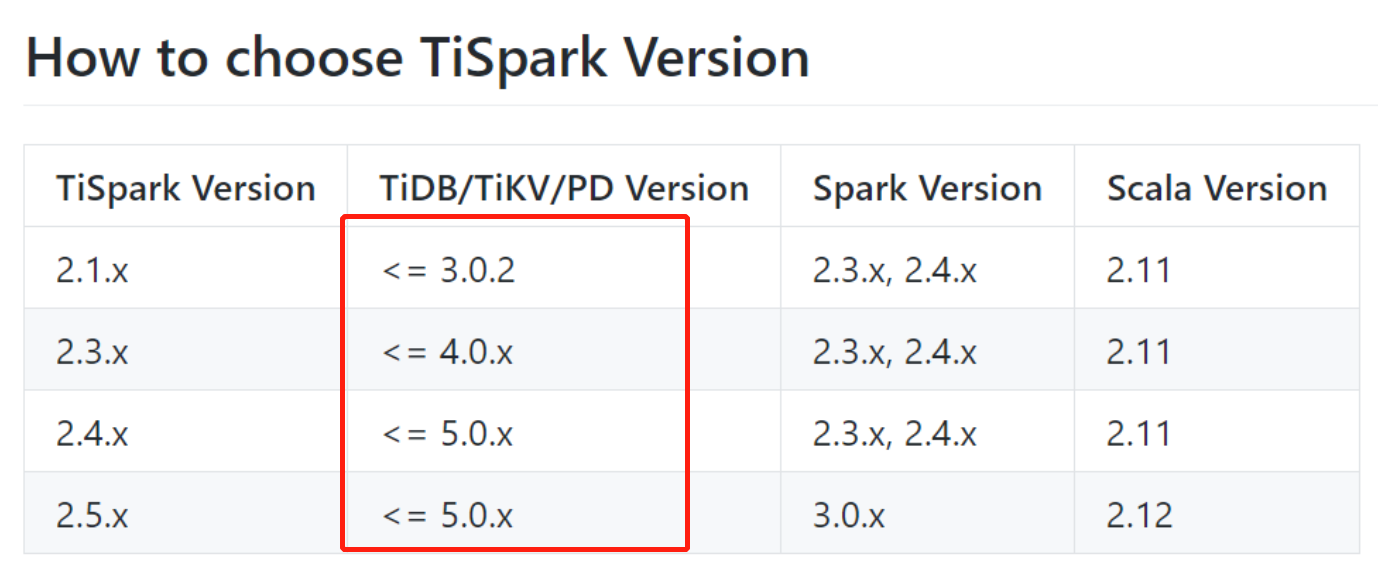
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
[TiDB 版本]
v5.0.1
[问题描述]
使用TiSpark进行增量更新,偶发性报错:com.pingcap.tikv.exception.GrpcException: Request range exceeds bound或者Region not exist for key
[复现步骤]
1.使用TiSpark进行数据的增量更新,
df.write
.format(“tidb”)
.mode(SaveMode.Overwrite)
.option(“replace”,“true”)
.option(“table”,outputTable)
.save()
2.进行count统计后,报错如下:
sc.table(tableName).count()
[错误日志]
情况一:
21/05/31 03:01:16.706 CST task-result-getter-3 ERROR TaskSetManager: Task 67 in stage 3390.0 failed 4 times; aborting job
21/05/31 03:01:16.720 CST pool-3-thread-3 ERROR JobManagerActor: Got NonFatal Exception:
org.apache.spark.SparkException: Job aborted due to stage failure: Task 67 in stage 3390.0 failed 4 times, most recent failure: Lost task 67.3 in stage 3390.0 (TID 84711) (10.244.0.192 executor 0): com.pingcap.tikv.exception.TiClientInternalException: Error reading regi
on:
at com.pingcap.tikv.operation.iterator.DAGIterator.doReadNextRegionChunks(DAGIterator.java:189)
at com.pingcap.tikv.operation.iterator.DAGIterator.readNextRegionChunks(DAGIterator.java:166)
at com.pingcap.tikv.operation.iterator.DAGIterator.hasNext(DAGIterator.java:112)
at org.apache.spark.sql.tispark.TiRowRDD$$anon$1.hasNext(TiRowRDD.scala:69)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.columnartorow_nextBatch_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.agg_doAggregateWithoutKey_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:755)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:458)
at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:132)
at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:497)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1439)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:500)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.util.concurrent.ExecutionException: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at com.pingcap.tikv.operation.iterator.DAGIterator.doReadNextRegionChunks(DAGIterator.java:184)
... 20 more
Caused by: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:232)
at com.pingcap.tikv.operation.iterator.DAGIterator.lambda$submitTasks$1(DAGIterator.java:90)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
... 3 more
Caused by: com.pingcap.tikv.exception.GrpcException: Request range exceeds bound, request range:[7480000000000000FFF65F728000000004FF25B2210000000000FB, end:7480000000000000FFF65F728000000004FF287AFB0000000000FB), physical bound:[7480000000000000FFF65F728000000004FF2761
CD0000000000FB, 7480000000000000FFF65F728000000004FF287AFB0000000000FB)
at com.pingcap.tikv.region.RegionStoreClient.handleCopResponse(RegionStoreClient.java:717)
at com.pingcap.tikv.region.RegionStoreClient.coprocess(RegionStoreClient.java:664)
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:219)
... 7 more
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2253)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2202)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2201)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2201)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1078)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1078)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1078)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2440)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2382)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2371)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:868)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2202)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2223)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2242)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2267)
at org.apache.spark.rdd.RDD.$anonfun$collect$1(RDD.scala:1030)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:414)
