【 TiDB 版本】v6.0.0
【 集群参数 】
# 关闭集群的热点调度和region的split
tiup ctl:v6.0.0 pd config set leader-schedule-limit 0
tiup ctl:v6.0.0 pd config set region-schedule-limit 0
tiup ctl:v6.0.0 pd config set hot-region-schedule-limit 0
tiup ctl:v6.0.0 pd config set hot-region-cache-hits-threshold 60
tiup ctl:v6.0.0 pd config set replica-schedule-limit 0
tiup ctl:v6.0.0 pd config set merge-schedule-limit 0
set config tikv split.qps-threshold=1000000;
set config tikv split.byte-threshold=10000000;
【遇到的问题】
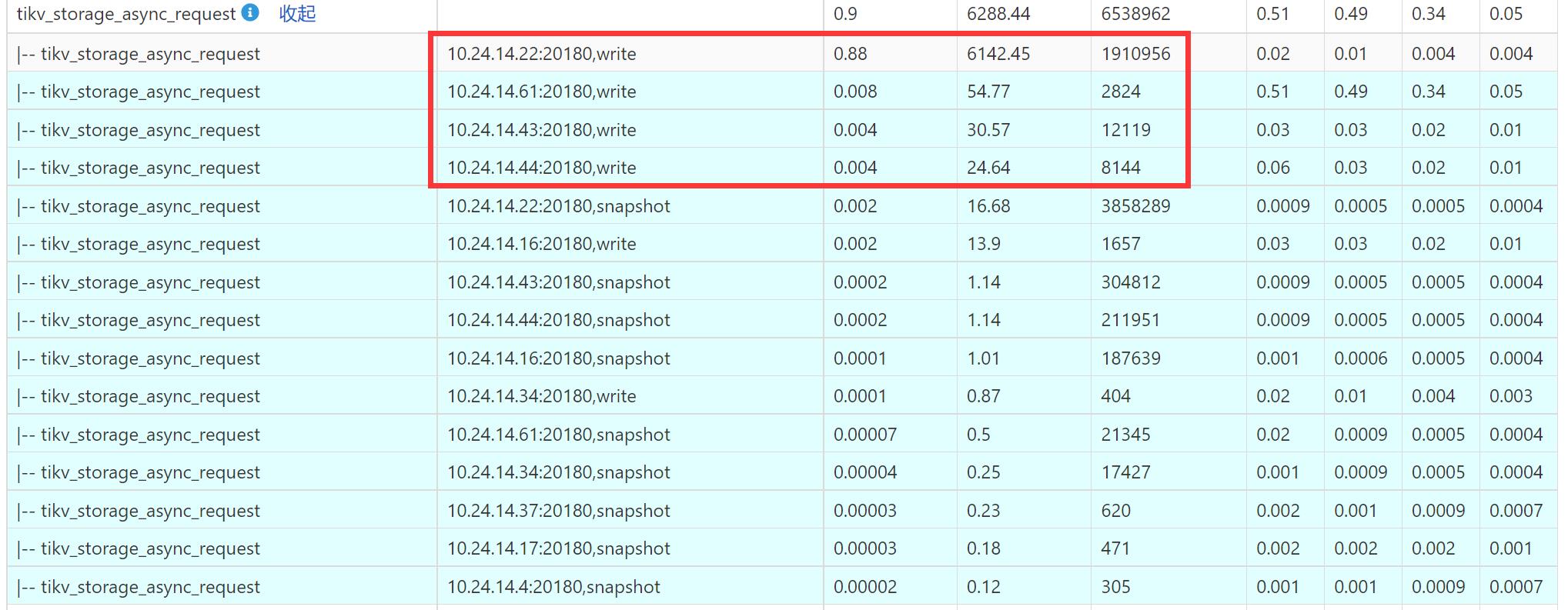
在跑高冲突的实验时,对单行数据进行select for update,所有query落在同一个region,观察tidb dashboard的统计结果,可以看到region leader所在节点(10.24.14.22)的tikv_storage_async_request请求数量很高。
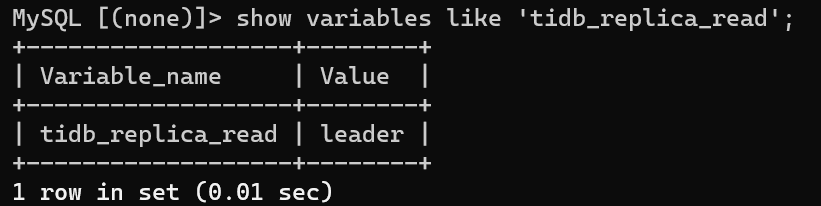
我的疑问是为什么其他节点也有write和snapshot的请求?