zhimadi
(Zhimadi)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】v4.0.9
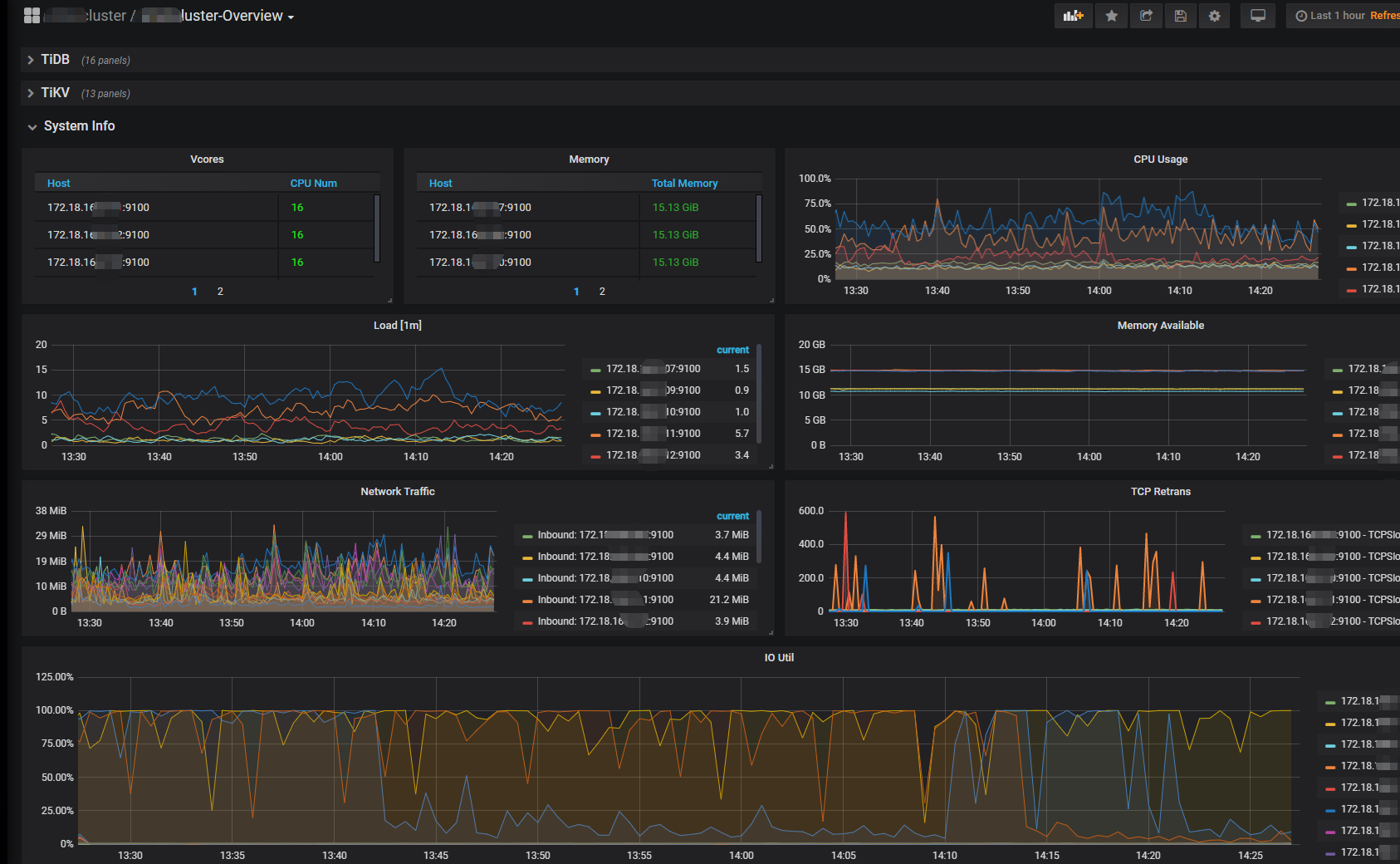
【遇到的问题】集群有3个tikv节点,通过监控面板常看到:单个tikv的cpu负载高于其他两个,单个tikv的IO一直在100%的情况。
【复现路径】做过哪些操作出现的问题
【问题现象及影响】
造成系统不稳定,一条慢sql就容易发生雪崩事件。最近发生其中一个tikv的CPU使用90%+以上,用户使用系统卡顿,导致产生很多脏数据。尝试restart单个tikv节点也无效。需要重启整 个集群才恢复生产。
【附件】
请提供各个组件的 version 信息,如 cdc/tikv,可通过执行 cdc version/tikv-server --version 获取。
xfworld
(魔幻之翼)
2
负载很高的哪个 tikv 节点,所持有的 region,是不是高于另外两个呢?
