Project 2 RaftKV
Part A Raft
AppendEntries RPC 的交互
Follower 在收到 AppendEntries request 后,会根据 prevLogIndex 和 prevLogTerm 进行 log consistency 的判断。具体来说,可能会出现以下三种情况之一:
- Index Conflict:follower 没有 index 为 prevLogIndex 的 log entry。
- Term Conflict:follower 中有 index 为 prevLogIndex 的 log entry,但其 term 不为 prevLogTerm。
- Accept:follower 中有 index 和 term 与 prevLogIndex 和 prevLogTerm 均一致的 log entry。
在我的实现中,follower 会在 AppendEntries response 中,根据不同的情况设定 Reason、NextIndex 和 ConflictTerm 三个字段:
- Reason 当且仅当 AppendEntries request 被 reject 时才设定,其值分别对应 Index Conflict 和 Term Conflict,以告知 leader 该 request 被 reject 的原因。
- NextIndex 在被 reject 和 accept 时均被设定,给 leader 以建议:下次请你给我发送从 NextIndex 开始的 log entry。
- ConflictTerm 仅在 Term Conflict 情况下被设定,其值为 follower 中位于 prevLogIndex 的 entry 的 term,正是因为这个 term 与 prevLogTerm 不一致,才发生了 Term Conflict。
对于 Index Conflict 的情况,将 NextIndex 设为 last log index + 1,这是显然的。
对于 Term Conflict 的情况,从 prevLogIndex 开始,在 follower 的 log 中往前搜索第一个 term 为ConflictTerm 的 log entry。在搜索的开始,将 NextIndex 设为 prevLogIndex。在搜索过程中,逐渐执行自减 NextIndex。当找到了这样一个 log entry 或搜索到 commit index + 1 时,停止搜索。此时的 NextIndex 的值即是 follower 要发送给 leader 的值。
在 leader 接收到 AppendEntries response 时,其首先根据 Reject 和 Reason 字段判断是否被 reject,以及因为哪种原因被 reject。对于 Index Conflict,leader 唯一能做的就是接受 follower 的建议,即使用 follower 设置的 NextIndex 进行下次发送。对于 Term Conflict,leader 首先在其 log 中从前往后搜索 term 为 ConflictTerm 的 log entry。如果找到了这样一个 log entry,则继续往后搜索,直到找到第一个 term 不为 ConflictTerm 的 log entry,将 NextIndex 设置为该 log entry 的 index;如果没有找到,则接受 follower 的建议。
关于此部分,尚存的疑问包括:
- 这里的逻辑基于 MIT 6.824 Students’ Guide to Raft 设计。对于 follower side 的搜索,我能理解,但是无法理解 leader side 的搜索。
- 在发送 log entry 时,RPC Message 中 entries 的类型是
[]*pb.Entry。RPC 发送指针的语义是什么?RPC 接收端如何重新构建指针映射?在 etcd 中,entries 的类型是[]pb.Entry,为什么 tinykv 选择使用与 etcd 不同的类型? - 在发送 log entry 时,entries 的类型是 slice of
*pb.Entry,而在 Go 中,slice 是对 array 的引用。RPC 发送引用的语义是什么?RPC 接收端如何重新建立引用关系?
