h5n1
(H5n1)
1
【5.2.3】
问题一:
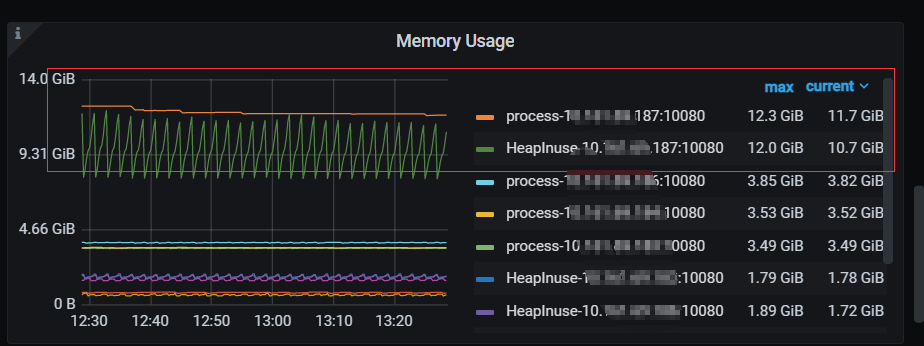
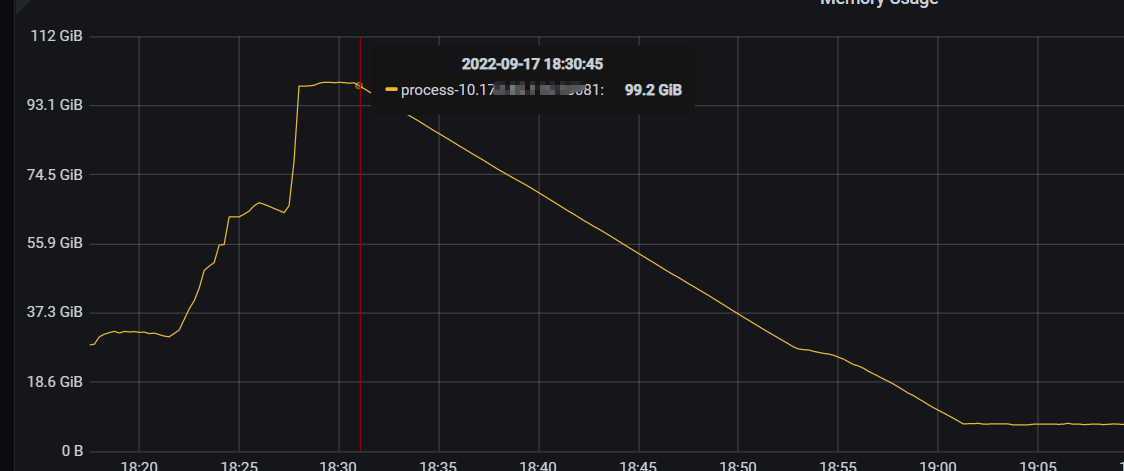
系统已insert写入为主,查询很少,其中一个tidb server相比其他的内存占用比较高,且heap也比较大,有3个DM同步任务使用该tidb server。
1、 heap内存储的是什么信息或者说pprofile中列出的为什么占这么大?
2、 有没什么方式手动释放内存(不重启) ?
3、影响内存释放的原因有哪些?
问题二:
另外tidb内存释放较忙,比如99G内存释放完要半小时,能否实现快速释放?
