朱振文啊
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
生产环境
【概述】 场景 + 问题概述
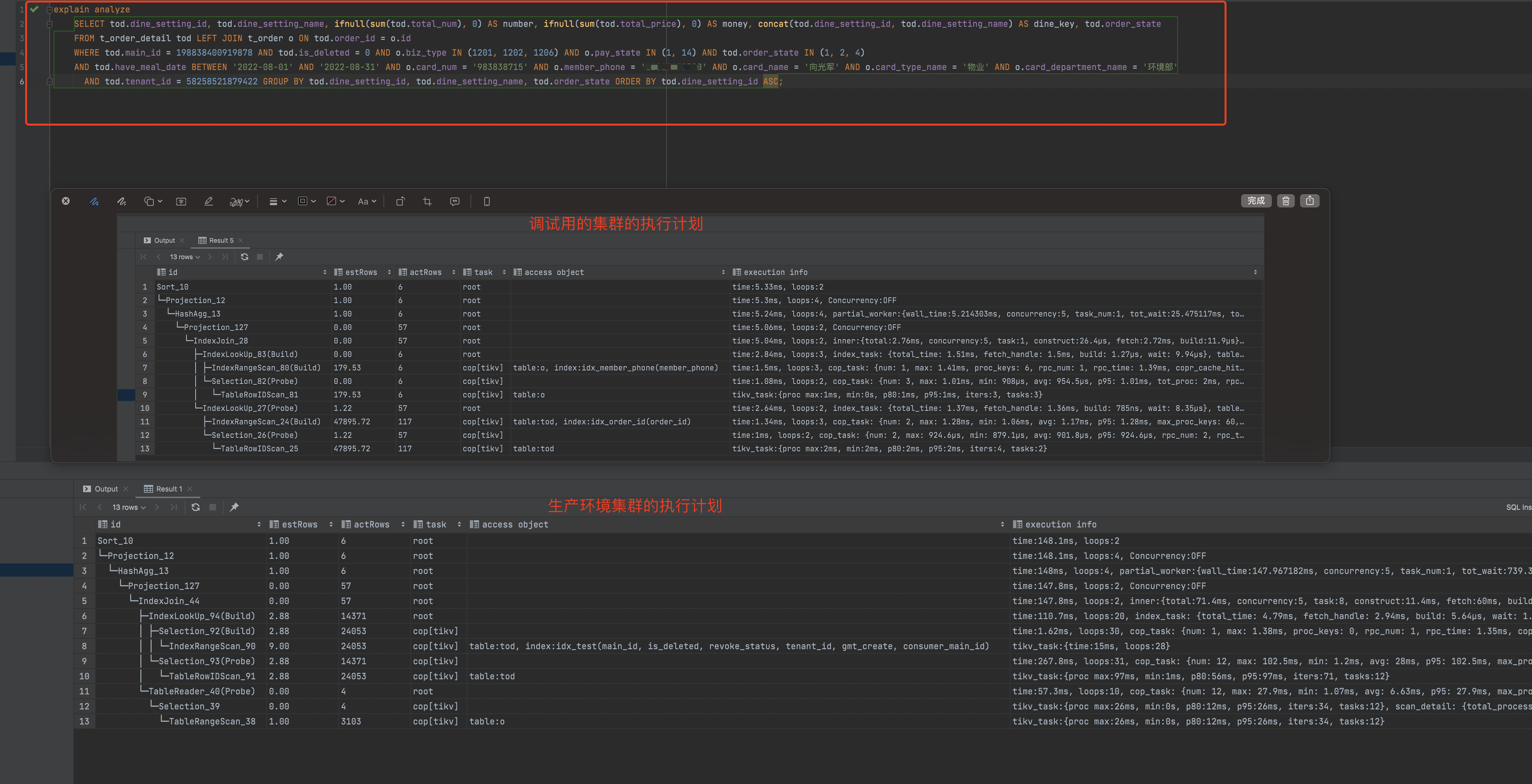
sql查询,生成的执行计划不准确,导致sql执行时间过长
【背景】 做过哪些操作
把生产环境的数据同步到调试集群中,查看sql的执行计划,发现sql能正确生成准确的执行计划,查询速度达到预期效果
【现象】 业务和数据库现象
业务上导致查询过慢
【问题】 当前遇到的问题
1:两个数据内容跟版本相同的集群,生成的执行计划不同
【业务影响】
1:查询慢
【TiDB 版本】
v5.4
【应用软件及版本】
【附件】 相关日志及配置信息
- TiUP Cluster Display 信息
- TiUP CLuster Edit config 信息
监控(https://metricstool.pingcap.com/)
- TiDB-Overview Grafana监控
- TiDB Grafana 监控
- TiKV Grafana 监控
- PD Grafana 监控
- 对应模块日志(包含问题前后 1 小时日志)
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。tableSql (10.7 KB)
select from tablea use index(idx_index) where a=999 强制索引
感觉统计信息还是不太准确,顺别也贴下两个环境索引部分把
这明显两个表索引不一样 走错索引了 哎 我没话说了 6个联合索引
朱振文啊
10
我刚上传了两个表的表结构了,通过文件对比,两个集群里面的表结构是一致的
朱振文啊
11
我刚上传了两个表的表结构了,两张表的数据都是一千万左右,通过文件对比,两个集群里面的表结构是一致的
wakaka
(Wakaka)
13
用force_index去绑定这条语句的执行计划,影响最小。
朱振文啊
14
找到原因了,生产环境的集群,运维把tidb_analyze_version的默认值2 改成了1,解决办法就是把version改回2,清除掉统计信息,重新analyze_table,最后sql查询就会走到正确的索引了。
Version 2 的统计信息避免了 Version 1 中因为哈希冲突导致的在较大的数据量中可能产生的较大误差,并保持了大多数场景中的估算精度。
https://docs.pingcap.com/zh/tidb/dev/statistics#统计信息简介