at org.apache.spark.rdd.RDD.collect(RDD.scala:1029)
at org.apache.spark.sql.execution.SparkPlan.executeCollect(SparkPlan.scala:390)
at org.apache.spark.sql.Dataset.$anonfun$count$1(Dataset.scala:3006)
at org.apache.spark.sql.Dataset.$anonfun$count$1$adapted(Dataset.scala:3005)
at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3687)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:103)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:163)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:90)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:772)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3685)
at org.apache.spark.sql.Dataset.count(Dataset.scala:3005)
at com.nascent.quantbi.ingest.IngestJob$.ingestData(IngestJob.scala:134)
at com.nascent.quantbi.ingest.IngestJob$.run(IngestJob.scala:63)
at com.nascent.quantbi.etl.EtlDataJob$.runSparkJob(EtlDataJob.scala:33)
at org.apache.spark.sql.SparkSQLJob.runJob(SparkJobSessionFactory.scala:82)
at org.apache.spark.sql.SparkSQLJob.runJob$(SparkJobSessionFactory.scala:76)
at com.nascent.quantbi.etl.EtlDataJob$.runJob(EtlDataJob.scala:25)
at spark.jobserver.JobManagerActor.$anonfun$getJobFuture$2(JobManagerActor.scala:363)
at scala.concurrent.Future$.$anonfun$apply$1(Future.scala:659)
at scala.util.Success.$anonfun$map$1(Try.scala:255)
at scala.util.Success.map(Try.scala:213)
at scala.concurrent.Future.$anonfun$map$1(Future.scala:292)
at scala.concurrent.impl.Promise.liftedTree1$1(Promise.scala:33)
at scala.concurrent.impl.Promise.$anonfun$transform$1(Promise.scala:33)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:64)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: com.pingcap.tikv.exception.TiClientInternalException: Error reading region:
at com.pingcap.tikv.operation.iterator.DAGIterator.doReadNextRegionChunks(DAGIterator.java:189)
at com.pingcap.tikv.operation.iterator.DAGIterator.readNextRegionChunks(DAGIterator.java:166)
at com.pingcap.tikv.operation.iterator.DAGIterator.hasNext(DAGIterator.java:112)
at org.apache.spark.sql.tispark.TiRowRDD$$anon$1.hasNext(TiRowRDD.scala:69)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.columnartorow_nextBatch_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.agg_doAggregateWithoutKey_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:755)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:458)
at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:132)
at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:497)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1439)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:500)
... 3 more
Caused by: java.util.concurrent.ExecutionException: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at com.pingcap.tikv.operation.iterator.DAGIterator.doReadNextRegionChunks(DAGIterator.java:184)
... 20 more
Caused by: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:232)
at com.pingcap.tikv.operation.iterator.DAGIterator.lambda$submitTasks$1(DAGIterator.java:90)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
... 3 more
Caused by: com.pingcap.tikv.exception.GrpcException: Request range exceeds bound, request range:[7480000000000000FFF65F728000000004FF25B2210000000000FB, end:7480000000000000FFF65F728000000004FF287AFB0000000000FB), physical bound:[7480000000000000FFF65F728000000004FF2761
CD0000000000FB, 7480000000000000FFF65F728000000004FF287AFB0000000000FB)
at com.pingcap.tikv.region.RegionStoreClient.handleCopResponse(RegionStoreClient.java:717)
at com.pingcap.tikv.region.RegionStoreClient.coprocess(RegionStoreClient.java:664)
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:219)
... 7 more
情况二:
21/05/31 05:02:41.091 CST task-result-getter-1 ERROR TaskSetManager: Task 5 in stage 3691.0 failed 4 times; aborting job