Part B Fault-Tolerant Key-Value Server On Top Of Raft
tinykv 如何 handle 一个写请求
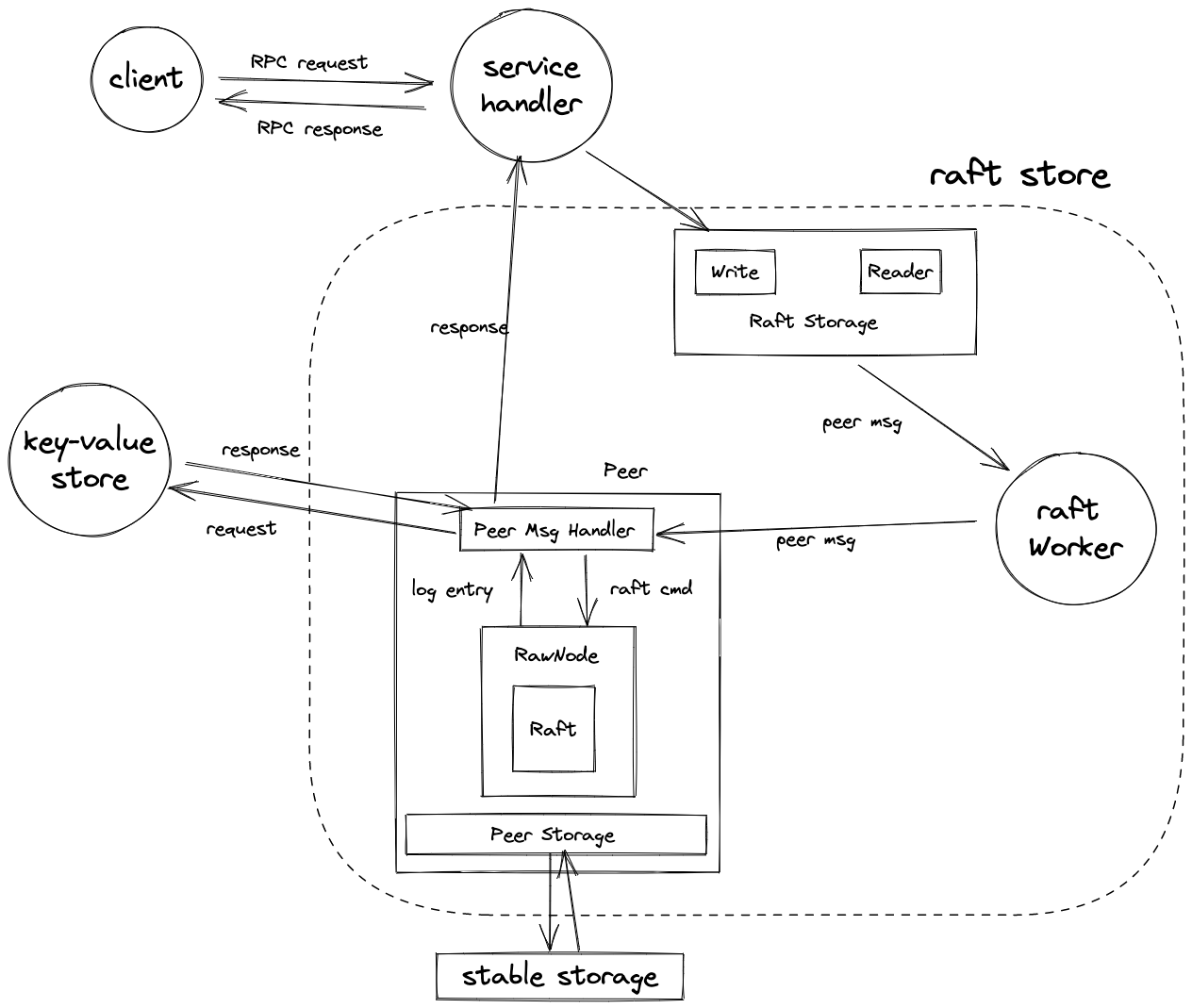
- service handler 捕获写请求,与 raft storage 层交互,调用其暴露出的
Write接口。 - raft storage 将写请求塞进一条 raft cmd 中,再被 router 包装进一条 peer msg,交付给 raft store。
- 一个 store(即 tinykv server)利用一个 raft store 完成与 raft 有关的各项工作。raft store 包含 router 及各种 worker,各司其职。由于一个 store 中含有多个 peer,分别负责不同的 region,因此需要 router 根据 region id 找到对应的 peer。此处的 region id 是 context 的一部分,由 client 发送请求时提供。
- raft store 中的 raft worker 接收到 router 传递过来的 peer msg,调用对应 peer 的 msg handler 对其进行处理。
- peer msg handler 判断出 peer msg 的类型是 raft cmd msg,取出其中的 raft cmd,并将其 marshal,以 []byte 的形式向 raw node 提出 proposal。
- raw node 负责 raft worker 与 raft 模块的交互。对于每一个收到的 proposal,raw node 将其塞进一条 log entry,递交给 raft 模块。
- 待 raft 模块 commit 这条 log entry 后,由 raw node 交付给 raft worker。
- raft worker 调用对应 peer 的
HandleRaftReady,从 log entry 中 unmarshal 出 raft cmd,再从中取出写请求,将其输入到 state machine 模块(即底层的 key-value store),得到写请求的 response。 - 该 response 经由预先设置的 call back 通道,传回给 service handler。至此,对一个写请求的 handling 完成。
- 在整个过程中,对于需要和 stable storage 交互的任务,例如持久化 log entries、持久化 raft state、restore state 等任务,由 peer storage 处理。
值得说明的点
关于 peer_storage.go 中的 Append
tinykv 对此函数的注释是 delete log entries that will never be committed 。为了理解这句话,需要了解 tinykv 关于 log entry 的持久化逻辑。
在 tinykv 中,当有新的 log entry 被 append 到 log 时,上层马上会捕获该信息,从而调用 HandleRaftReady 函数将新 append 的 log entry 进行持久化。也就是说,即使未 committed 的 log entry,也会被持久化。
由于并不是所有 log entry 最终都会被 commit,因此需要适时地丢弃这些 log entry(当然也可以选择保留,不过这些 log entry 就成了 garbage data)。那么何时是“适时”呢?考虑一个新 log entry 的持久化:
- 如果已经持久化的某个 log entry 与其一模一样,那么可以选择删掉旧的、持久化新的,也可以不删旧的、放弃持久化新的。
- 如果已经持久化的某个尚未 committed 的 log entry 与其存在冲突,即 index 一致、term 不一致,那么:
- 如果新的最终会被 commit,那么自然删掉旧的、持久化新的。
- 如果旧的最终会被 commit,那么可以选择保留旧的、放弃持久化新的,也可以选择删掉旧的、持久化新的。这是因为由于新的 log entry 不会被 commit(我们的假定),因此它终究会在某个时刻重新被旧的 log entry 所替代。
