为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】4.0.12
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】4.0.12
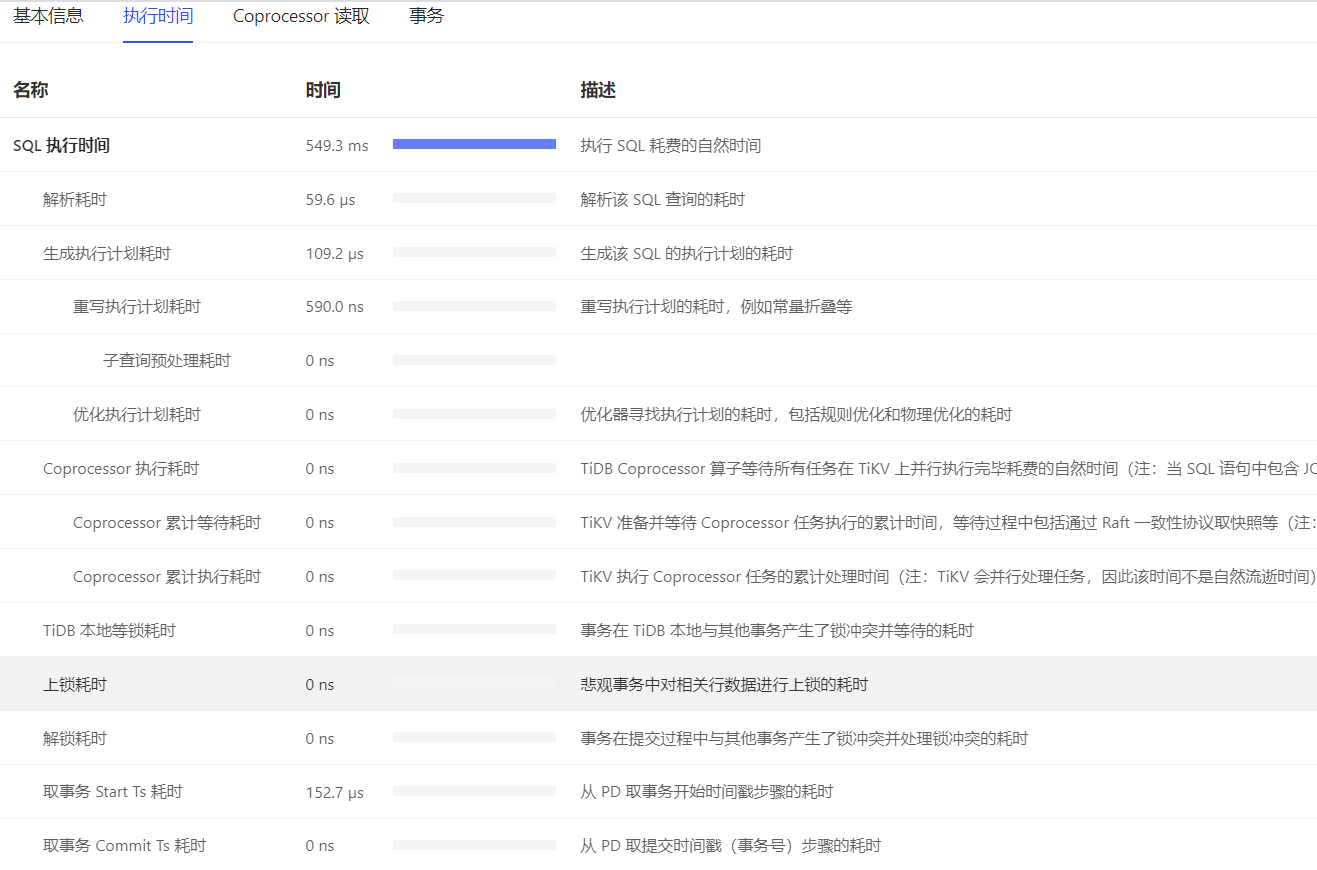
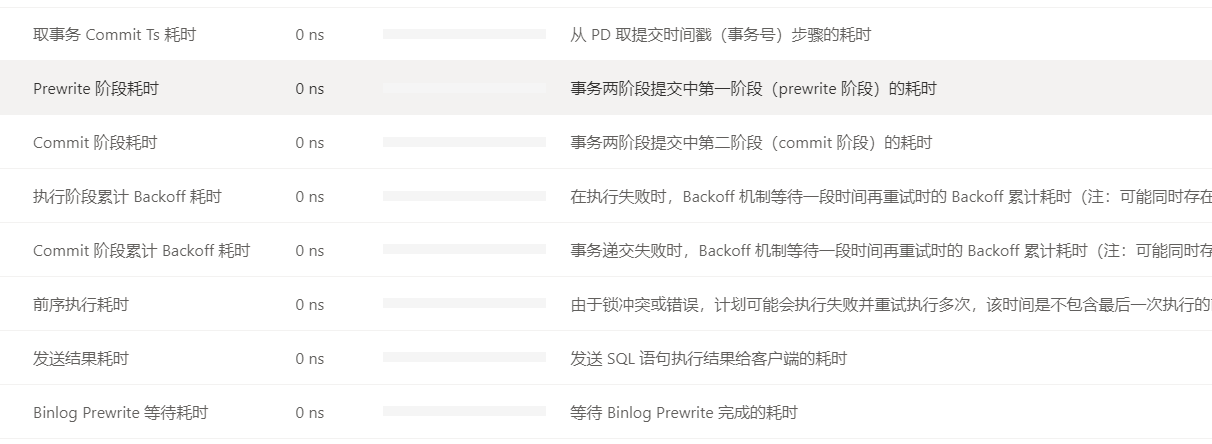
麻烦反馈下这个 SQL 真实的执行计划(explain analyze + SQL 文本),另外麻烦把后台慢日志中这个 SQL 相关的内容也提供下
慢SQL:
update tf_f_user_item_shift set partition_id=4119 , attr_value=‘1’ , end_date=‘2021-05-31 23:59:59’ , eparchy_code=‘0857’ , province_code=‘85’ , update_depart_id=‘CREDIT’ , update_staff_id=‘CREDIT00’ , update_time=‘2021-05-28 05:38:15’ where user_id=8518031482094119 and crm_attr_code=‘STOP_FLAG’ and attr_code=‘STOP_FLAG’ and start_date=‘2021-05-28 05:36:58’;
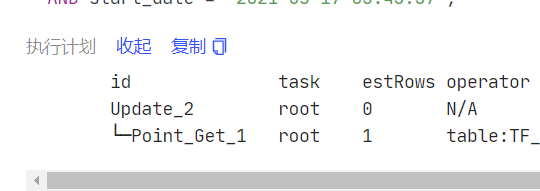
id task estRows operator info actRows execution info memory disk
Delete_6 root 0 N/A 0 time:450.4ms, loops:1, lock_keys: {time:64.2ms, region:2, keys:2, lock_rpc:64.190729ms, rpc_count:2, retry_count:1} 5.41 KB N/A
