Issue
https://github.com/pingcap/tiflow/issues/11744
Root Cause
Redo log 将数据和元数据保存到外部存储。但是,redo 的数据处理模块中存在一些与错误处理相关的 Bug。当 TiCDC 集群和 redo log 外部存储之间出现网络分区故障时,可能出现:
- 如果写meta失败,changefeed将重新启动并尝试恢复同步过程,这是预期行为。
- 如果写meta成功,写数据失败,即使redo的数据处理模块已经停止,changefeed也会继续正常进行。这是非预期行为,实际上禁用了 redo log 功能,并在灾难场景中导致可能的数据不一致。
注意:网络故障的持续时间决定了这些问题是否会发生。由于 redo log 模块的指数回避机制中随机添加了抖动,所以只有当失败持续时间近似等于重试模块的超时时间(5分钟)时,才会出现写文件的概率失败。
Diagnostic Steps
- 部署 TiDB(上游) + TiCDC + TiDB/mysql(下游)
- 创建 Changefeed ,打开设置 Changefeed 配置
[consistent]
level = “eventual”
- 在 TiCDC 集群与 Redo 外部存储间注入约 5 分钟的网络分区故障。
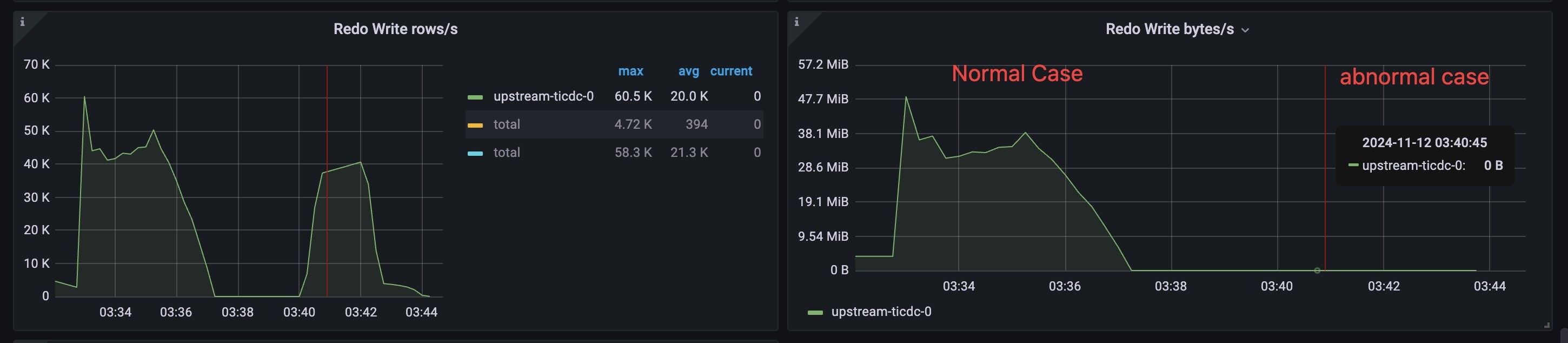
- 上游 TiDB 有写负载的过程中,观察 TiCDC-Redo 面板的监控状态:
- 正常情况:Redo Writer rows/s and Redo Writer bytes/s 均显示存在写负载。
- 异常情况:Redo Writer bytes/s 显示为空,而另一个监控显示存在写负载。
Affect version
- v6.5.10, v6.5.11
- v7.5.2, v7.5.3, v7.5.4
- v8.1.0, v8.1.1
Resolution
升级 TiCDC 到 v6.1.12 / v7.5.5 / v8.1.2 及之后版本
Workaround
从监控中发现这个问题后,重启 changefeed