【 TiDB 使用环境】
生产环境
【 TiDB 版本】
6.1.0
【遇到的问题】
flinksql读取tidb表,并聚合计数,发现源表读取的数据少了很多(源表有1000w+数据),导致聚合的结果不对
【附件】
【 TiDB 使用环境】
生产环境
【 TiDB 版本】
6.1.0
【遇到的问题】
flinksql读取tidb表,并聚合计数,发现源表读取的数据少了很多(源表有1000w+数据),导致聚合的结果不对
【附件】
scan.startup.mode 给的什么值?
如果你期望是全表扫,flink state 也装不下这么多,流式处理方式也不是怎么玩的…
默认的inital, state存的rocksdb, 即使只用来同步表数据,如tidb->tidb, 也是一样的问题, 只同步了一部分数据
不清楚你的具体场景,,很难帮你分析了
是所有表都这个表现,还是其中一个呢?
试了几个表都这样, 需求: 表数据按照公司id分组计数,
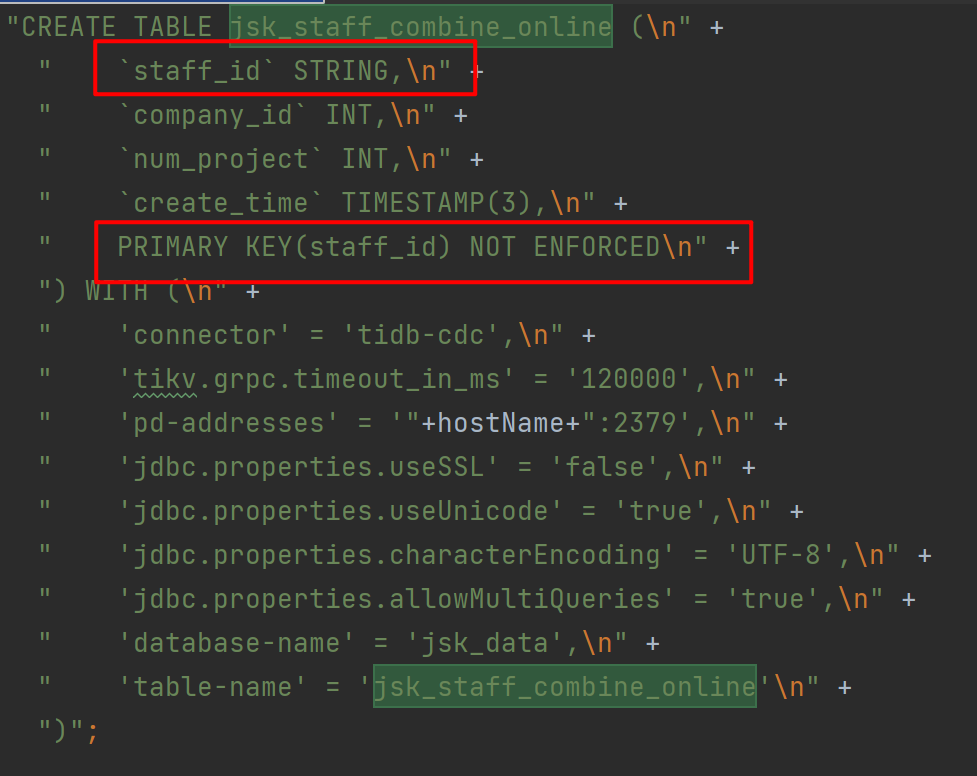
注册表语句:
“CREATE TABLE jsk_staff_combine_online (\
” +
" staff_id STRING,\
" +
" company_id INT,\
" +
" num_project INT,\
" +
" PRIMARY KEY(staff_id) NOT ENFORCED\
" +
“) WITH (\
” +
" ‘connector’ = ‘tidb-cdc’,\
" +
" ‘tikv.grpc.timeout_in_ms’ = ‘120000’,\
" +
" ‘pd-addresses’ = ‘"+hostName+":2379’,\
" +
" ‘jdbc.properties.useSSL’ = ‘false’,\
" +
" ‘jdbc.properties.useUnicode’ = ‘true’,\
" +
" ‘jdbc.properties.characterEncoding’ = ‘UTF-8’,\
" +
" ‘jdbc.properties.allowMultiQueries’ = ‘true’,\
" +
" ‘database-name’ = ‘jsk_data’,\
" +
" ‘table-name’ = ‘jsk_staff_combine_online’\
" +
“)”
插入语句:
insert into jsk_dws_count_professional(company_id,team_leader) select company_id,count(*) as cnt from jsk_staff_combine_online where num_project > 0 group by company_id
然后我索性试了2个表之前的同步,上面的jsk_staff_combine_online 这个表同步到 test表中, 结果也是一样,只同步了100w+数据, 也只有一个source的task有数据
插入语句:
insert into test_jsk_staff_combine_online(staff_id,company_id,num_project) select staff_id,company_id,num_project from jsk_staff_combine_online
1 对 1 的直接同步呢? 也数据不对么?
丢失的数据有哪些特征?日志有无报错或者警告
也是不对,一点错误信息都看不到
没有任何错误,因为主键是uuid的,所以看不怎么出丢失数据的特征,
请问现在写入数据结果不一致?还是查询结果一致?