【环境】
源端:v5.2.3 、表2亿条数据,约167个varchar(100)字段,只有1个FILEDATE 是int字段
目标端:v6.1.1、空表
sync_diff_inspector: v2.0
表索引:
TABLE_NAME varchar(100) NOT NULL,
FILE_NAME varchar(100) DEFAULT NULL,
FILEDATE int(11) NOT NULL,
PRIMARY KEY (TABLE_NAME,FILEDATE) /*T![clustered_index] NONCLUSTERED */,
KEY INX_USAIMS_FILENAME_20220913 (FILENAME),
KEY INX_USAIMS_CALLNUMBER_20220913 (CALLINGNUMBER,CALLEDNUMBER)
)
PARTITION BY LIST (FILEDATE)
(PARTITION P20220901 VALUES IN (20220901),
PARTITION P20220902 VALUES IN (20220902),
配置文件参数:
check-thread-count = 4
chunk-size = 10000
【过程】
使用一张表做sync_diff检查,使用show processlist检查执行的SQL 只有一个全表扫描:
select xxx as CHECKSUM FROM jiesuan.T_GIMS_USAGE_13_202209 WHERE ((TRUE) AND (TRUE))
【问题】
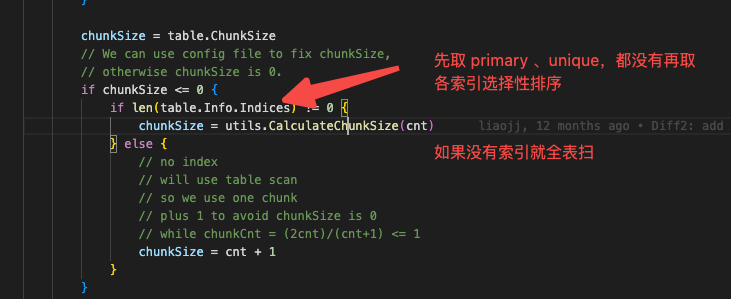
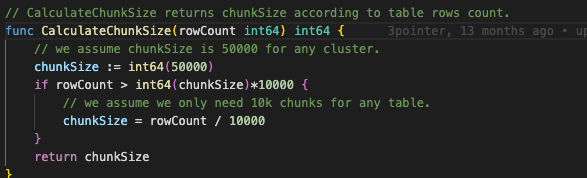
1、 从show processlist结果看,并没有划分chunk。chunk范围划分是否只能靠单列Int类型的主键、唯一键索引?
2、 未能划分chunk,全表扫描后,在tidb server内存储全量表数据,比对需要全表全部完成后才能释放内存 还是比对一部分完成释放一部分?
4、 check-thread-count的并发作用范围是单个表的线程数 还是整库的线程数(比如通过正则校验一批表)? 为什么上游会略大于该值,大概高多少?
check-thread-count # 检查数据的线程数量,上下游数据库的连接数会略大于该值
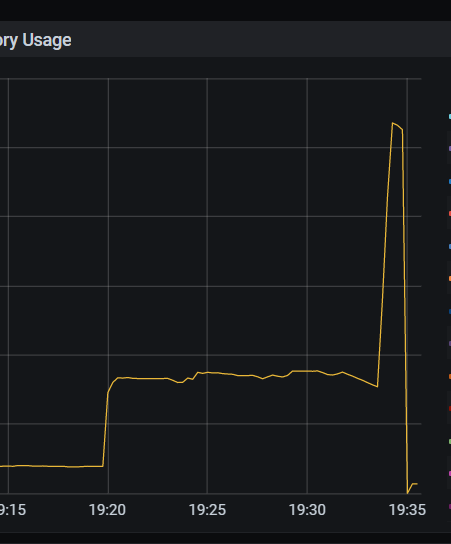
5、 运行一段时间后tidb内存突然增高,导致oom,为什么会突然增高?(试过2次大概在15分钟左右突增的)