- 如果 stable storage 中尚未存在 index 与新 log entry 一致的旧 log entry,那么直接持久化新的。
注意到,新的 log entry 的 index 必定大于 commit index,因为 unstable entries 根据 stabled index + 1 确定,而存在不变量 commit index ≤ stabled index。故替换 committed log entry 的情况绝不会发生。
总结来说,只要有新的 log entry 需要持久化,我们就把旧的、与其 index 一致的 log entry 删掉(如果存在的话),之后再持久化新的。这样的逻辑转化到代码实现,为:对于每个新 log entry,利用 Set 操作,替换 index 一致的旧 log entry(如果有的话),则冲突被化解。对于所有 index 在 last new entry’s index 之后的旧 log entry (如果有的话),删除它们。
关于 WriteBatch 与 crash consistency
在 SaveReadyState 中,需要使用 write batch 记录所有写操作,再把它们 wrap 到一个 txn 中,由 badger DB 完成真正的写入操作。
txn 给了我们 crash consistency 的保证。首先要说明什么是 crash consistency。对于一系列相互间存在约束的量,如果在 crash 之前,这些约束是正确的,那么在 recovery 之后,这些约束也应该是正确的。
比如说,存在不变量 applied index ≤ commit index。假设刚刚 install 了一个非 stale 的 snapshot,那么 applied index 和 commit index 都应该更新到 snapshot index。又假设我们的代码首先对 applied index 进行更新,随后才对 commit index 进行更新。那么,如果没有 txn 对 crash consistency 的保证,则当机器在更新并持久化 applied index 之后、在更新并持久化 commit index 之前,发生了 crash,那么当机器 recovery 后,有 applied index > commit index,违反了不变量约束,则 consistency 遭到了破坏。
因此,在编写与持久化有关的代码时,对于相互之间存在关联、存在约束的量,必须使用 write batch。且需要时刻考虑“如果代码在这里 crash 了,可能会出现什么问题?会不会破坏 consistency“。
关于执行 raft cmd
HandleRaftReady 会从每个 committed log entry 抽取出 raft cmd,并执行它们。此处需要注意以下几点:
- 对于 no-op entry,其 data 为空,因此无法抽取出 raft cmd,也没有执行的必要。但是其仍然会影响 applied index,因此需要特殊处理。
- 每个 server 都需要执行 raft cmd,但是在我的实现中,只有 leader 会存储 proposal。因此 leader 和 non-leader 在执行 raft cmd 之后的行为,需要进行区分。
- 对于 snap request,需要开启一个新的 txn。注意到,snap request 对应 Storage 层的
Reader接口,其返回关于 key-value store 的一个快照,以供读取。而既然是快照,就需要放在一个 txn 中进行,利用 txn 提供的 isolation 特性。这个 txn 随后在执行 read 操作完毕后,由 service handler 关闭。另一个要说明的是,这个 txn 是和 raft cmd (可能有很多 request) 绑定的,而不是和单个 snap request 绑定的。实际上,一次Reader调用所对应的 raft cmd,只会包含一个 snap request,因此 txn 可以和 raft cmd 绑定。
关于 commit 和 apply,有几个值得注意的场景:
