为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
4.0
【问题描述】
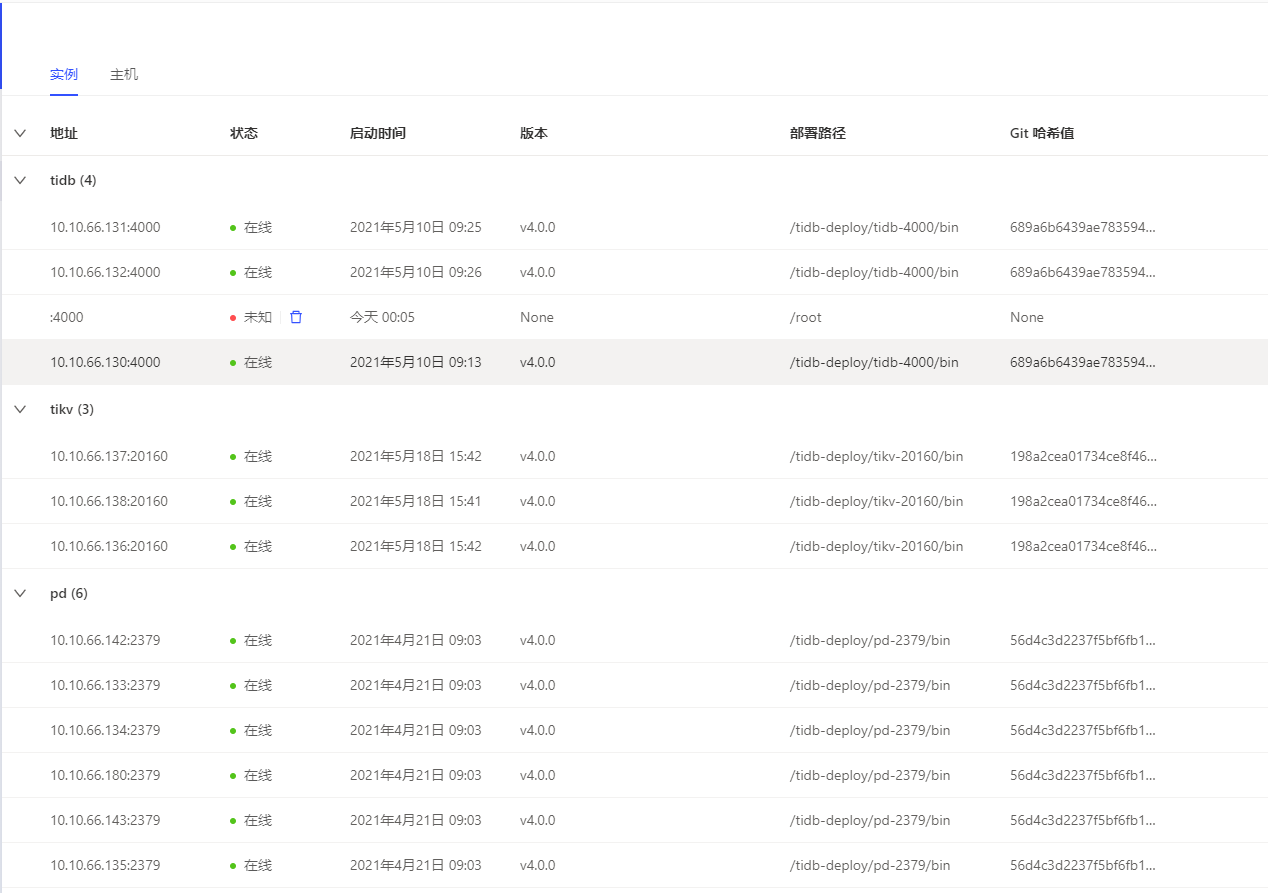
PD扩容了三个节点,完成后显示三个PD新节点成功加入集群,但是TIDB Dashboard中不显示监控CPU、内存等数据,Grafana中可以看到相关监控
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
4.0
【问题描述】
PD扩容了三个节点,完成后显示三个PD新节点成功加入集群,但是TIDB Dashboard中不显示监控CPU、内存等数据,Grafana中可以看到相关监控
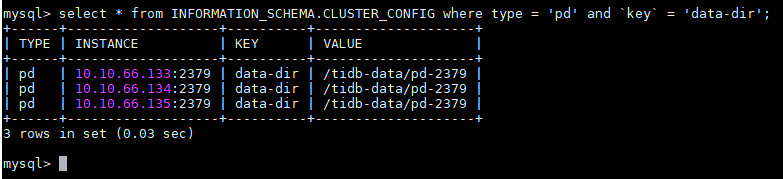
看下这个结果:
select * from INFORMATION_SCHEMA.CLUSTER_CONFIG where type = 'pd' and `key` = 'data-dir';
select * from INFORMATION_SCHEMA.cluster_hardware;
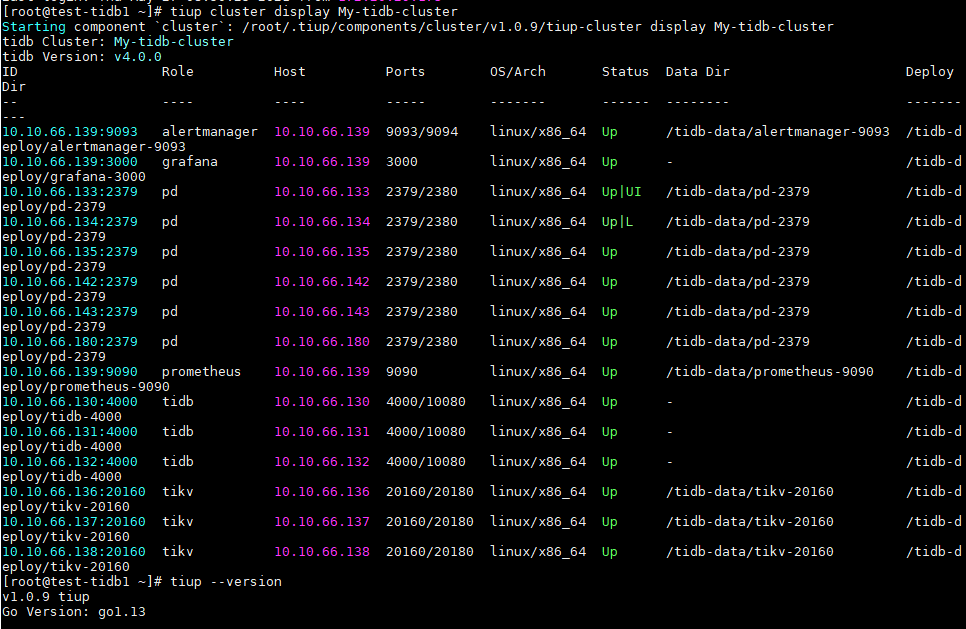
辛苦 tiup cluster display {cluster-name} 看下结果 ~
清下浏览器缓存呢?