问题三:
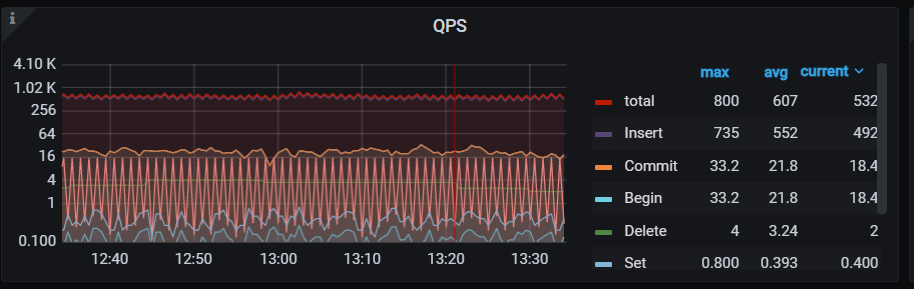
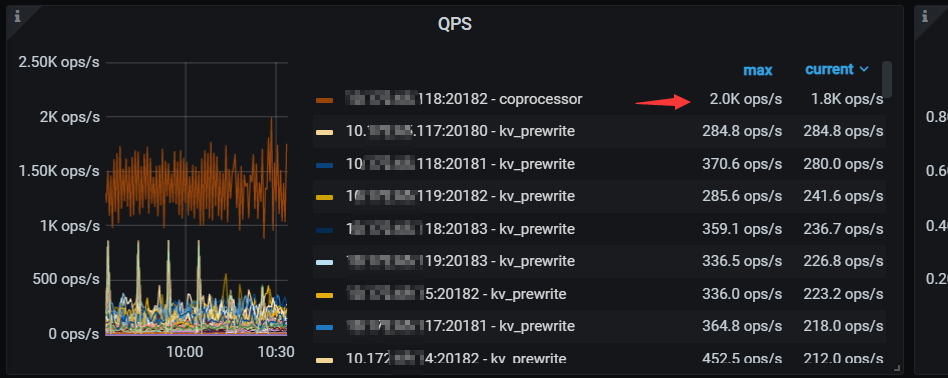
另外,该库上有个奇怪现象就是某个tikv节点有大量的coprocessor请求,而实际并没有多少查询请求
h5n1
(H5n1)
3
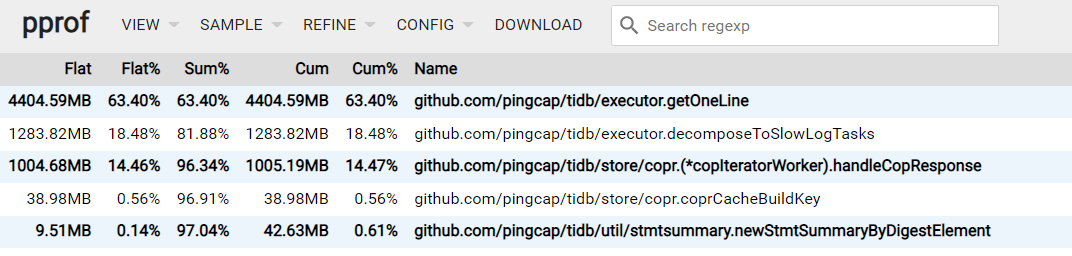
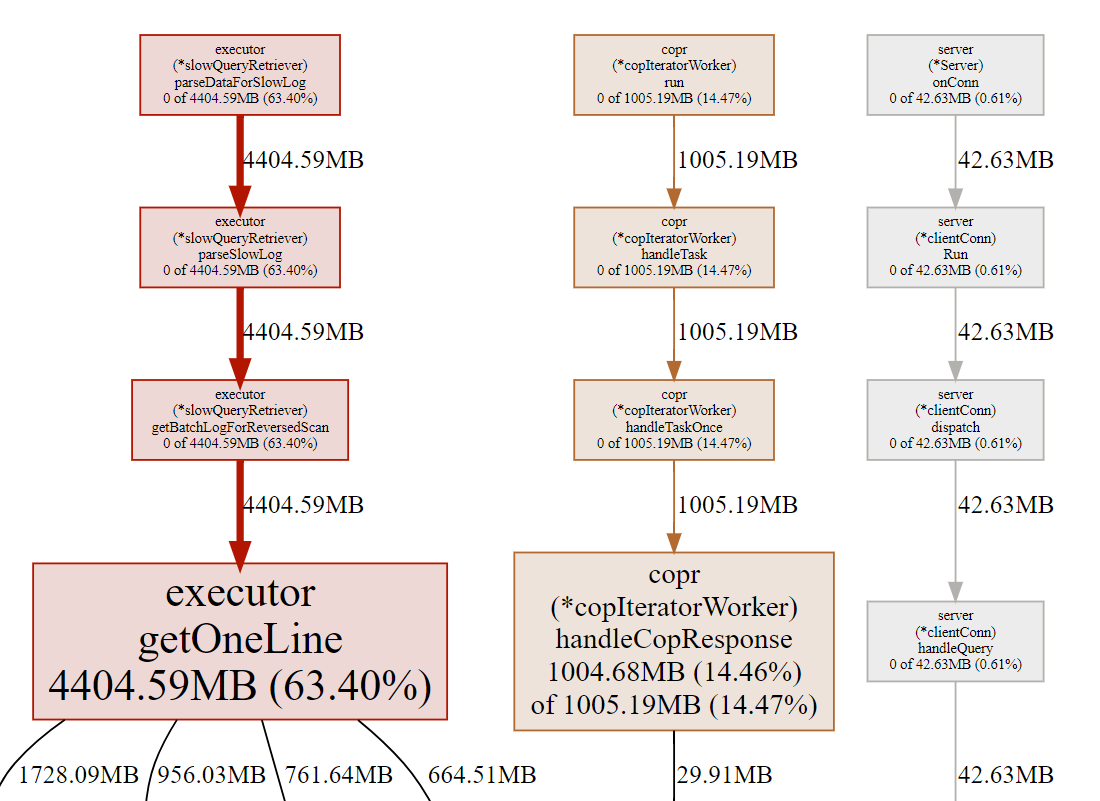
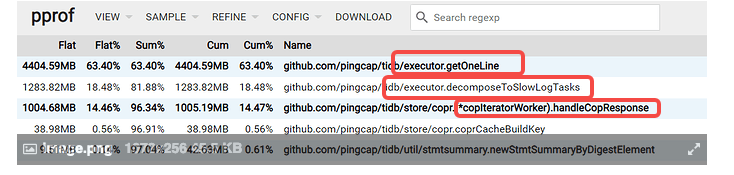
99这个是另一个问题了 不是上面的pprof结果,我在加点描述
Aric
(Jansu Dev)
4
- 高版本已经使用了 go gc 比较激进的参数;
- 暂时想不到什么能快速释放内存的方法;