- 如果一个 log entry 被 commit 了,那么它最终一定会被所有 server commit。考虑一个 log entry 被 commit 后,旧 leader crash 了或者被 partition 了,那么新选出的 leader 一定是已经 append 这个 log entry 的某个 server。这是由 raft 的 Leader Completeness Safety 决定的。换句话说,相邻两个 term 的 leader 在之前的 term 时,一定在同一个 majority 中。当新 leader 调用
becomeLeader时,其会 append 一条 no-op entry,并尝试 commit 它。如果这条 no-op entry 被 commit 了,那么所有之前的 log entry(包括之前 leader commit 的 log entry)也会被同时 commit。 - 如果 client 向集群顺序发送关于同一个 key 的 Put、Get 操作,那么 raft 保证 Get 操作能够得到预期的、正确的结果。这是由 linearizability 保证的。假设在 apply Put 操作并回复 client 后,旧 leader crash 了。那么根据上一条所述,这个 Put 操作必定会被所有 server commit 并最终被 apply。即使新 leader 在尚未 apply Put 操作时,就收到了 Get 请求,由于 log entry 顺序执行,因此当 apply Get 请求时,Put 操作必定已经被执行。
- 如果旧 leader 在 apply 某个请求之后、在回复 client 之前 crash 了,那么 client 可能会重发同一个请求,则 raft 会 apply 同一个请求两次。如果这个请求是关于某个 key 的 Delete 操作,那么显然这样的行为是不正确的。raft 论文给出的解决方法是:client 端维护一个递增的计数器,在发送请求时附带这个计数器当前的值。server 端通过维护并持久化上一条请求所附带的计数器的值,判断当前的这个请求是否已经被处理。如果是,则可以选择忽略这个请求(如果是写请求);或者再回复一次(如果是读请求)。注意,只需要维护上一条请求对应的计数器的值,因为重发的这个请求一定与上一条重复的请求(在计数器的值上)相邻。
- 对于 committed log entry,每个 server 可以独立执行,但是只有 leader 才负责回复 client。但是 旧 leader 可能因为被 partition,导致集群中选举出一个新 leader。旧 leader 没有意识到新 leader 的存在,对 client 进行了回复;新 leader 按照自己的责任,也对 client 进行了回复。如果是 Get 请求,那么两次回复得到的 value 可能并不一致,显然这是不正确的。raft 作者分别在论文和代码(LogCabin)中给出了两个方案:
- 在回复 Get 请求之前,通过一轮心跳包交互,让旧 leader step down。
- 设计一个 step down 线程,每次 tick 检查 leader 上一次与每个 peer 通信的时间(在每次 RPC 交互时,更新该时间)。如果多数 peer 的上一次通信时间超过了一个 election time out,那么让 leader step down。
关于这部分,尚存的疑问包括:
-
如果是 Get 请求,那么两次回复得到的 value 可能并不一致,这种情况真的会发生吗?由于 raft 顺序执行 log entry,那么不同 leader 在执行同一个 Get 请求时,之前的写请求也必定是按照统一的顺序执行的,则 state machine 的状态在执行这个 Get 请求时必定一致。为什么 raft 论文说可能不一致呢? - 在执行完 raft cmd 后,需要找到其对应的 proposal。如果在此过程中发现了 stale proposal,则告知 client 该 proposal 过期了;如果发现了与当前执行的 log entry 一致的 proposal (index 与 term 均一致),才回复 client。对于 stale proposal,我的理解是:如果 proposal 的 index 小于 log entry 的 index,或 proposal 的 term 小于 log entry 的 term,那么认为该 proposal 为 stale。这样的判断是正确的吗?另一方面,对于 index 和 term 的其他情况,又该如何应对呢?
