普罗米修斯
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】TiDB v3.0.3
【遇到的问题】下线了2个kv节点(每个1T),未在下线前添加硬盘,导致其他节点跑满,集群访问异常
【复现路径】
1.上线了1T ssd KV节点、128G KV 节点、1T HHD KV节点;
2.删除了爆盘kv节点的log日志,以及data/db/中LOG.old文件重启节点,但是可用一直居高不下;
3.新上线的1T ssd KV节点、128G KV 节点跑满目前集群disconnect,删除log日志,以及data/db/中LOG.old文件后使用量仍是100%,这两个新添加的KV节点无法启动,数据库无法访问;
4.调整replica-schedule-limit为64,加快下线速度;
【问题现象及影响】
1.下线的两块KV节点下线了6天,现在还有8G数据,下载速率特别慢,按照目前10个小时才能下线不到1G左右数据;
2.数据库无法访问
【附件】
普罗米修斯
3
麻烦问下:
1.怎么快速下线之前的KV节点;
2.还有什么办法将disconnected的kv节点拉起,如果不能拉起下一步该怎么操作?
h5n1
(H5n1)
4
pd-ctl config show看下,下线和扩容过程都要迁移region,会有较多IO产生,增大limit并发反而会让磁盘压力更大
普罗米修斯
6
我们现在计划使用
operator add transfer-region
operator add transfer-leader
将正在下线的kv节点中的region和leader转移出去,实现快速下线,这样操作可以吗
普罗米修斯
8
当下这个问题解决完就升级版本,麻烦先看下当前问题,生产环境,比较紧急,麻烦了
这个版本不确定有没有place_holder_file, 有的话修改
[storage]
reserve-space = “5GB” 为0, 释放一些空间。
1 个赞
下面的通过pd改store状态的在3.0上是不是支持我不确定 ,其他人了解的话可以补充下。
,其他人了解的话可以补充下。
你的问题是下线导致的,直接把下线中的tikv重新拉起来就行了
http://pdip:2379/pd/api/v1/store/storeid/state?state=Up
然后这样下线的2t空间不就有了吗。
然后检查下副本,是不是都够3副本。
https://docs.pingcap.com/zh/tidb/v3.0/pd-control#根据副本数过滤-region
如果确认是3副本正常,就可以强删满的节点了。或者说这个满的节点上的Region在其他节点上一定有2个正常副本,这样也能删。这一步一定要检查仔细。
curl -X POST http://{pdip}:2379/pd/api/v1/store/${store_id}/state?state=Tombstone
然后剩余的2副本可以在新拉起来的tikv上补齐。
普罗米修斯
11
这个版本没有place_holder_file这个文件
普罗米修斯
12
下线的tikv节点从2T数据剩余8G了。
1.目前想的是如果磁盘写满的节点能起来,数据库能恢复访问,我这边就等着kv节点下线,慢点就慢点。
2.如果磁盘写满的节点没有办法起来,我这边怎么能加快下线,在进行后续操作。
3.我设置了scheduler add evict-leader-scheduler,但是观察下线的kv节点上leader数并没有减少。
region数进行手动移除,operator add transfer-region,这样操作可以吗?
4.第三步我看网上说不建议手动移除,要等自动下线,但是目前下线速度巨慢,怎么排查,或者更改下参数调整下。
节点都写满了,一字节也没了是吧?那没法动了啊。即使迁移region出去,给rocksdb下的是delete命令,实际上rocksdb也是追加数据,也需要磁盘空间的。
raft节点之间来回交互也需要append raftlog,也需要磁盘空间。
你这个磁盘写满的节点大概率是没救了。看看上面的region是不是在其他region上都有大多数副本,都有的话就物理删除就行了。
如果数据很重要,先停机把128G的数据复制到其他硬盘比较大的机器上,启动tikv。这时候可能会因为ip地址之类的报错,如果要这样做的话,提前查查怎么把pd里面的store的元信息改改。
普罗米修斯
14
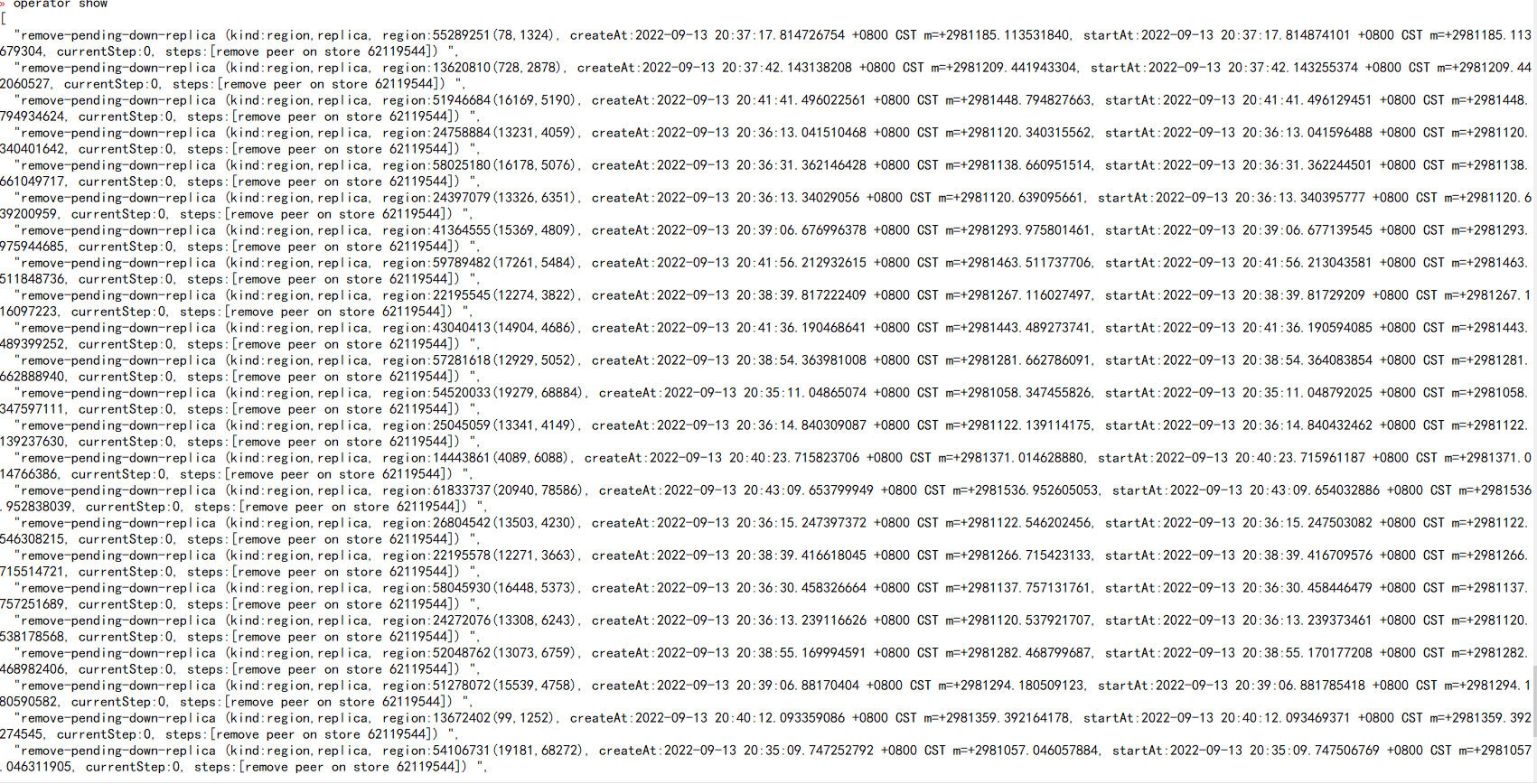
物理删除保险吗,我看现在集群在这个down的kv节点上做remove-pending-down-replica 操作,这个有什么作用?
物理删除的前提是你每个region都有正常的2副本,这样才算保险。
这个remove-pending-down-replica 没搜到相关信息,不清楚具体逻辑。
普罗米修斯
16
手动移除下线节点中的peer已将下线,但是现在出现了新的问题。数据库偶尔可以读,但是不可写入。
查看tidb日志报**[error="[tikv:9005]Region is unavailable"]**
[2022/09/15 13:48:42.692 +08:00] [WARN] [session.go:960] [“run statement error”] [conn=158283] [schemaVersion=154442] [error="[tikv:9005]Region is unavailable"] [errorVerbose="[tikv:9005]Region is unavailable\ngithub.com/pingcap/errors.AddStack\
