ahaii
2021 年5 月 30 日 04:27
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】4.0.0
【问题描述】
使用 pump 存储 binlog,drainer同步到下游mysql。
1、使用 dumpling 全量备份后,还原到mysql 5.7。
2、开启一个drainer 并指定 -initial-commit-ts (全量导出数据目录里的metadata 文件中Pos的值)进行同步。drainer配置里 worker-count = 1 。
3、drainer报错退出,日志提示 error="Error 1062: Duplicate entry '340082756181958656' for key 'PRIMARY'"
查了下游mysql中确实已经存在这条数据,与主库数据一致。检查从tidb集群中导出的数据,也只有一条记录。
想问下为什么会出现这种情况? 是不是drainer在同步的时候没有根据 -initial-commit-ts 指定的值来读取pump的binlog?
若提问为性能优化、故障排查 类问题,请下载脚本 运行。终端输出的打印结果,请务必全选 并复制粘贴上传。
1 个赞
ahaii
2021 年5 月 31 日 03:33
3
您好,error="Error 1062: Duplicate entry '340082756181958656' for key 'PRIMARY'"。
麻烦帮忙看下。多谢。
drainer.log (43.4 KB)
ahaii
2021 年5 月 31 日 04:59
5
您好,已经按照这个流程试过多次。worker-count = 16 并发导致,后来将该值改为 1 后,重新删除下游数据导入、同步。但还是提示重复。
drainer的日志麻烦您帮忙看下能找到原因么?
ahaii
2021 年5 月 31 日 11:49
7
您好,
1、curl http://tidb:10080/mvcc/key/db_pr/account_maker_trade/340082756181958656 结果如下:
{
"key": "74800000000000240C5F7284B8377704762000",
"region_id": 115941,
"value": {
"info": {
"writes": [
{
"start_ts": 425219498770956303,
"commit_ts": 425219498797170827
}
],
"values": [
{
"start_ts": 425219498770956303,
"value": "gAAcAAAAAgMEBQYHCAkKCwwNDg8QERITFBUWFxgZGhscHQEACQAKAA4ADwATABQAFQAWACoAPgBSAGYAegB7AH4AkgCmALoAzgDPANAA2ADgAOgA6QDqAOsAAABQQuRyN7gEAdCHDgAjv55ZAAEAAyYQgAAAAAAAAAAAGTVeuEAAAAAAJhCAAAAAAAAAAAAAAAAAAAAAAAAmEIAAAAAAAAAAAFwzd980AAAAACYQgAAAAAAAAAAAAAAAAAAAAAAAJhCAAAAAAAAAAAAAAAAAAAAAAAAtVU5JJhCAAAAAAAAAAAAAAAAAAAAAAAAmEIAAAAAAAAAAAAMi7y0gAAAAACYQgAAAAAAAAAAAAAAAAAAAAAAAJhCAAAAAAAAAAABcM3ffNAAAAAAEAQAAANsrtqkZAAAA2yu2qRkAAADnK7apGQQEAQ=="
}
]
}
}
}
2、已确认,下游mysql只有drainer一个应用连接。
感谢您。
小王同学
2021 年6 月 1 日 02:40
8
根据你这边提供数据的 MVCC 版本,数据插入时间是 5.27,而报错主键冲突的时间是 05.30,怀疑是之前数据就写入进去了,非 drainer 重复消费,你这边可以查一下权限是否是其他人员写入的。
ahaii
2021 年6 月 1 日 04:32
9
非常感谢您的回复。
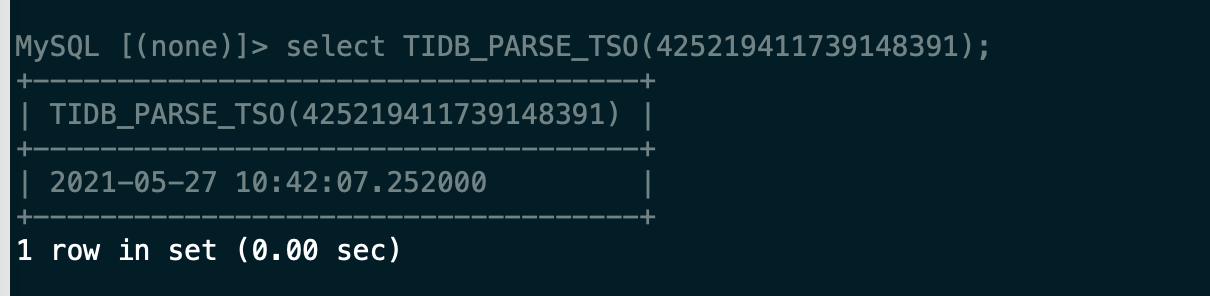
回复中第一个截图显示时间为 2021-05-27 10:47:39.352000 ,请问这个时间是冲突数据第一次插入下游mysql的时间吗?