Log Compaction & Snapshotting
Log Compaction
每次 tick,leader 会比较 applied index 和 storage first index 的大小,检查是否超过预设的某个阈值。如果超过,则会向 raft 层发送一个 CompactLogRequest ,待其 commit 后被 raft worker 捕获。raft worker 会通知 raftLogGCTaskHandler,异步执行 log compaction。与此同时,立即更新 truncated state 等状态,并持久化。
关于这部分,尚存的疑问包括:
- 为什么 log compaction 需要等 raft 层 commit 之后才做,而不是由单机独立做?
- 如果机器在 truncated state 持久化过程中 crash 了,但在此之前,异步执行的 gc task 却执行成功并持久化了。那么在 recovery 时,得到的 truncated state 实际是 stale 的。tinykv 是否会出现这个问题?
Log Replication 和 Snapshotting
一个典型的场景是:当一个新 node 刚添加进集群,经过一轮心跳包交互后,leader 会发现该 node 的状态落后于 leader 自身的状态,因此会尝试发送该 node 缺失的 log。由于日志压缩,这些 log 可能已经被全部或部分丢弃了,因此 leader 会放弃此次 log 的发送,转而发送 snapshot。(实际上,会根据是否能获得 prevLogTerm 来判断是否需要发送 snapshot)
为什么 snapshot 可以代替这些缺失的 log 呢?这需要我们理解 raft + log replicated state machine 所构成的 fault-tolerant server 的典型结构。这样的一个 server 通常会包含 raft 模块及 state machine 模块。当一个 client request 到达 server 时,其先被转变成一条 raft cmd,再被 marshal,塞进一条 log entry 中,由 raft 模块进行 log replication。待 raft 模块 commit 这条 log entry 后,从其中 unmarshal 出对应的 raft cmd,再从其中解析出 request,最终将其输入到 state machine 模块。执行 request 后,state machine 的状态便会更新(如果是 write request)。而 state machine 的状态才是 fault-tolerant server 所真正关注的状态。在 fault-tolerant key-value server 中,state machine 即底层的 key-value store,其状态由其所有 key-value pairs 共同组成。
当一个集群在通常情况下运行时,不同的 node 通过按照相同的顺序执行一系列相同的 log entry,从而达到 state machine 状态的一致性。然而在上述“典型的场景”中,由于 log entry 的缺失,新加入的 node 无法通过执行 log entry 达到同步。但注意我们的唯一目标是 state machine 状态的一致性,因此 leader 通过将自身 state machine 的状态写入到一个 snapshot 中,再将其发送给新加入的 node;新加入的 node 再 install 这个 snapshot,直接更新 state machine 的状态,而跳过执行 log entry 的步骤。
总结来说,log replication 和 snapshotting 是同步不同 server 上 state machine 状态的两种不同手段。一条 log entry 通常仅涉及数量有限的 key-value pair 的 access,而一个 snapshot 由于是当前 state machine 状态的快照,因此会包含很多 key-value pairs,在发送时会占用很多网络带宽、在生成和 install 时会占用很多 I/O 资源。因此通常情况下,使用 log replication 进行 state machine 状态的同步,而只在必要情况下使用 snapshotting。
发送和接收 Snapshot 的流程
- 在将要发送 log 给某个 follower 时,leader 通过对比 prevLogIndex - 1 与 lastIncludedIndex,发现无法获得 prevLogIndex 所对应的 prevLogTerm。因此转而尝试发送 snapshot。