└─Selection_11 root 1 eq(d_users.tf_f_user_service_item.user_id, 1716092774116388) 1 time:450.4ms, loops:2 1.54 KB N/A
└─Point_Get_10 root 1 table:tf_f_user_service_item, index:PRIMARY(ATTR_CODE, CRM_ATTR_CODE, SERVICE_ITEM_ID, START_DATE), lock 1 time:450.3ms, loops:3, Get:{num_rpc:1, total_time:386ms}1.请问下集群中是普遍存在 SQL point get 慢的问题,还是偶尔出现这个现象;
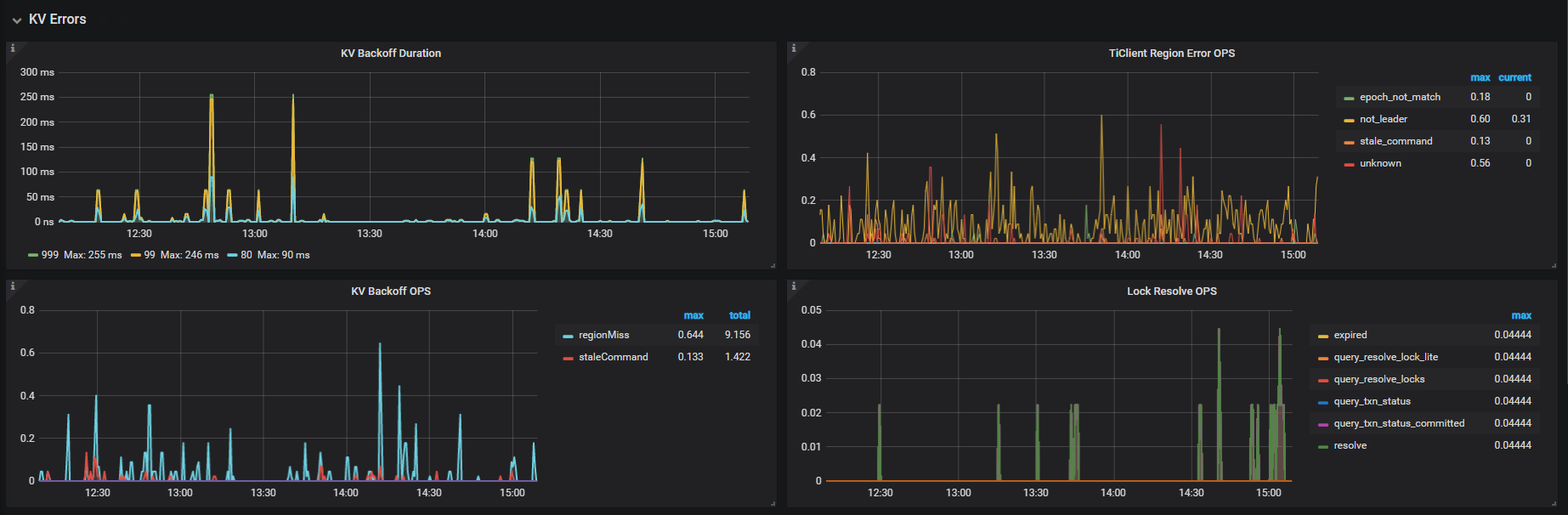
2.如果是普遍存在的话,麻烦在问题比较集中的时间段导出下集群的 overview/tidb/pd/tikv-details 的监控面板,导出方法参考:https://metricstool.pingcap.com/#backup-with-dev-tools
目前是在load数据 磁盘IO可能有些影响,这些SQL是kafka做数据同步产生的DML语句,有个问题是执行计划里lock_keys占了64ms,对于lock_keys占时比较长怎么排查是哪一步影响的?
你可以先参考这篇文档排查下锁冲突问题:
https://docs.pingcap.com/zh/tidb/stable/troubleshoot-lock-conflicts#tidb-锁冲突问题处理
请问 load 数据阶段已经结束了吗?现在这类 DML 语句的 Query Time 还是和之前一样耗时高吗?另外系统中其他查询的 SQL 也有同样的现象吗?
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。