zhimadi
(Zhimadi)
3
请问 tikv 节点,所持有的 region 指标是在哪里查看的?如果是在overview->tikv里面的话,三台的region都是一样的,max:11.0K;current:11.0K
xfworld
(魔幻之翼)
4
通过 prometheus 查阅 tikv 的指标就可以拉
或者你用 PD-cli 的命令行查看也可以
其实就一个问题: 资源是否均衡? 如果不均衡是否是热点问题导致的
1 个赞
xfworld
(魔幻之翼)
5
那你自己搜下 asktug 关于热点问题的解决方式和路径,对着查一下
zhimadi
(Zhimadi)
7
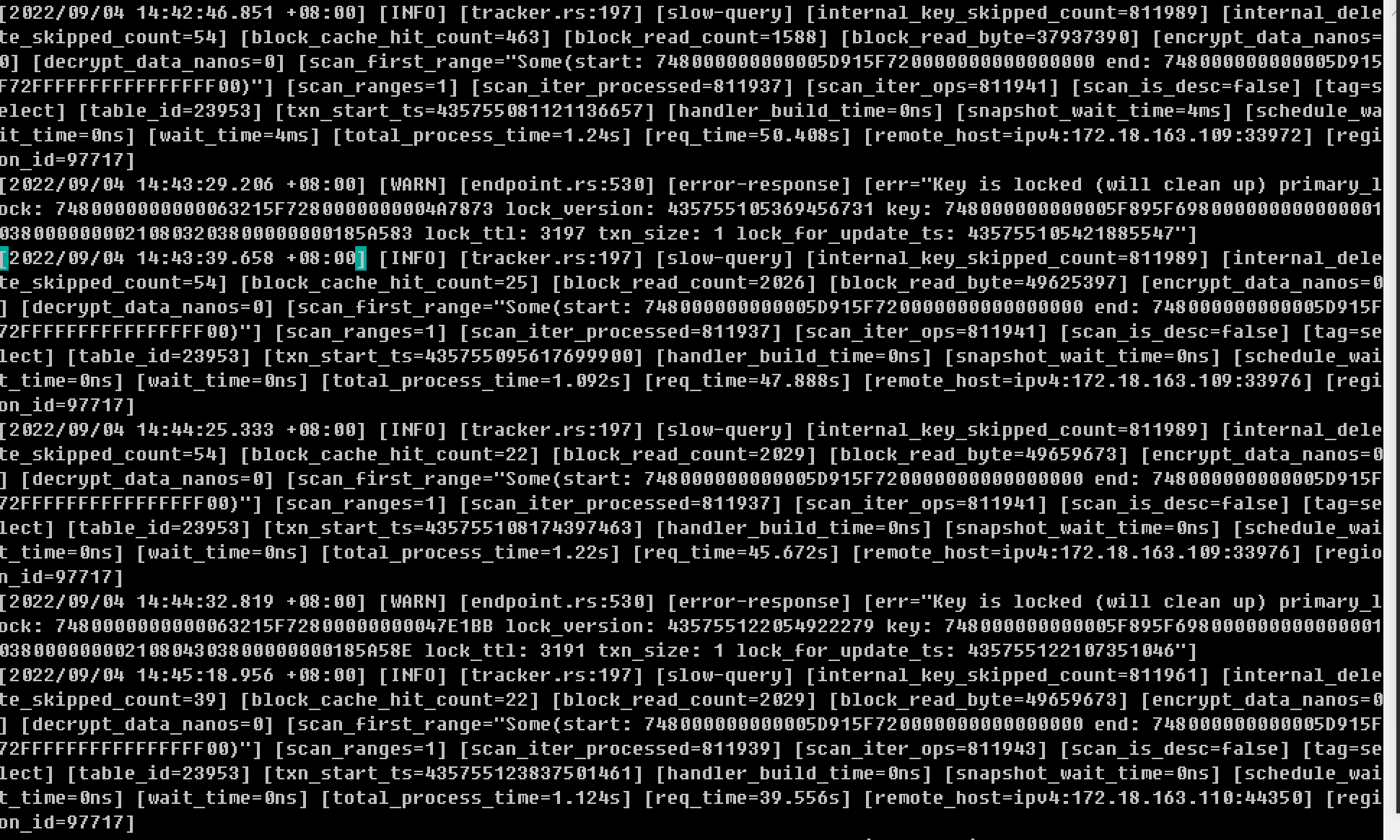
一个查看一下慢sql 第二拒绝所有慢sql的执行 第三升级一下配置
set @@global.MAX_EXECUTION_TIME=10000
1 个赞
zhimadi
(Zhimadi)
11
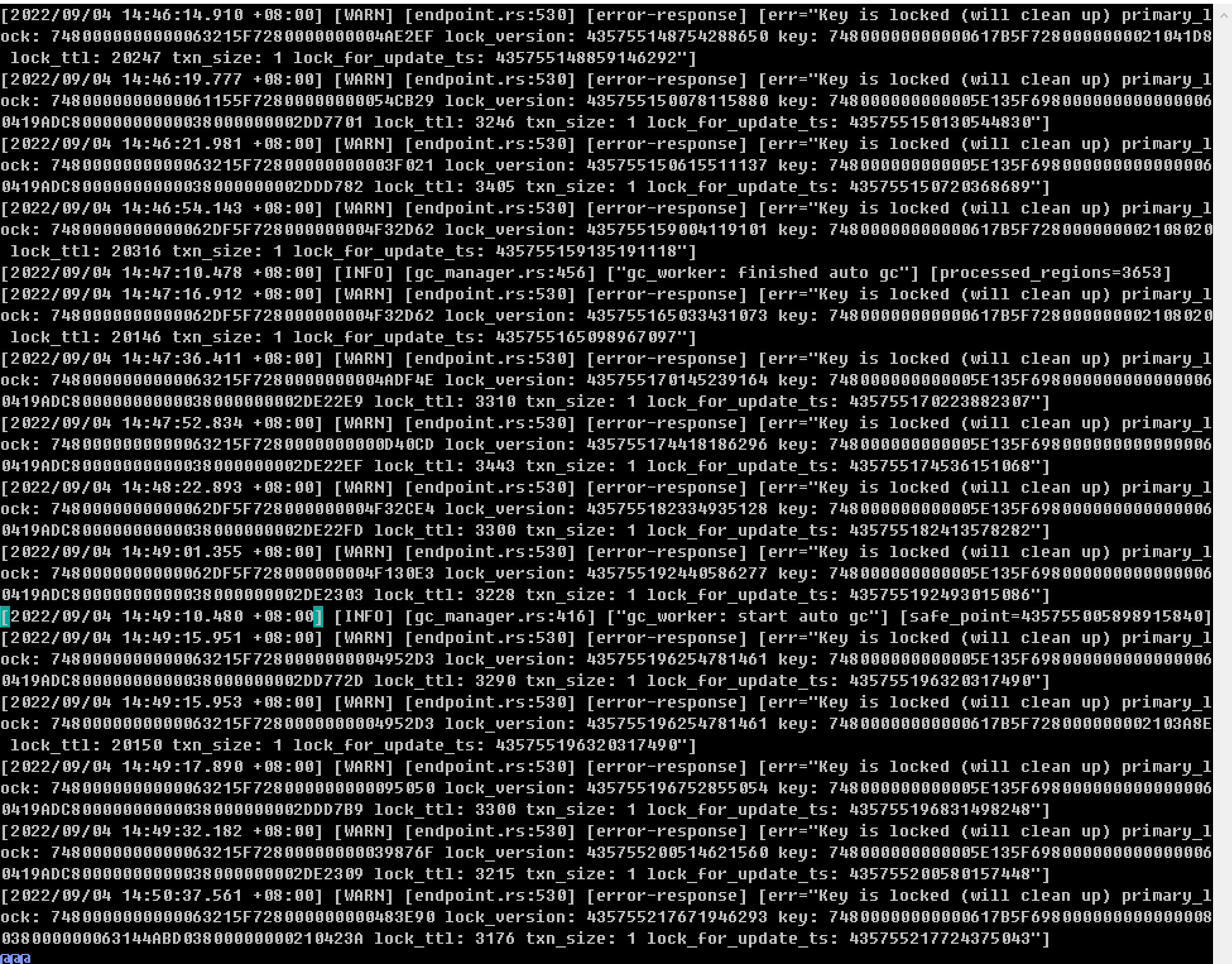
是的。上周日事故发生时第一时间查看慢sql,把怀疑的都加索引和作其他优化处理。然后给tidb翻倍了CPU和内存。MAX_EXECUTION_TIME在应用上设session级别的。因为analyze和加索引不止10秒。可是经过这几天的观察,感觉问题依然存在,保不准下个业备高峰又触发。
xfworld
(魔幻之翼)
12
有关系,如果你有高性能的需求,建议考虑采用 聚簇索引的方式
聚簇索引是后期才有的方案,你目前用的版本应该还不支持,但是可以考虑模拟
- 单主键列,并且类型为 bigint
- 主键为 auto_random 类型
如果不方便修改,可以对目前的 region 进行打散,可以减少热点问题。
如果数据量很大的情况下,还是建议采用聚簇索引的方式… 少死点脑细胞…
1 个赞
wakaka
(Wakaka)
13
优化后慢sql还有很多吗? 看你的cpu load ioutil都很高
1 个赞
造成系统不稳定,一条慢sql就容易发生雪崩事件。最近发生其中一个tikv的CPU使用90%+以上,用户使用系统卡顿,导致产生很多脏数据。尝试restart单个tikv节点也无效。需要重启整 个集群才恢复生产
你这方法不对很容易出事故
zhimadi
(Zhimadi)
15
加了一台KV,现在4台。ioutil就下去了,不像平时那样时不时100%
zhimadi
(Zhimadi)
16
请问region如何打散;如何采用聚簇索引的方式?有教程吗?谢谢你
system
(system)
关闭
19
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。