- 通过调用 storage 层的 Snapshot 接口(peer storage 的 Snapshot 接口),raft 通知 storage 层开始生成一个 snapshot。在生成期间,对于 Snapshot 接口的调用将会返回特定的错误,告知 raft 层。
- 一个 snapshot 实质上是一个文件,每个 snapshot 文件对应一个独特的 snap key。snap key 由 region id、snapshot index 和 snapshot term 构成,因此可以唯一地指定一个文件路径。在生成 snapshot 的过程中,state machine 的状态被逐渐写入到这个 snapshot 文件。(实际上,一个 snapshot 会对应多个文件,此处为了说明做了相应地简化)
- 成功生成一个 snapshot 后,leader 在 raft 层捕获 Snapshot 接口返回的 snapshot,将其塞进 raft msg 中,准备发给对应的 follower。
- peer msg handler 在
HandleRaftReady函数中,捕获到待发送的 raft msg,将其交付给 transport。在准备发送的较末端阶段,存在一个WriteData函数,该函数的行为如下:- 如果 raft msg 中不含有 snapshot,则其被递交给
RaftClient.Send进行发送; - 如果 raft msg 中含有 snapshot,则会被
SendSnapshotSock函数截获,该函数会 schedule 一个sendSnapTask,异步发送 snapshot。
- 如果 raft msg 中不含有 snapshot,则其被递交给
- 发送 snapshot 的任务由
snapRunner.sendSnap函数完成。该函数首先创建一个 tinky client,再以其为代理,与 follower 所在的 tinykv server 建立一条流式长连接,并发起一个 Snapshot request。snapshot 则被拆解为 snapshot metadata 和 snapshot data 两个部分。前者包含 config state、snapshot index 和 snapshot term,在接收后由 raft 层处理;后者包含 region、key-value pairs 等数据,在接收后由 storage 层处理。不论哪个部分,都是通过 snapshot chunk 的形式进行发送,接收端则将 chunks 重新组装成 snapshot metadata 和 snapshot data。 - follower 所在的 tinykv server 在接收到 Snapshot request 后,会调用 storage 层的 Snapshot 接口(raft storage 的 Snapshot 接口),由其 schedule 一个
recvSnapTask,进而调用snapRunner.recvSnap执行 snapshot chunks 的接收任务。直至 snapshot chunks 完全接收完毕后,接收端断开连接,发送 response 给发送端。leader 所在的 tinykv client 收到该 response 后,断开连接。至此,完成 snapshot 的传输。 - 接收端的 snap runner 在 snapshot 传输成功之后,会将 snapshot 塞进一条 raft msg,发送给 raft worker,最终被 raft 层的
HandleInstallSnapshot捕获。 - 一个值得说明的点:在 follower 完成 install snapshot 之前,每一轮心跳包都可能会触发 snapshot 的生成,显然会占用很多网络和 I/O 资源,并且可能会生成重复的 snapshot。tinykv 对此问题的应对方案是:发送端允许生成重复的 snapshot,但会在必要时删除较老的 snapshot,腾出磁盘空间;接收端则通过 snap key 判断对应的 snapshot 文件是否已经存在,如果存在则说明已经有相同的 snapshot 处于传输状态,因此立刻断开连接,并回复发送端。发送端收到回复后,同样立即中断连接。虽然占用网络带宽的问题被解决,但是重复生成的 snapshot 占用过多 I/O 资源的问题却仍旧存在。我个人的想法是,在内存中维护一个哈希集合,key 为 snap key。在生成一个 snapshot 文件时,将对应的 snap key 插入到该集合中;在发送成功或中途中断后,从集合中删除该 key。当且仅当集合中不存在对应的 snap key 时,才开始生成 snapshot。Talent Plan 社区对于此问题的解决方案则如下:
关于此部分,尚存的疑问包括:
- 我在测试时,并没有遇到上述链接所述的问题,因此没有做相应的优化。
Follower Apply Snapshot 的流程
