可以尝试使用systemctl stop tiflash-9000 停掉 tiflash 的 service。
我们排查发现机器宕机是内存撑爆导致的了,那两台tiflash在重启的过程中,内存飙升,达到100%后就自动挂掉了,然后过一阵被systemctl自动调起,如此往复,导致tiflash一直起不来,请问tiflash是为什么内存飙升?该如何处理?是不是一个bug?没有内存限制吗?
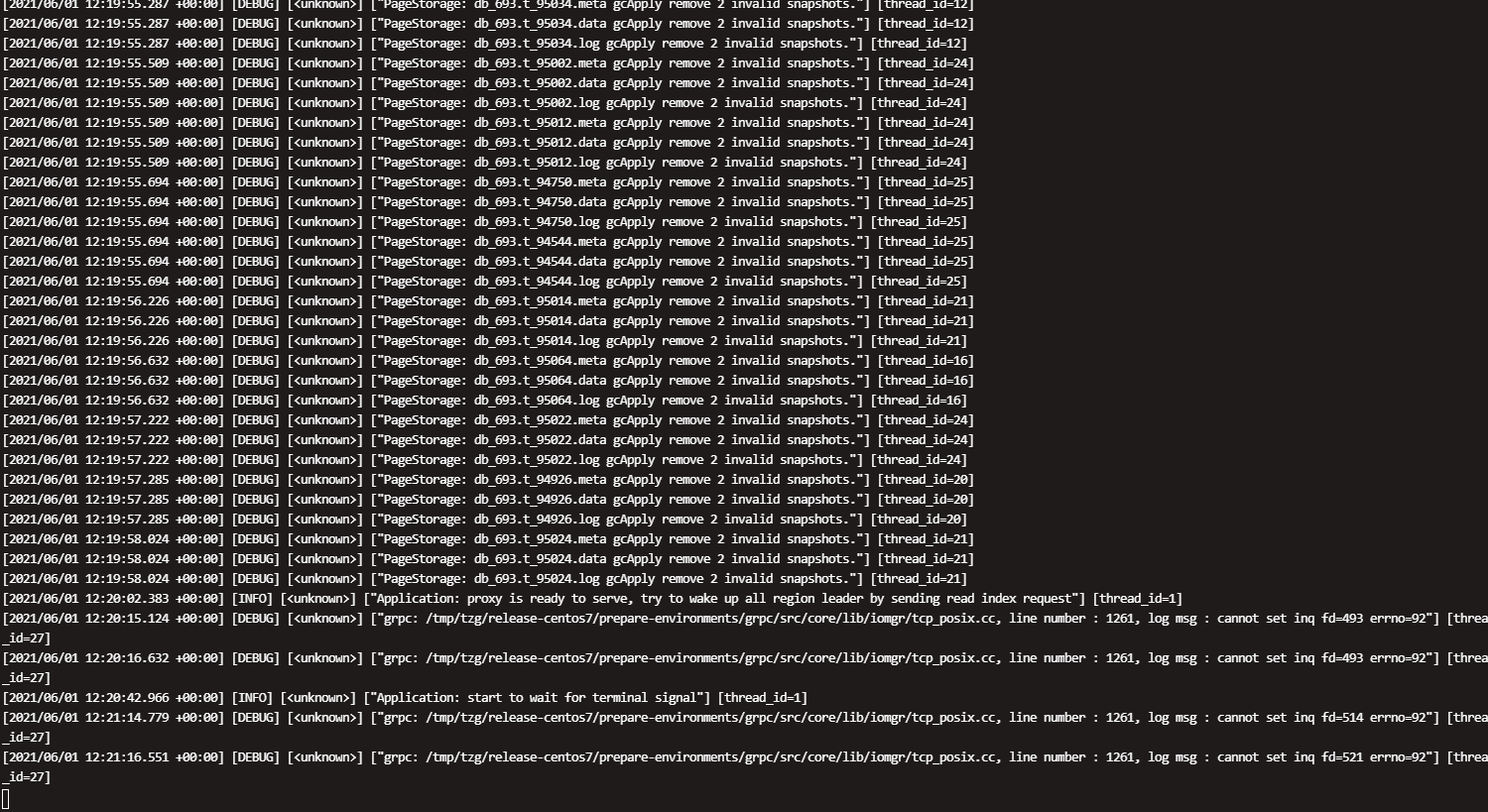
下面是tiflash一次重启的日志,在第389300行 又进行了重启
tiflash.zip (3.1 MB)
下面是日志、监控相关信息:


很像这个文章说的内容:https://asktug.com/t/topic/63052
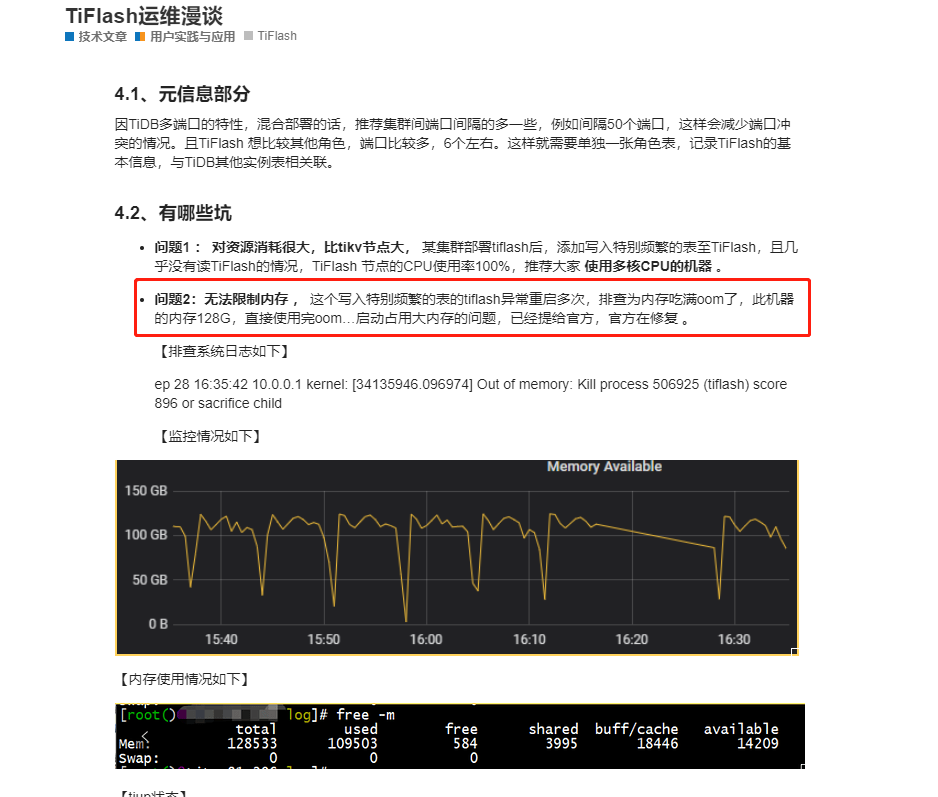
我看是说再4.0.8版本对tiflash吃内存进行了修复,但是我们现在是4.0.11,还是有该问题
@Hacker_IslRgOns
非常抱歉,重启之后内存使用过多导致 OOM 的问题在当前版本目前确实存在。出现的条件:
- tiflash 落后 tikv 过多,或者
- 在 tiflash 重启期间 tikv 有较多修改,比如
如果目前如果遇到类似问题,暂时无法让 tiflash 正常启动,所以只能起新的 tiflash 节点重新同步数据。为了避免类似的情况发生,建议:
- 部署 2 个或者以上 tiflash 节点,tiflash replica 设置为 2。这样即使有一个 tiflash 节点失败,不影响服务。