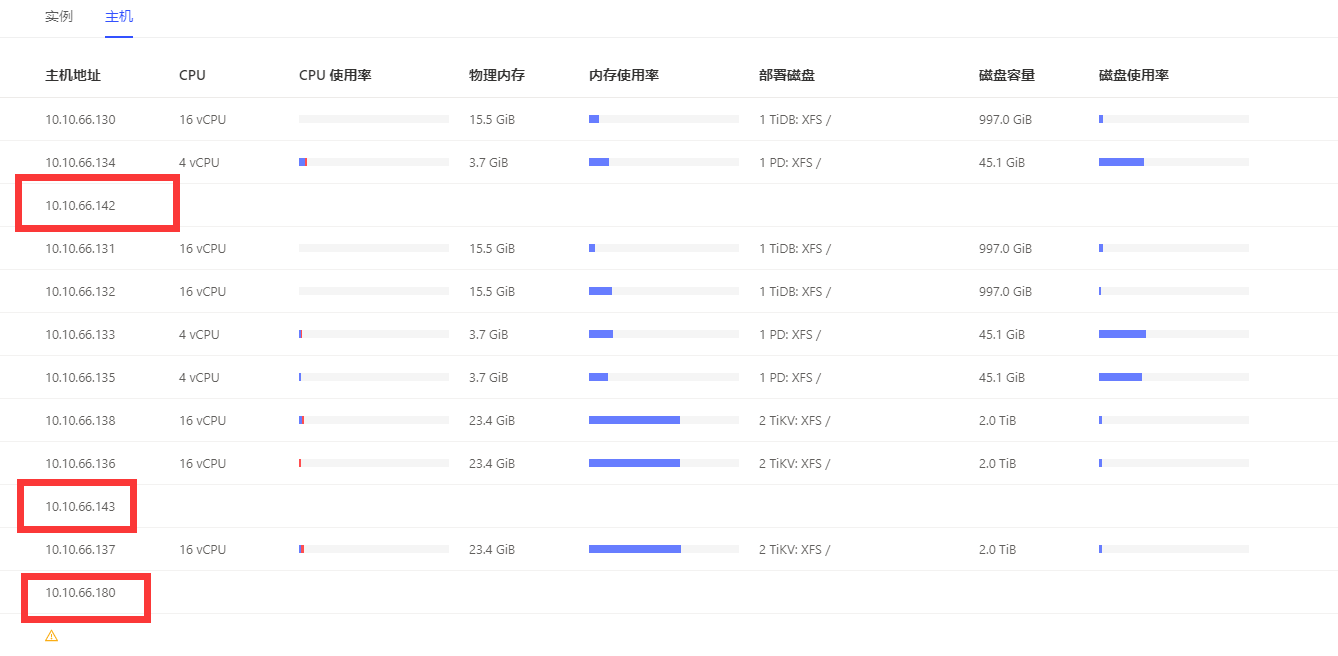
执行之后是各个节点的监控数据,没有扩容的三个新节点142,143,180的数据
这个链接无法打开,有新的链接吗?感谢
这个链接我这边打开没有问题。这里主要是提示 4.0.7 以上的版本已经修复这个问题。请问你的版本是哪个?能否考虑升级到这个版本以上?目前 4.0.12 是最新的 4.0.x 版本 https://docs.pingcap.com/zh/tidb/stable/release-4.0.12
现在我这边测试环境和正式环境都是4.0.0的,如果不考虑升级的话,这个问题有办法解决吗?
workaround 的方式这边先确认下 ~
另外,你的环境中是 6 个 PD Server,请问下,是基于什么考虑,将 PD 从 3 个扩容到 6 个的?
PD 集群自身的高可用性也是依赖于 raft,所以一般情况下,在不低于 3 个节点的情况下,使用奇数部署 ~
因为目前三个PD节点是传统机械硬盘的,新扩容的三个PD节点是SSD的,准备扩了新节点把老节点缩容掉的
workarount 参考步骤如下,强烈建议在测试环境验证通过后,再进行操作:
1、手动将 PD Leader transfer 到新节点上,确保 TiKV 中的 PD Client 会缓存新的 PD 节点。并等待一段时间,观察集群是否有报错等。如果出现 PD no leader 现象,立刻使用 kill -9 强制终止旧 Leader 节点
2、将 3 个旧 PD Server 缩容
3、重启所有 TiDB Server,确保 TiDB 的启动参数中 path 为新的三个 PD 节点地址
好的,我在测试环境上试一下,感谢
如果还有新的问题,请重新开帖哈,感谢配合 ![]()
![]() ~
~