根据以上发送和接收流程,在 raft 层捕获 snapshot msg 时,对应的 snapshot data 必定被 storage 层成功持久化。回顾 Log Replication 和 Snapshotting 这一节的描述,由于 snapshot 的存在,我们可以跳过执行 log entry,直接更新 state machine 的状态。因此,HandleInstallSnapshot 函数只需要根据 snapshot metadata 对 raft 层的状态进行相应的更新。
具体而言,如果在 follower 的 log 中找到了 snapshot 所在的 log entry(index 为 snapshot index,term 为 snapshot term),则在该 log entry 之前的所有 log entry,都可以被直接丢弃。因为执行这些 log entry 的最终状态已经被包含在 snapshot 中。如果没有找到这样的一个 log entry,则可能是因为如下原因之一:
- follower 的 log 比 leader 短,还没有 append 这个 log entry。此时,commit index < snapshot index.
- follower 的 log 比 leader 长,但是错误地 append 了很多 log entry。此时,commit index < snapshot index.
- follower 的 log 比 leader 长,虽然正确地 append 了很多 log entry,但可能由于 log compaction,这个 entry 已经被丢弃了。此时,commit index > snapshot index.
无论哪种情况,都可以安全地丢弃所有 log entry,无论它们是否已经 applied、committed、stabled。但要注意防止倒退 applied index 和 commit index,这是因为它们的倒退,可能会导致同一个 log entry 被执行多次,显然是不对的。此外,对于情况三,可以通过比较 commit index 和 snapshot index,拒绝老旧的 snapshot。但这并不是必须的。
在 raft 层更新以后,raft worker 通过 HandleRaftReady 检测到有待 install 的 pending snapshot,于是调用 storage 层的 ApplySnapshot 。该函数首先 schedule 一个 RegionTaskApply ,通知 region task handler 执行 apply snapshot 的任务。待该任务执行成功之后,调用 clearExtraData 将包含在 old region 中、但不在 new region 中的 key 删掉(key-value store 的 kv pairs),调用 clearMeta 删除老旧的 state 和 log(raft log entries),最后根据 snapshot metadata 更新各项 state,并持久化。至此,成功 install 一个 snapshot。
一个值得说明的是,对于 applied index 和 stabled index 的更新,可以由 raft 层在 HandleInstallSnapshot 中执行,也可以延迟到 raw node 层的 Advance 中执行。不过我的理解是,由于不需要执行 log entry,因此不需要上层的参与,raft 层可以自行更新。这样的行为是安全的,如果在 raft 层更新以后,apply snapshot 过程中 crash 了,那么由于 raft 层仅仅更新了内存中的数据,在 recovery 之后,consistency 依旧满足。
另一个值得说明的是,在 install snapshot 后,可以选择给 leader 发送一个 AppendEntries response,通过设置其中的 next index,告知 leader follower 在 install snapshot 之后的进度。但这并不是必须的。
关于这部分,尚存的疑问包括:
-
clearMeta会在 write batch 中记录 region state, apply state 及 raft state 的 Delete 请求。在根据 snapshot metadata 更新各项 state 时,又会在 write batch 中记录这些 state 的 Set 请求。根据我对 write batch 代码的理解,其会顺序执行所记录的请求。所以理论上来说,应该先记录 Delete 请求,再记录 Set 请求。反之,则会出现错误。但是即使我先记录 Set ,再记录 Delete,仍然能通过所有测试。