- 等某一个 tiflash 启动成功后再启动下一台,避免同时启动,免得所有的 tiflash 节点都启动失败。
我们预计在 4.0.14 或者 5.0.2 修复这个问题。5.0.2 版本近期发布,经过充分的测试,并且分析查询性能(特别是复杂 SQL) 有较大提升,建议升级。
2 个赞
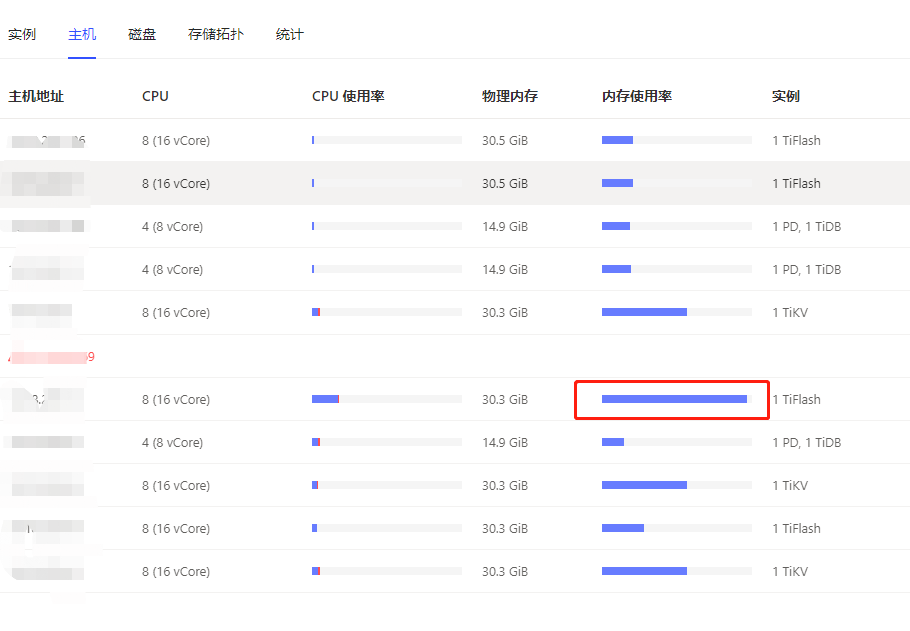
嗨老师您好,我们tiflash上上周 重启了两个节点后恢复了正常,然后在这周末的时候又挂了两台,其中一个直接服务器都连不上了,aws的排查结果是有服务OOM导致的。目前生产上已经出现两次同样的问题了,我们生产上需要知道具体的原因以及如何防范,不能说问题出现了再重启两个节点代替,这肯定在生产上是不能用的,所以想麻烦您或者tiflash的同事能加微信帮忙看下具体原因吗
针对上面的建议,我们也是这样做的,3个tiflash节点,副本为2,
一台一台重启,但还是起不来
@Hacker_IslRgOns 你好,麻烦提供这些数据方便我们排查哈:
-
使用 https://metricstool.pingcap.com/#backup-with-dev-tools 这里的工具导出 TiFlash-Summary 的监控数据。左上角选中出问题的机器;右上角选择出问题的时间周期。
-
出问题的 TiFlash 节点那一段时间内的日志。
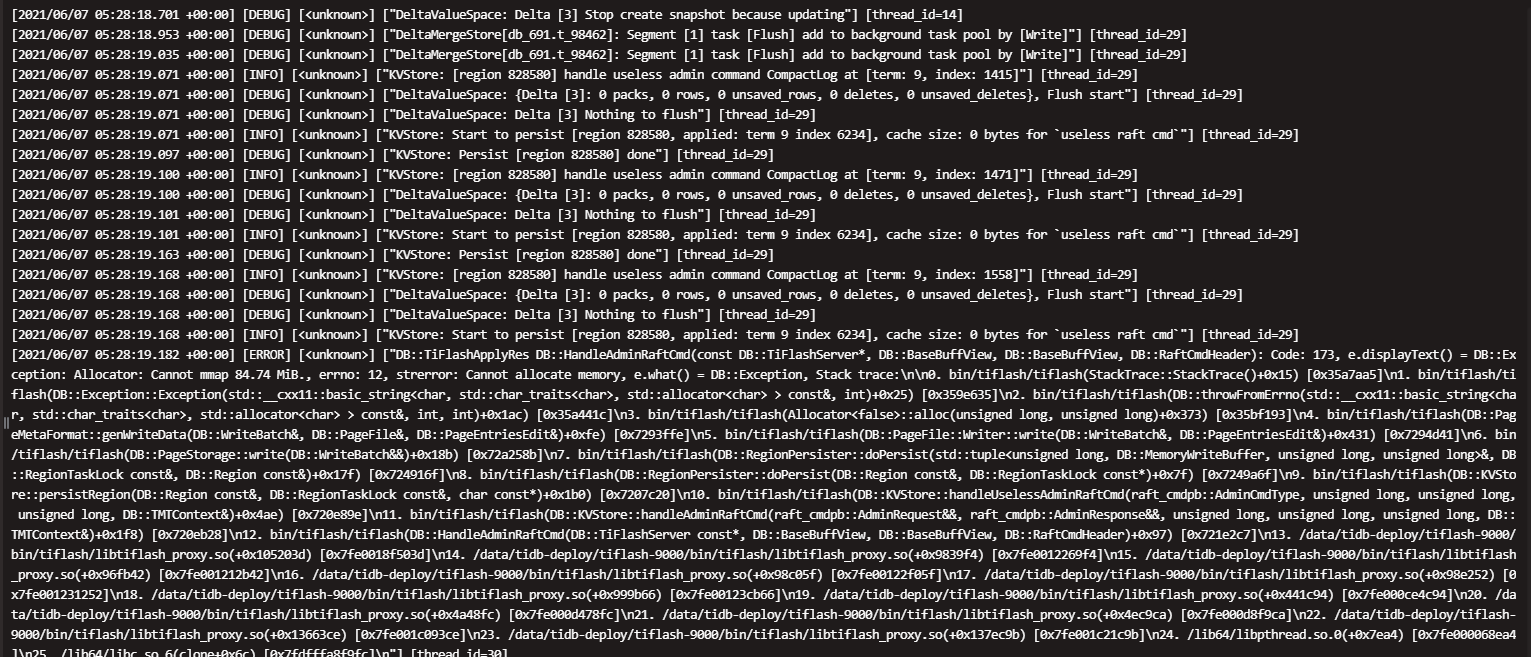
这是中午11点半左右重启了90节点的相关日志,tiflash日志再第381566行是宕机后第二次自动重启,
tiflash日志:
tiflash.zip (3.0 MB)
tiflash-cluster-manager日志:
tiflash_cluster_manager.zip (237.2 KB)
tiflash-error日志:
tiflash_error.zip (280.4 KB)
metrics日志:
udp-tidb-TiFlash-Summary_2021-06-07T03_55_44.406Z.json (1.1 MB)
Hi,麻烦再拿以下信息:
select * from information_schema.tiflash_tables order by TOTAL_SIZE desc limit 10 ;
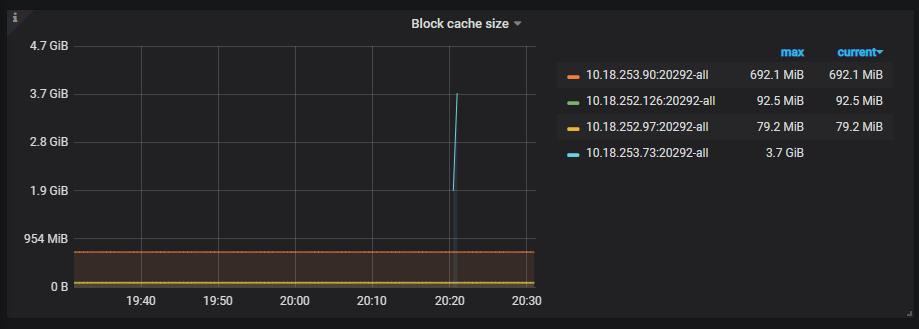
目前看到的问题是,您的业务场景应该是使用较宽的表,v4.0.11 对这个场景没有很好的处理,在数据整理阶段容易使用过多内存。
建议:
-
当前版本修改以下配置,然后观察后续是否还会发现运行时 OOM 的现象。
profiles.default.dt_segment_limit_rows = 500000
profiles.default.dt_segment_delta_limit_rows = 40000
profiles.default.dt_segment_force_merge_delta_deletes = 5
profiles.default.dt_segment_force_merge_delta_rows = 500000
profiles.default.dt_segment_delta_cache_limit_rows = 1000
