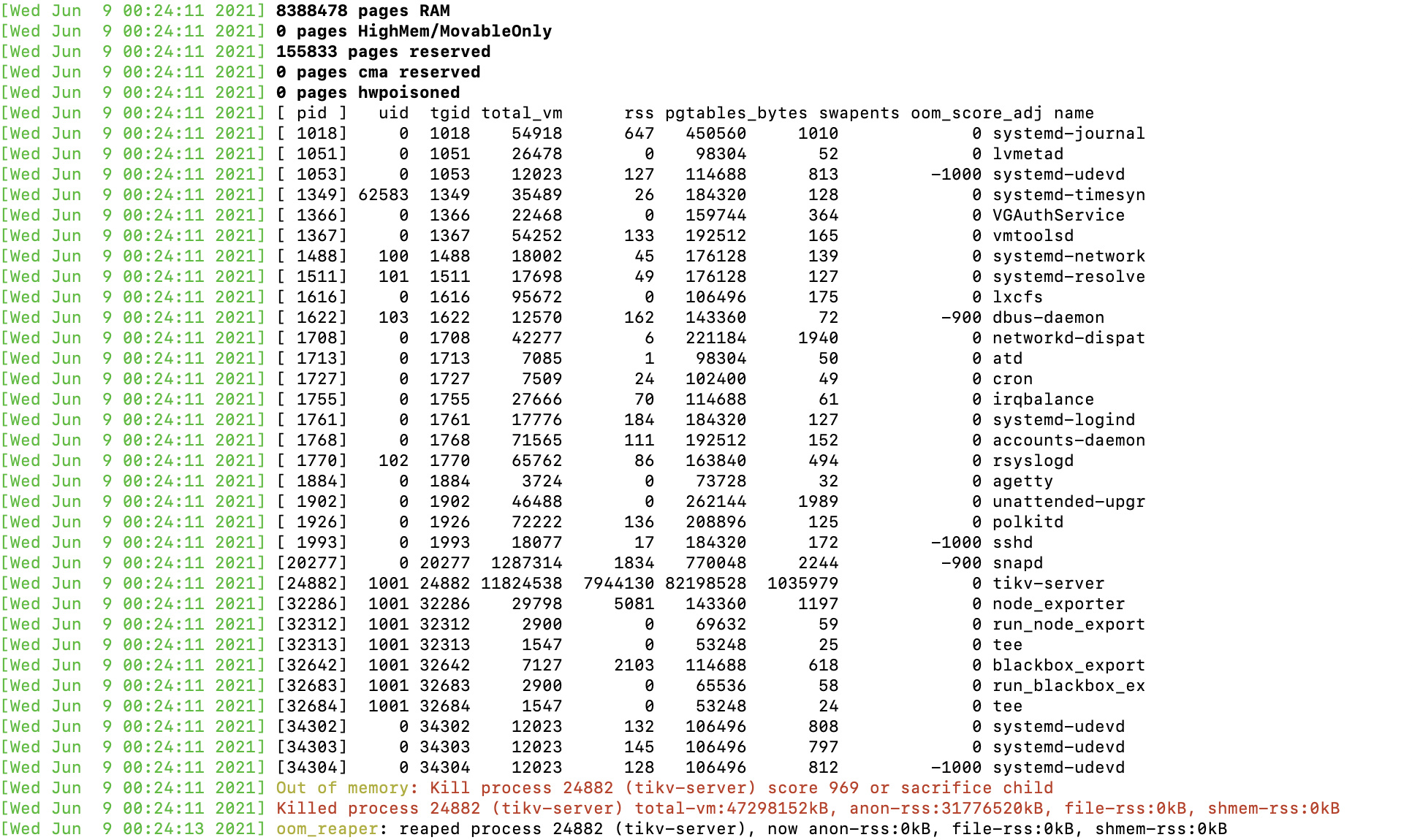
另外,通过在236机器上执行类似于grep ‘80616381’ tikv.log 发现大量lease is not expired日志,其他region同理
日志如下:
链接: 百度网盘-链接不存在 密码: qfds
针对以上情况,请问接下来该如何操作,该集群需要尽快恢复使用,烦请加急处理,谢谢
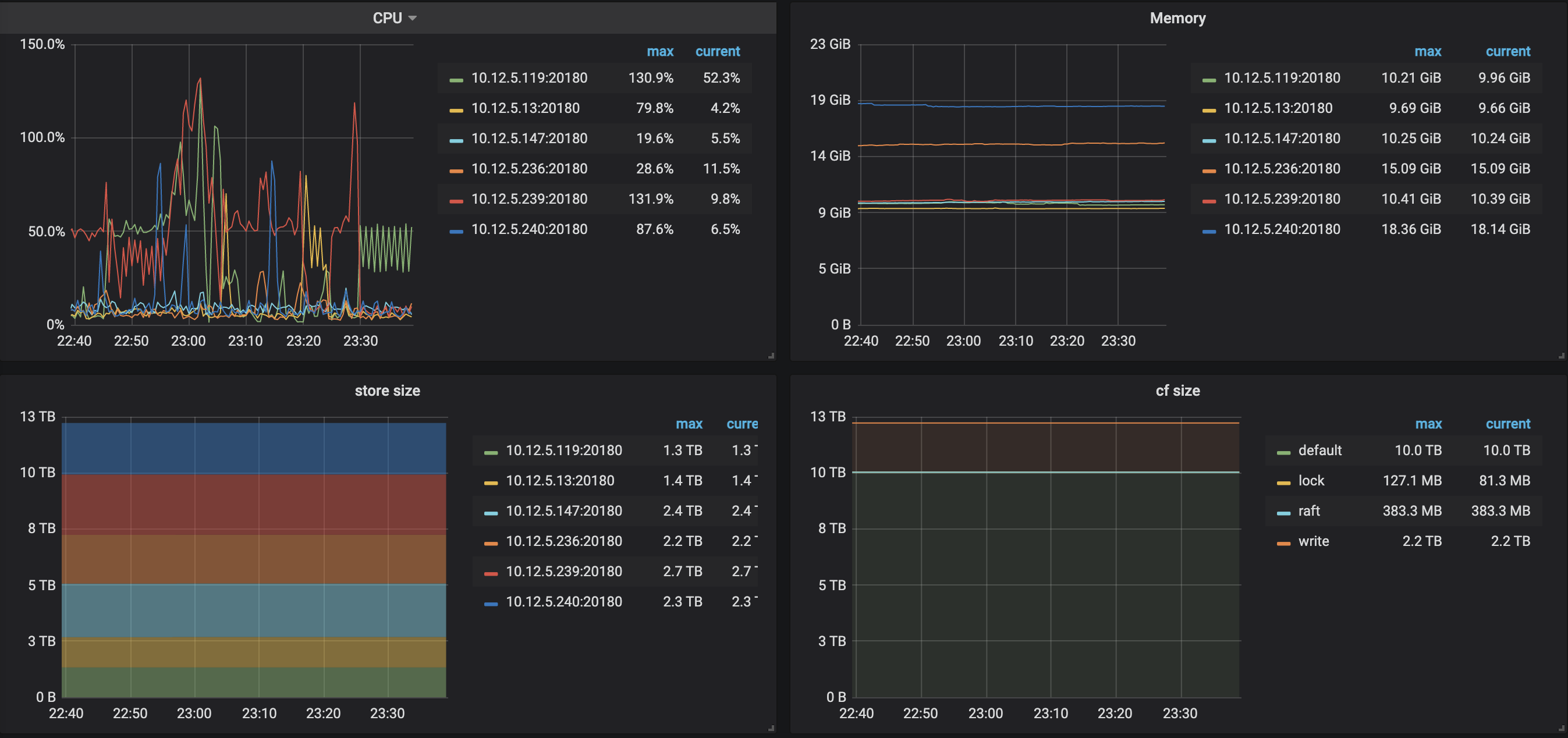
看下grafana 的over-view 监控信息,是否 tidb 和 tikv 资源在这个时候有大量使用。
查看 dashboard 的慢日志,按照内存排序,有没有大sql排查下。
@abcd 建议参考楼上建议做一下 SQL 排查,初步排查可能是大查询导致的 TiKV 的重启。需要进一步确认一下。 可以通过 TiKV log 查看一下 slow query 的 table id 和时间是否和 TiKV 重启时间点是否匹配,然后根据时间点做一下 slow query 的排查。
dashboard的慢查询功能现在无法使用,有什么办法修复吗
图在上面的回复第二张,dashboard慢查询界面空白,但实际上是有慢查询的,另外现在集群中节点版本不一致,是否会有影响
可能会有影响, 建议尽快通过 TiUP upgrade 将版本拉齐。另外可以先通过 slow query 的排查文档,先定位一下慢查询,优先处理慢查询带来的集群异常。
使用tiup升级遇到的问题也在上面详细给出了,请问如何解决