【版本】6.1.0 arm
【步骤】
创建 t1 (id int primary key, name varchar);
insert into t1 values(1, “xiaohong”);
创建 t2 (id int primary key, name varchar);
insert into t2 values(100, “hha”);
找出 t1 的表数据的 region leader 所在的 store,假设 tikv1.
tx1, begin;
tx1: update t1 set name = “xiaoming” where name = “xiaohong”; 让 tx1 持有内存悲观锁.
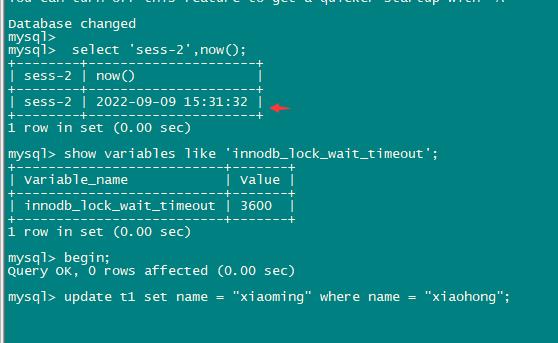
tx2:session 2 执行 update t1 set name = “xiaohua” where name = “xiaohong”; 将会被阻塞
kill tikv1; 让 tx1 的锁丢失。
等待一定时间,session 2执行成功。
txn3: session3 执行 update t2 set name = “xxxx” where name=“hha”; 顺利提交。
tx1: 执行 update t2 set name = “yyy”; 刷新 tx1 的 forupdatets 使得其 > tx2 的commitTs.
tx1 执行 commit,检查能否提交成功。
【结果】
1、会话1 更新t1 找到leader
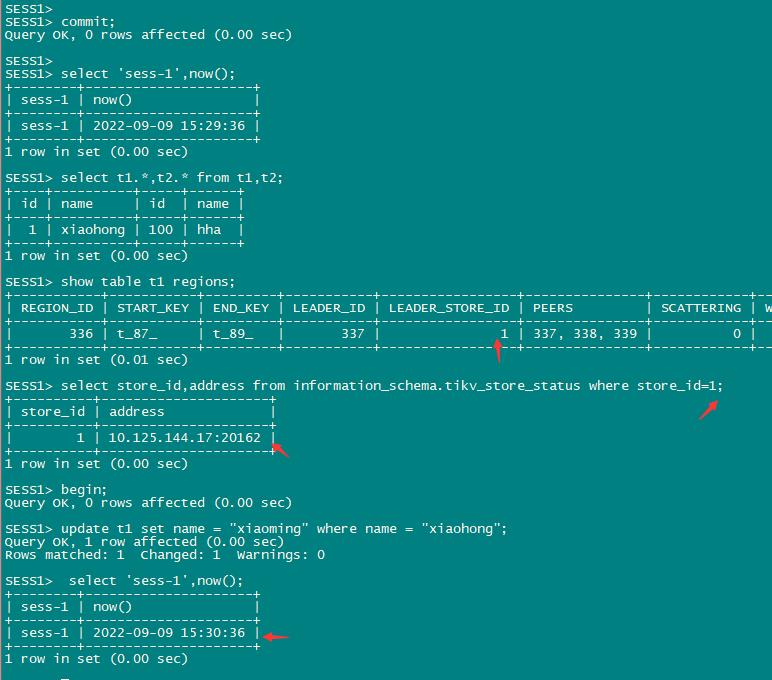
2、会话2更新相同行 ,阻塞
3、leader上kill tikv
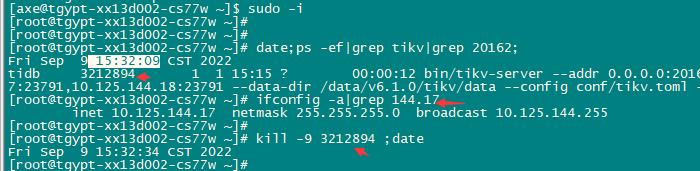
kill leader tikv后内存锁并没有丢失,会话2一直处于阻塞状态
参数配置:

系统视图:

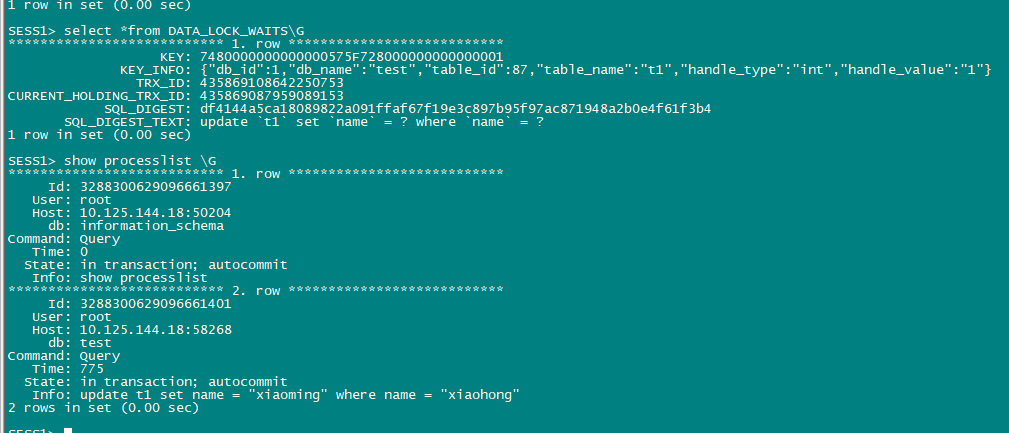
4、会话1commit后 会话2执行成功

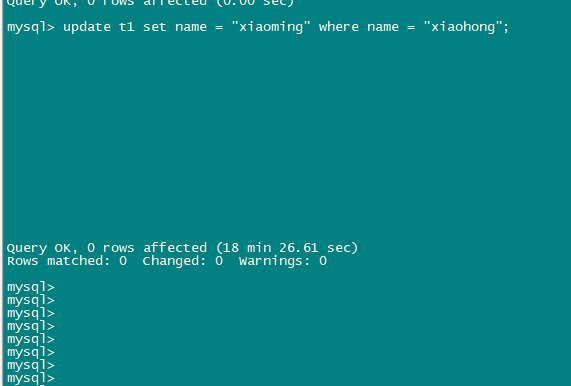
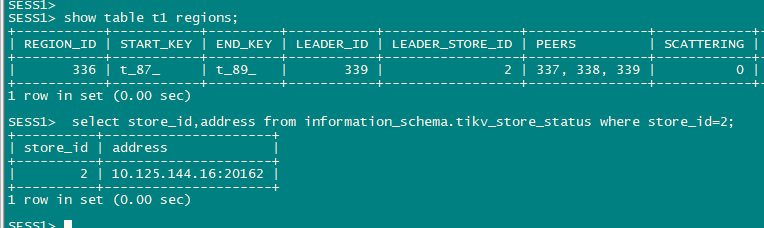
leader已经是store 2了
【问题】
1、 leader tikv节点kill 内存悲观锁不释放 不丢失(貌似被同步了,切到了store 2),被阻塞会话一直阻塞不符合预期( 应该 没kill错leader)
2、有什么更直观的方式能够看到当前锁的持有者等相关信息?