profiles.default.dt_segment_delta_small_pack_rows = 128 -
在经过充分测试之后,尽快升级到 4.0.13 或 5.0.1 以上版本,我们在这两个版本加入了对宽表的内存使用限制。升级之后,配置内容可以删掉,使用默认值即可。
好的,后续我们测试下更高版本,然后我们先修改下参数再观察下,
有两个问题是:
1. 修改了这几个参数,那两个节点能起来吗? 之前已经用两个新节点替换了,我们不可能一直拿新节点替换换节点,我们想让这两个节点继续正常工作
2.使用了较宽的表是指多大?字段不能太多?还是一行内容太大?我们现在是53个字段,感觉不是很多
- 不一定能启动,因为这个版本还存在上面说的启动使用内存过多的问题。建议尽早升级。
- 您的表的单行数据 700bytes 左右,稍宽,但是属于我们的正常支持范围内。主要的问题是在目前版本,命中了某些 pattern,导致数据整理的时候容易出现内存暴涨。非常抱歉。
1.上面的配置,是修改哪里,修改tiflash配置还是哪的,我搜了下官网没有这几个配置的参数
2.如果我们吧这两个节点内存扩一倍到64G,能起来继续用吗
-
暂时是隐藏配置,不建议自行改动,也不保证长期支持。修改位置可以参考这个配置项:
dt_enable_logical_split -
有条件建议试一下,应该可以的。
1 个赞


这个 case 我们也比较关注,扩容内存后,有什么进度,麻烦在这个帖子里更新一下吧,
害怕扩容完还是不行,我们准备用新节点替换,然后测试4.0.13版本
哦 好的![]()