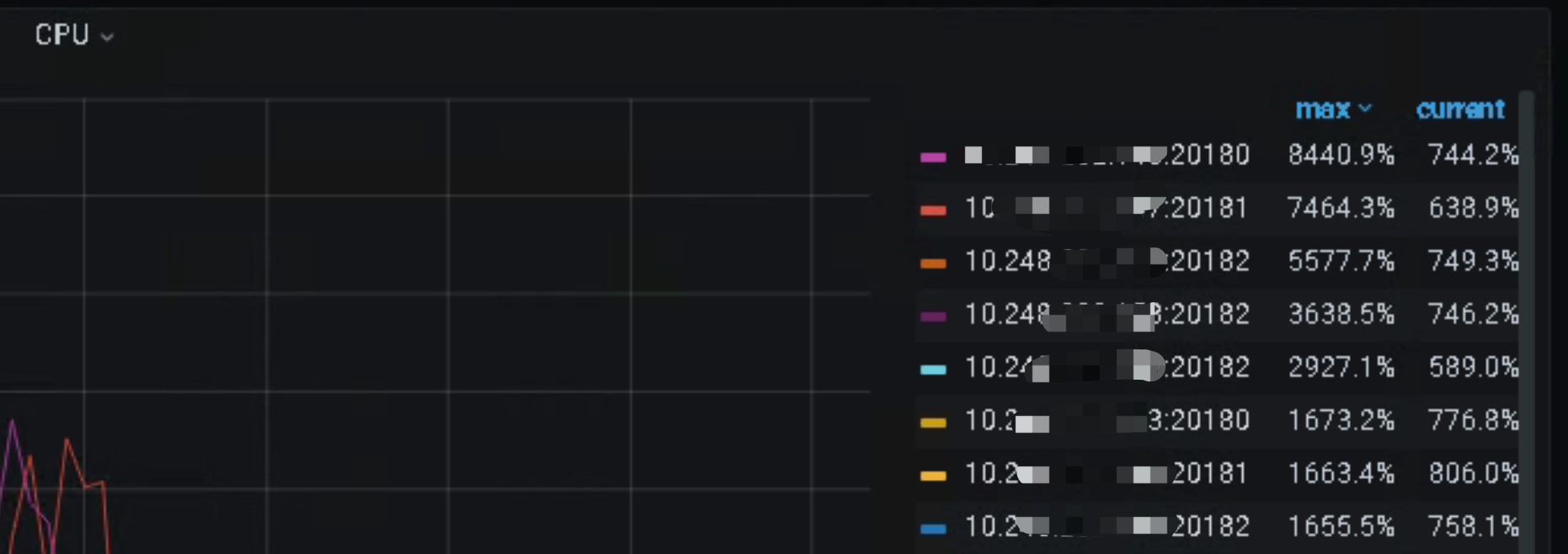
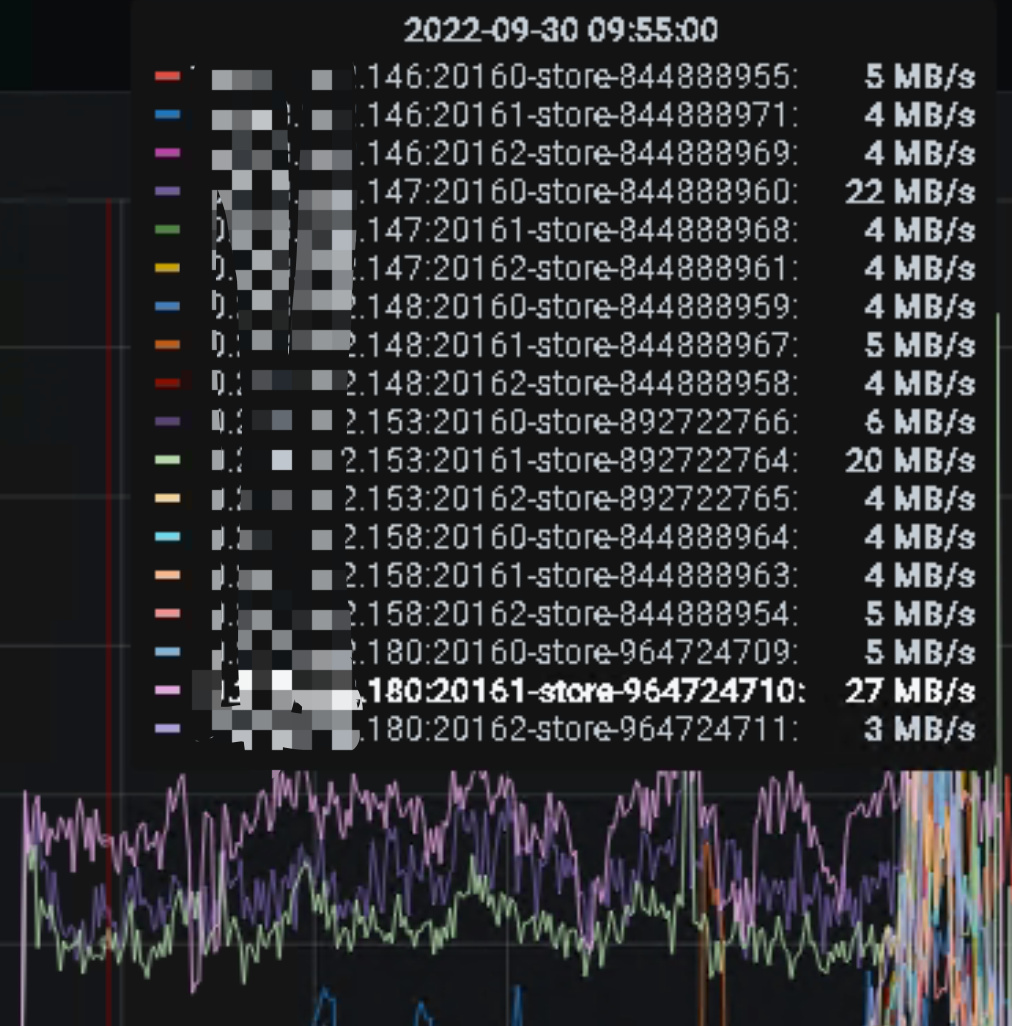
描述:使用TiSpark跑批时,在进行写入时集群延迟大,导致集群不可用。
版本:TiSpark 2.3.13 、TiDB 5.2.4版本、Spark版本2.4.7
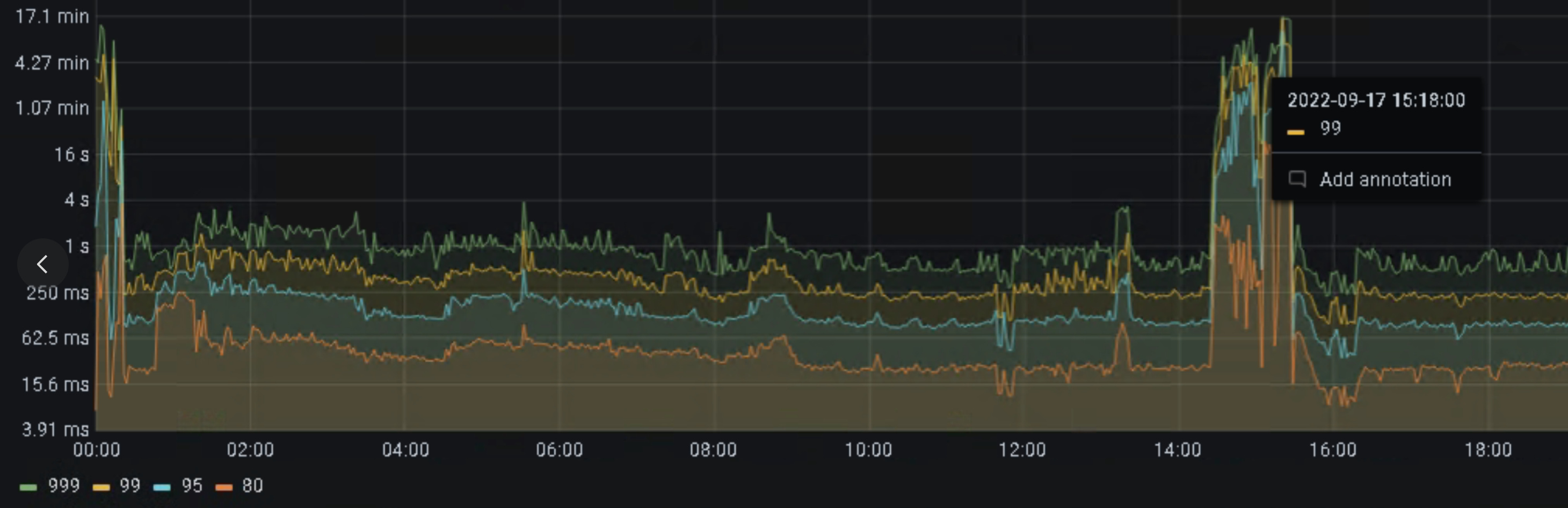
说明:spark load数据时,延迟略高,在写入时明显增大

请问什么原因呢,参数配置问题还是TiSpark版本问题
描述:使用TiSpark跑批时,在进行写入时集群延迟大,导致集群不可用。
版本:TiSpark 2.3.13 、TiDB 5.2.4版本、Spark版本2.4.7
说明:spark load数据时,延迟略高,在写入时明显增大
请问什么原因呢,参数配置问题还是TiSpark版本问题
tikv的cpu,内存,io是什么使用情况?
参考写入慢,排查一下,具体哪里慢了?
可能是写热点问题,尝试auto_random打散写热点,会不会有帮助。
有3个实例比其他实例写的多,这个表是无主键的,已经设置SHARD_ROW_ID_BITS=6了,请问还有其他打散方式吗?
感觉写其他表时,这种写的方式都会明显集群延时特别高,整个集群不可用,查询都处于等待状态,这种tispark写能否限制资源使用呢,
印象中没有控制并发的参数,因为是直写tikv,集群比较小的情况下,干扰是比较大。