21/05/31 05:02:41.093 CST pool-3-thread-2 ERROR JobManagerActor: Got NonFatal Exception:
org.apache.spark.SparkException: Job aborted due to stage failure: Task 5 in stage 3691.0 failed 4 times, most recent failure: Lost task 5.3 in stage 3691.0 (TID 86740) (10.244.0.191 executor 1): com.pingcap.tikv.exception.TiClientInternalException: Error reading region
:
at com.pingcap.tikv.operation.iterator.DAGIterator.doReadNextRegionChunks(DAGIterator.java:189)
at com.pingcap.tikv.operation.iterator.DAGIterator.readNextRegionChunks(DAGIterator.java:166)
at com.pingcap.tikv.operation.iterator.DAGIterator.hasNext(DAGIterator.java:112)
at org.apache.spark.sql.tispark.TiRowRDD$$anon$1.hasNext(TiRowRDD.scala:69)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.columnartorow_nextBatch_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.agg_doAggregateWithoutKey_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:755)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:458)
at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:132)
at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:497)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1439)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:500)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.util.concurrent.ExecutionException: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at com.pingcap.tikv.operation.iterator.DAGIterator.doReadNextRegionChunks(DAGIterator.java:184)
... 20 more
Caused by: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:232)
at com.pingcap.tikv.operation.iterator.DAGIterator.lambda$submitTasks$1(DAGIterator.java:90)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
... 3 more
Caused by: com.pingcap.tikv.exception.GrpcException: retry is exhausted.
at com.pingcap.tikv.util.ConcreteBackOffer.doBackOffWithMaxSleep(ConcreteBackOffer.java:148)
at com.pingcap.tikv.util.ConcreteBackOffer.doBackOff(ConcreteBackOffer.java:119)
at com.pingcap.tikv.util.RangeSplitter.splitRangeByRegion(RangeSplitter.java:190)
at com.pingcap.tikv.region.RegionStoreClient.handleCopResponse(RegionStoreClient.java:696)
at com.pingcap.tikv.region.RegionStoreClient.coprocess(RegionStoreClient.java:664)
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:219)
... 7 more
Caused by: com.pingcap.tikv.exception.TiClientInternalException: Region not exist for key:*
at com.pingcap.tikv.region.RegionManager.getRegionStorePairByKey(RegionManager.java:104)
at com.pingcap.tikv.util.RangeSplitter.splitRangeByRegion(RangeSplitter.java:182)
... 10 more
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2253)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2202)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2201)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2201)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1078)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1078)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1078)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2440)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2382)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2371)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:868)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2202)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2223)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2242)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2267)
at org.apache.spark.rdd.RDD.$anonfun$collect$1(RDD.scala:1030)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:414)
at org.apache.spark.rdd.RDD.collect(RDD.scala:1029)
at org.apache.spark.sql.execution.SparkPlan.executeCollect(SparkPlan.scala:390)
at org.apache.spark.sql.Dataset.$anonfun$count$1(Dataset.scala:3006)
at org.apache.spark.sql.Dataset.$anonfun$count$1$adapted(Dataset.scala:3005)