\t/home/jenkins/workspace/release_tidb_3.0/go/pkg/mod/github.com/pingcap/errors@v0.11.4/errors.go:174\
github.com/pingcap/errors.Trace\
\t/home/jenkins/workspace/release_tidb_3.0/go/pkg/mod/github.com/pingcap/errors@v0.11.4/juju_adaptor.go:15\
github.com/pingcap/tidb/store/tikv.(*RegionRequestSender).onRegionError\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/region_request.go:234\ngithub.com/pingcap/tidb/store/tikv.(*RegionRequestSender).SendReqCtx\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/region_request.go:129\ngithub.com/pingcap/tidb/store/tikv.(*RegionRequestSender).SendReq\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/region_request.go:72\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetSingleRegion\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:168\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetKeysByRegions\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:130\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetSingleRegion\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:181\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetKeysByRegions\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:130\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetSingleRegion\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:181\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetKeysByRegions\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:130\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetSingleRegion\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:181\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetKeysByRegions\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:130\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetSingleRegion\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:181\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetKeysByRegions\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:130\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetSingleRegion\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:181\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetKeysByRegions\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:130\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetSingleRegion\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:181\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetKeysByRegions\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:130\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetSingleRegion\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:181\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetKeysByRegions\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:130\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetSingleRegion\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:181\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetKeysByRegions\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:130\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetSingleRegion\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:181\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetKeysByRegions\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:130\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetSingleRegion\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:181\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetKeysByRegions\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:130\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetSingleRegion\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:181\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetKeysByRegions\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:130\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetSingleRegion\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:181\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetKeysByRegions\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:130\ngithub.com/pingcap/tidb/store/tikv.(*tikvSnapshot).batchGetSingleRegion\
\t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/snapshot.go:181"] [session="{\
“currDBName”: “wtlivedbrds_xa”,\
“id”: 158283,\
“status”: 2,\
“strictMode”: true,\
“user”: {\
“Username”: “root”,\
“Hostname”: “192.168.90.208”,\
“CurrentUser”: false,\
“AuthUsername”: “root”,\
“AuthHostname”: “%”\
}\
}"]
看看这个region几个副本,都在哪里,是不是正常的。
普罗米修斯
18
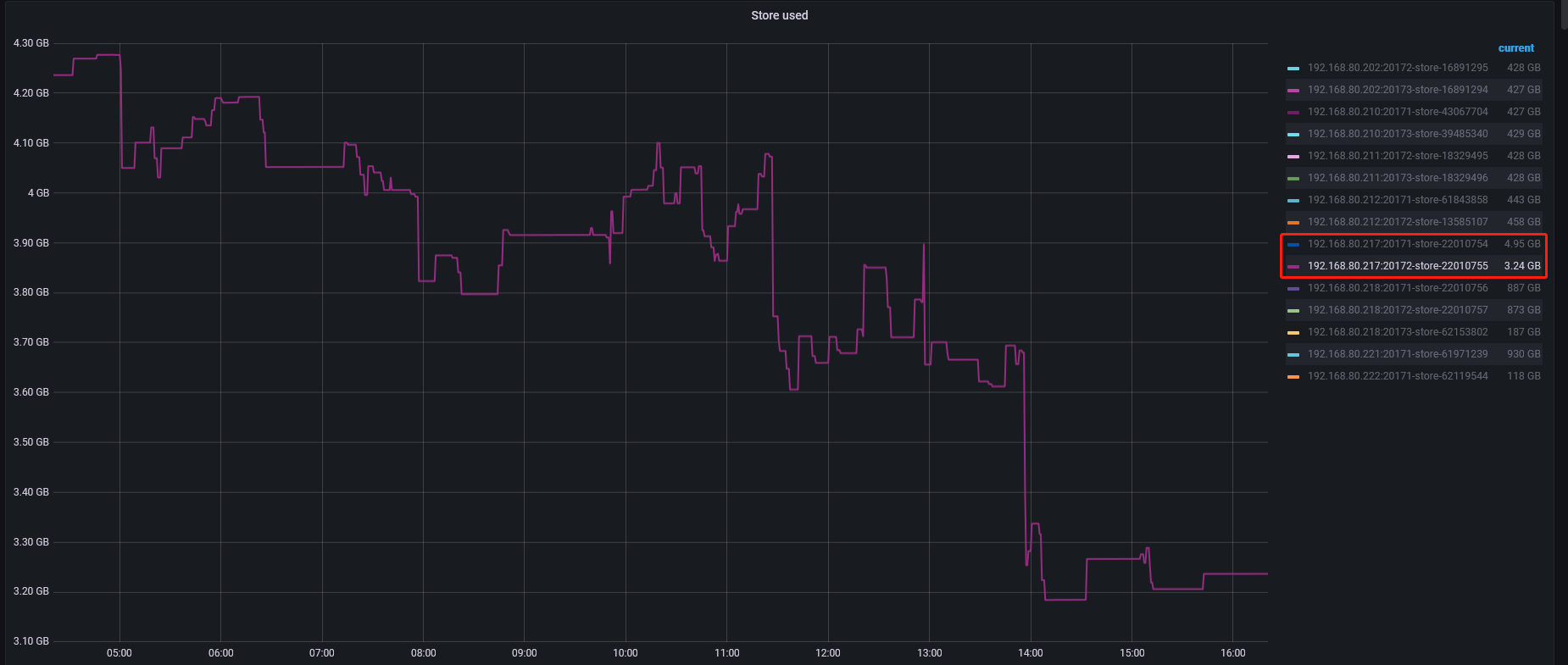
集群中目前还有两个store处于down的状态,因为磁盘写满爆盘,目前region-health图表中down-peer-region-count和pending-peer-region-count的数量从67.5K降到4.59k基本不下降了,miss_peer_region_count的数据目前在急剧下降,是否等平衡完数据库可恢复正常。
没有强制删除是吧?只是因为store down了两个,导致集群起不来是吧?
如果这样的话,那就耐心等着吧。
查region可以用tidb-ctl查,查每个表的region都是哪几个。然后看看这些region是不是正常。
另外,你磁盘爆满就没别的办法吗?复制出来数据去其他机器上启动tikv不行吗?只是ip换了下,应该有办法恢复。具体办法等你想这样做的时候再找找。
扩磁盘也有办法扩啊,lvm的话加就行了。实在不行用nfs挂载远程目录。把128G的data目录复制到远程磁盘上。
方法有很多。