- 还是得从数据库使用上解,比如设置 oom-action max-execute-time 等参数,内存用大了就杀,但还是得知道引发 memory 升高的原因;
BTW: 其实我还是没理解要解决的问题,如果 profile 和实际内存消耗能对上,从 profile 图上看,把 slow_query 功能关了?
h5n1
(H5n1)
5
pprofile的问题是 这个库基本只是同步insert操作,不知道排在排在前3个的具体做什么
h5n1
(H5n1)
7
这个库查询很少很少,但是你看问题三始终有一个tikv上千的cop请求,不知道这些请求来自哪里
人如其名
(人如其名)
9
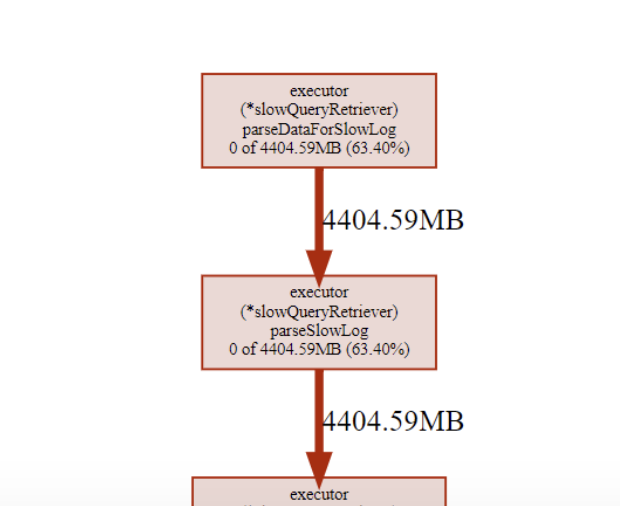
看这里是查询慢日志导致,是不是多次刷新过dashboard的慢日志界面?会导致慢日志不释放的bug的。这个在5.3.2修复了。