at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3687)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:103)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:163)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:90)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:772)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3685)
at org.apache.spark.sql.Dataset.count(Dataset.scala:3005)
at com.nascent.quantbi.ingest.IngestJob$.ingestData(IngestJob.scala:134)
at com.nascent.quantbi.ingest.IngestJob$.run(IngestJob.scala:63)
at com.nascent.quantbi.etl.EtlDataJob$.runSparkJob(EtlDataJob.scala:33)
at org.apache.spark.sql.SparkSQLJob.runJob(SparkJobSessionFactory.scala:82)
at org.apache.spark.sql.SparkSQLJob.runJob$(SparkJobSessionFactory.scala:76)
at com.nascent.quantbi.etl.EtlDataJob$.runJob(EtlDataJob.scala:25)
at spark.jobserver.JobManagerActor.$anonfun$getJobFuture$2(JobManagerActor.scala:363)
at scala.concurrent.Future$.$anonfun$apply$1(Future.scala:659)
at scala.util.Success.$anonfun$map$1(Try.scala:255)
at scala.util.Success.map(Try.scala:213)
at scala.concurrent.Future.$anonfun$map$1(Future.scala:292)
at scala.concurrent.impl.Promise.liftedTree1$1(Promise.scala:33)
at scala.concurrent.impl.Promise.$anonfun$transform$1(Promise.scala:33)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:64)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: com.pingcap.tikv.exception.TiClientInternalException: Error reading region:
at com.pingcap.tikv.operation.iterator.DAGIterator.doReadNextRegionChunks(DAGIterator.java:189)
at com.pingcap.tikv.operation.iterator.DAGIterator.readNextRegionChunks(DAGIterator.java:166)
at com.pingcap.tikv.operation.iterator.DAGIterator.hasNext(DAGIterator.java:112)
at org.apache.spark.sql.tispark.TiRowRDD$$anon$1.hasNext(TiRowRDD.scala:69)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.columnartorow_nextBatch_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.agg_doAggregateWithoutKey_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:755)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:458)
at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:132)
at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:497)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1439)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:500)
... 3 more
Caused by: java.util.concurrent.ExecutionException: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at com.pingcap.tikv.operation.iterator.DAGIterator.doReadNextRegionChunks(DAGIterator.java:184)
... 20 more
Caused by: com.pingcap.tikv.exception.RegionTaskException: Handle region task failed:
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:232)
at com.pingcap.tikv.operation.iterator.DAGIterator.lambda$submitTasks$1(DAGIterator.java:90)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
... 3 more
Caused by: com.pingcap.tikv.exception.GrpcException: retry is exhausted.
at com.pingcap.tikv.util.ConcreteBackOffer.doBackOffWithMaxSleep(ConcreteBackOffer.java:148)
at com.pingcap.tikv.util.ConcreteBackOffer.doBackOff(ConcreteBackOffer.java:119)
at com.pingcap.tikv.util.RangeSplitter.splitRangeByRegion(RangeSplitter.java:190)
at com.pingcap.tikv.region.RegionStoreClient.handleCopResponse(RegionStoreClient.java:696)
at com.pingcap.tikv.region.RegionStoreClient.coprocess(RegionStoreClient.java:664)
at com.pingcap.tikv.operation.iterator.DAGIterator.process(DAGIterator.java:219)
... 7 more
Caused by: com.pingcap.tikv.exception.TiClientInternalException: Region not exist for key:*
at com.pingcap.tikv.region.RegionManager.getRegionStorePairByKey(RegionManager.java:104)
at com.pingcap.tikv.util.RangeSplitter.splitRangeByRegion(RangeSplitter.java:182)
... 10 more
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。