而我全量备份目录里生成的 metadata 内容为:
Started dump at: 2021-05-27 10:42:07
SHOW MASTER STATUS:
Log: tidb-binlog
Pos: 425219411739148391
Finished dump at: 2021-05-27 12:02:34
备份结束时间为 2021-05-27 12:02:34 。
我的理解下游mysql插入的时间应该在备份结束时间之后吧,有点困惑。
感谢您。
小王同学
2021 年6 月 1 日 06:06
10
这个时间指的是你当前数据插入到下游的时间,425219411739148391 这个你也可以解析下,对应的是备份开始的时间。是以这个 tso 为 -initial-commit-ts 的初始值。
ahaii
2021 年6 月 1 日 07:35
11
您好,感谢您的回复。
根据 metadata 文件中记录可知:2021-05-27 10:42:07.2520002021-05-27 12:02:34
根据您的回复 “ 2021-05-27 10:47:39.352000 这个时间指的是你当前数据插入到下游的时间 ”。这一点有点困惑,我是在全量备份完成之后再导入到下游mysql的,正常来说,下游数据的插入时间要晚于 Finished dump at: 2021-05-27 12:02:34 这个时间对么?
感谢您。
小王同学
2021 年6 月 1 日 07:50
12
不是的,导出的是开始时间 Started dump at: 2021-05-27 10:42:07 这个时间的快照数据。
ahaii
2021 年6 月 1 日 08:30
13
感谢您的回复,这个彻底明白了。
但是现在可以确认的是,下游mysql在导入数据之前,将库删除清空了,且只有一个 drainer 来写入数据。
1、上游有两个 pump 来存储 binlog,这个binlog内容需要用什么工具来查看呢?想确认下会不会 pump 记录了重复的binlog。
2、drainer 的部分配置如下:
[syncer]
# 如果设置了该项,会使用该 sql-mode 解析 DDL 语句,此时如果下游是 MySQL 或 TiDB 则
# 下游的 sql-mode 也会被设置为该值
# sql-mode = "STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION"
# 输出到下游数据库一个事务的 SQL 语句数量 (默认 20)
txn-batch = 20
# 同步下游的并发数,该值设置越高同步的吞吐性能越好 (默认 16)
# worker-count = 16
worker-count = 1
# 是否禁用拆分单个 binlog 的 SQL 的功能,如果设置为 true,则按照每个 binlog
# 顺序依次还原成单个事务进行同步(下游服务类型为 MySQL, 该项设置为 False)
#disable-dispatch = false
# safe mode 会使写下游 MySQL/TiDB 可被重复写入
# 会用 replace 替换 insert 语句,用 delete + replace 替换 update 语句
safe-mode = false
其中 safe-mode = false 是否会影响下游的 update 操作?
感谢您。
小王同学
2021 年6 月 1 日 09:19
14
Pump 用于实时记录 TiDB 产生的 Binlog,并将 Binlog 按照事务的提交时间进行排序,再提供给 Drainer 进行消费。
如果要看 pump 中是否记录了重复的 binlog,只能再启动一个 drainer,下游设置为文件格式,起始位点设置为 Pos: 425219411739148391,然后再去解析文件中的 binlog,查一下是否是有重复数据。
或者看上面你这边描述可以复现,是否可以重新操作一次,然后打开 tidb 的 general log 看下呢。
ahaii
2021 年6 月 1 日 10:31
15
感谢您的回复。
1、您说的重新买操作一次,是指重新全量备份、导入,然后开启drainer同步么?set @@tidb_general_log=on 只能开启当前 tidb-server实例的 general log 对吧,其他tidb-server实例需要也开启么?
感谢您。
小王同学
2021 年6 月 1 日 15:08
16
先全量导入,然后开启 general log,再启动 drainer 进行增量同步。按照这样的顺序。
ahaii
2021 年6 月 2 日 01:12
17
感谢您的回复。
抱歉,drainer 的配置文件中只指定了 tipd 集群的地址,没有配置 tidb 的地址。
感谢您。
小王同学
2021 年6 月 2 日 02:15
18
下游是 mysql 对吧,那打开下游 mysql 的 general log 。
ahaii
2021 年6 月 2 日 06:12
19
非常感谢您的回复。
我在导出的sql文件中搜索过冲突数据 340082756181958656 , 结果只有一条。
我的drainer是用二进制文件单独启动的,配置如下:
