【 TiDB 使用环境`】生产
【 TiDB 版本】5.4.2
【遇到的问题】
凌晨备份日志异常 发现是 下面的报错:
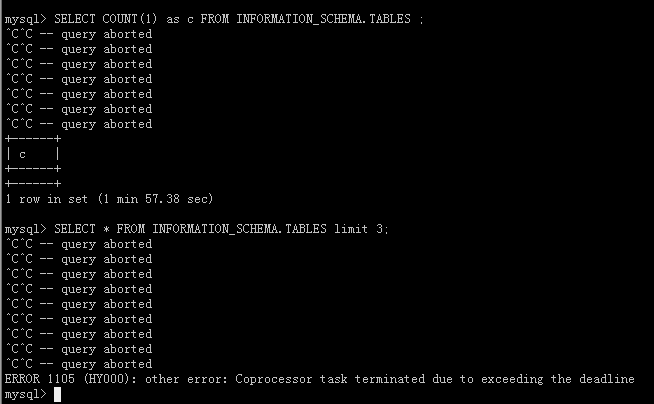
dump failed: sql: SELECT COUNT(1) as c FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE=‘SEQUENCE’: invalid connection
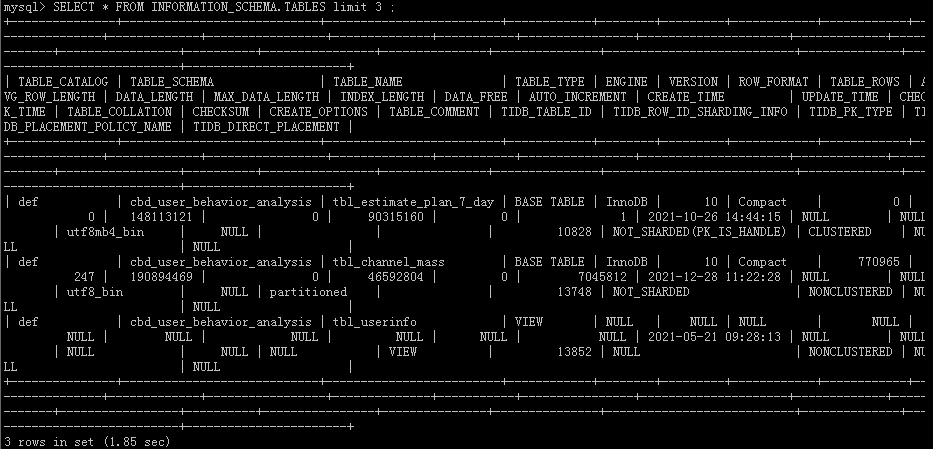
尝试查表发现 都没响应了 。
SELECT * FROM INFORMATION_SCHEMA.TABLES limit 3;
SELECT count(1) FROM INFORMATION_SCHEMA.TABLES ;
[root@xxx-xxx223 tidblog]# grep terminated tidb.log |grep -i erro | more
[2022/09/10 10:24:09.397 +08:00] [WARN] [coprocessor.go:970] [“other error”] [conn=484791] [txnStartTS=435886730364583943] [regionID
=36387611] [storeAddr=xxx.xx.xx.158:20160] [error=“other error: Coprocessor task terminated due to exceeding the deadline”]
[2022/09/10 10:24:09.398 +08:00] [INFO] [conn.go:1117] [“command dispatched failed”] [conn=484791] [connInfo=“id:484791, addr:127.0.
0.1:58723 status:10, collation:utf8_general_ci, user:tidbdba”] [command=Query] [status=“inTxn:0, autocommit:1”] [sql=“SELECT * FROM
INFORMATION_SCHEMA.TABLES limit 3”] [txn_mode=PESSIMISTIC] [err=“other error: Coprocessor task terminated due to exceeding the deadl
ine
github.com/pingcap/tidb/store/copr.(*copIteratorWorker).handleCopResponse
\t/home/jenkins/agent/workspace/build-common/go/src/
github.com/pingcap/tidb/store/copr/coprocessor.go:969
github.com/pingcap/tidb/store/copr.(*copIteratorWorker).handleTaskOnce
\t/ho
me/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/store/copr/coprocessor.go:784
github.com/pingcap/tidb/store/
copr.(*copIteratorWorker).handleTask
\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/store/copr/coproce
ssor.go:668
github.com/pingcap/tidb/store/copr.(*copIteratorWorker).run
\t/home/jenkins/agent/workspace/build-common/go/src/github
.com/pingcap/tidb/store/copr/coprocessor.go:410
runtime.goexit
\t/usr/local/go/src/runtime/asm_amd64.s:1371”]
【复现路径】做过哪些操作出现的问题
【问题现象及影响】
系统表不可用了 ,不知道会有什么影响 ,生产系统 。
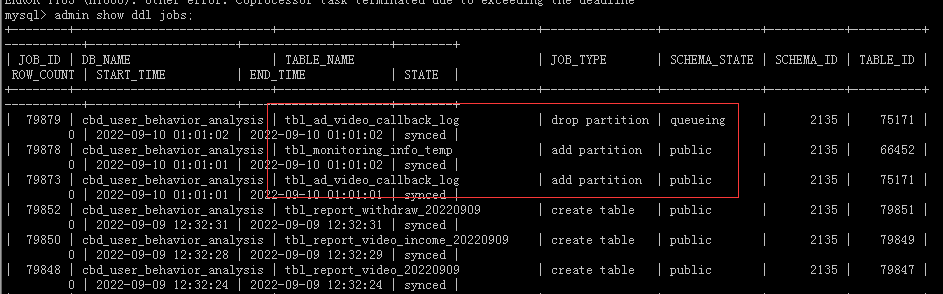
凌晨1点多 DDL 还正常 。现在不太改操作DDL 11:30 会有一批DDL操作。