# Drainer Configuration.
# Drainer 提供服务的地址("192.168.0.13:8249")
addr = "172.17.20.60:8249"
# Drainer 对外提供服务的地址
advertise-addr = "172.17.20.60:8249"
# 向 PD 查询在线 Pump 的时间间隔 (默认 10,单位 秒)
detect-interval = 10
# Drainer 数据存储位置路径 (默认 "data.drainer")
data-dir = "/data/drainer/data.drainer"
# PD 集群节点的地址 (英文逗号分割,中间不加空格)
pd-urls = "http://172.17.20.141:2379,http://172.17.20.246:2379,http://172.17.20.74:2379"
# log 文件路径
log-file = "/data/logs/drainer.log"
# Drainer 从 Pump 获取 binlog 时对数据进行压缩,值可以为 "gzip",如果不配置则不进行压缩
compressor = "gzip"
# [security]
# 如无特殊安全设置需要,该部分一般都注解掉
# 包含与集群连接的受信任 SSL CA 列表的文件路径
# ssl-ca = "/path/to/ca.pem"
# 包含与集群连接的 PEM 形式的 X509 certificate 的路径
# ssl-cert = "/path/to/pump.pem"
# 包含与集群链接的 PEM 形式的 X509 key 的路径
# ssl-key = "/path/to/pump-key.pem"
# Syncer Configuration
[syncer]
# 如果设置了该项,会使用该 sql-mode 解析 DDL 语句,此时如果下游是 MySQL 或 TiDB 则
# 下游的 sql-mode 也会被设置为该值
# sql-mode = "STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION"
# 输出到下游数据库一个事务的 SQL 语句数量 (默认 20)
txn-batch = 20
# 同步下游的并发数,该值设置越高同步的吞吐性能越好 (默认 16)
# worker-count = 16
worker-count = 1
# 是否禁用拆分单个 binlog 的 SQL 的功能,如果设置为 true,则按照每个 binlog
# 顺序依次还原成单个事务进行同步(下游服务类型为 MySQL, 该项设置为 False)
#disable-dispatch = false
# safe mode 会使写下游 MySQL/TiDB 可被重复写入
# 会用 replace 替换 insert 语句,用 delete + replace 替换 update 语句
safe-mode = false
# Drainer 下游服务类型(默认为 mysql)
# 参数有效值为 "mysql","tidb","file","kafka"
db-type = "mysql"
# 事务的 commit ts 若在该列表中,则该事务将被过滤,不会同步至下游
ignore-txn-commit-ts = []
# db 过滤列表 (默认 "INFORMATION_SCHEMA,PERFORMANCE_SCHEMA,mysql,test"),
# 不支持对 ignore schemas 的 table 进行 rename DDL 操作
ignore-schemas = "INFORMATION_SCHEMA,PERFORMANCE_SCHEMA,METRICS_SCHEMA,mysql,*test"
# replicate-do-db 配置的优先级高于 replicate-do-table。如果配置了相同的库名,支持使用正则表达式进行配置。
# 以 '~' 开始声明使用正则表达式
# replicate-do-db = ["~^b.*","s1"]
# [syncer.relay]
# 保存 relay log 的目录,空值表示不开启。
# 只有下游是 TiDB 或 MySQL 时该配置才生效。
#log-dir = "/data/logs/sync"
# 每个文件的大小上限
# max-file-size = 10485760
# [[syncer.replicate-do-table]]
# db-name ="test"
# tbl-name = "log"
# [[syncer.replicate-do-table]]
# db-name ="test"
# tbl-name = "~^a.*"
# 忽略同步某些表
# [[syncer.ignore-table]]
# db-name = "test"
# tbl-name = "log"
# db-type 设置为 mysql 时,下游数据库服务器参数
[syncer.to]
host = ***
user = ***
password = ***
# 使用 `./binlogctl -cmd encrypt -text string` 加密的密码
# encrypted_password 非空时 password 会被忽略
#encrypted_password = ""
port = ***
[syncer.to.checkpoint]
# 当 checkpoint type 是 mysql 或 tidb 时可以开启该选项,以改变保存 checkpoint 的数据库
# schema = "tidb_binlog"
# 目前只支持 mysql 或者 tidb 类型。可以去掉注释来控制 checkpoint 保存的位置。
# db-type 默认的 checkpoint 保存方式是:
# mysql/tidb -> 对应的下游 mysql/tidb
# file/kafka -> file in `data-dir`
# type = "mysql"
# host = "127.0.0.1"
# user = "root"
# password = ""
# 使用 `./binlogctl -cmd encrypt -text string` 加密的密码
# encrypted_password 非空时 password 会被忽略
# encrypted_password = ""
# port = 3360
我现在重新将上游数据全备了,整在导入到下游mysql。
然后 想我这种单独启动drainer服务的,tidb-server 集群的 general log 是不是都需要开启啊?
我使用 set @@tidb_general_log=on 只开启了三个 tidb-server 节点中的一个。
小王同学
2021 年6 月 2 日 06:18
20
这个不需要了。抱歉之前看错了,以为下游也是 TiDB
这块启动 drainer 同步数据到下游 MySQL ,建议再开启动一个 drainer,同时将增量数据同步到 文件中,即 db-type 设置为 file,再次发生主键冲突时,麻烦提供下 file 文件以及 drainer 日志。