为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
v4.0.9
【问题描述】
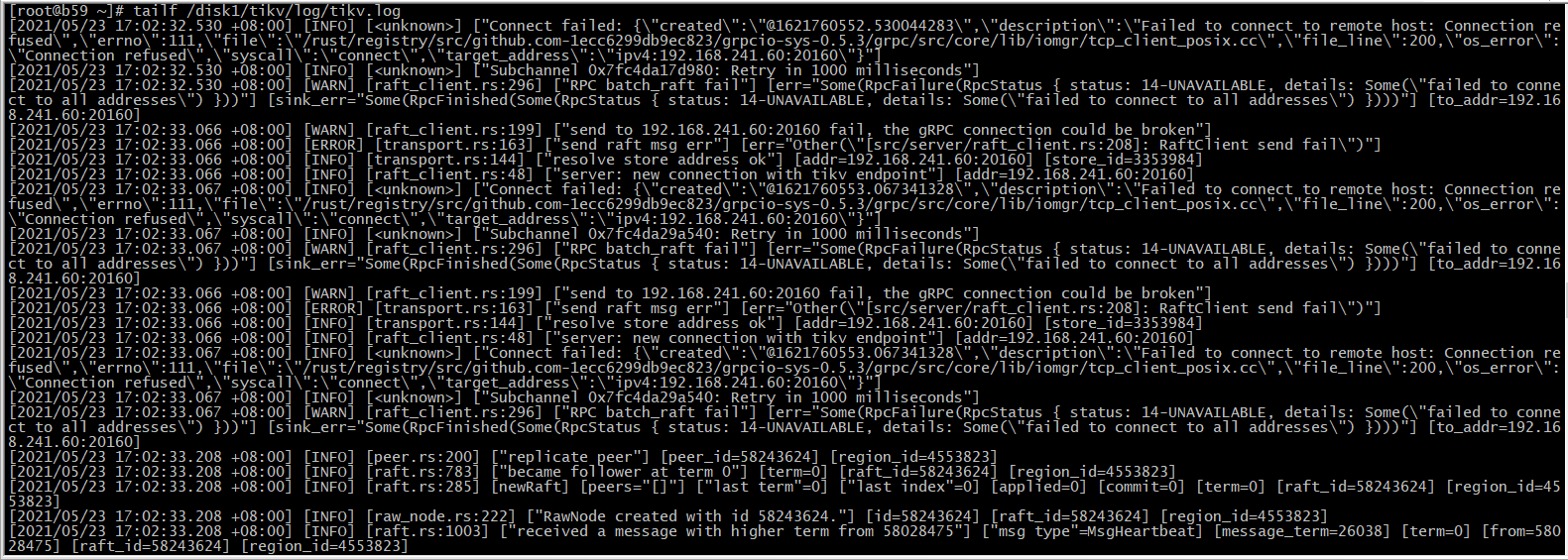
tidb集群中某个tikv节点192.168.241.60 内存故障(某1块内存条故障,拆除故障的内存条,启动) 启动后 TIKV无法启动
报错如下:
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
v4.0.9
【问题描述】
tidb集群中某个tikv节点192.168.241.60 内存故障(某1块内存条故障,拆除故障的内存条,启动) 启动后 TIKV无法启动
报错如下:
这个问题,请查看下下面的内容:
1、确认下 sync-log 参数的设置,一般情况下生产环境应为 true,以确保不会因服务器异常掉电而带来数据、log 没有及时落盘进而出现上述报错
2、请确认下是否当前只有一个 TiKV 节点出现这个问题,如果是可根据情况评估修复方式:
(1)方式 1:将故障 TiKV 节点缩容(变成 tombstome 后),再扩容到集群环境中。该操作方式与普通的扩缩容操作一致,但是需要考虑到扩容 balance 给集群带来的影响,酌情调整 scheduler-limt 以及 store-limit 相关参数。
(2)方式 2:找到受影响的 Region,并依次设置其为 tombstone,尝试启动故障节点。整体操作较为复杂:
1) 打印 Raft 状态机出错的 Region
https://docs.pingcap.com/zh/tidb/v4.0/tikv-control#打印-raft-状态机出错的-region
2) 设置一个 Region 副本为 tombstone 状态
https://docs.pingcap.com/zh/tidb/v4.0/tikv-control#设置一个-region-副本为-tombstone-状态
论坛中类似报错的帖子可供参考,如下:
1,sync-log这个参数具体查看命令是什么呢?
2,没太理解只有1个tikv节点出现这个问题是什么意思呢?是因为1个tikv服务器故障关机,重启后无法启动。
我们其他的tikv节点都正常运行着呀,还需要重启一下看看能不能正常启动吗?
刚刚看了下,其他tikv节点日志都有连接这个故障节点失败的错误
官网有该参数的配置的位置,以及参数的释义,可自行查询:
https://docs.pingcap.com/zh/tidb/v4.0/tikv-configuration-file#sync-log
因为你那边如果只有这一个 TiKV 异常了,这个报错表示,Raft 状态机的状态出现了问题,所以只会影响出现问题的 TiKV 上的若干 Region 副本。Raft 默认 3 副本的情况下,一个副本出现问题,理论上仍然能够选举出 leader ,以供读写。可以使用 pd-ctl + jq 命令来查看 Region leader 的情况,论坛里有相应的文档:
https://asktug.com/t/topic/63086
其他 TiKV 的日志中出现链接这个故障 TiKV 的报错,符合预期,因为这个 TiKV 确实异常了 ~
我看了几个tikv节点的配置文件,好像是把sync-log配置改为false了。。。
有没有命令可以查看实际加载的配置是啥呢?
我用pd-ctl命令查看没有相关的配置呢

这个是 tikv 的配置,使用 pd-ctl 看不到相关的配置,符合预期。
该参数可以通过下面两种方式确认配置情况:
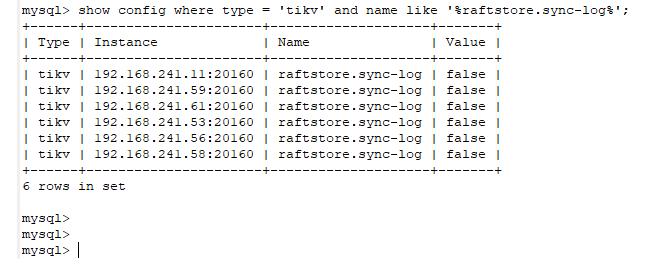
1、 show config where type = 'tikv' and name like '%raftstore.sync-log%'
2、过滤 tikv.log 的 welcome 关键字及其后若干行,然后找到集群启动时加载的参数
你好,确实是false了,这个集群是之前的同事部署的。下面需要怎么做呢?
修复这个问题的步骤,参考楼上的回帖,根据当前的情况选择对应的操作方法:
调整 sync-log 参数的设置,可以参考下面的文档。尝试动态调整:
https://docs.pingcap.com/zh/tidb/v4.0/dynamic-config#在线修改-tikv-配置
需要注意下述描述
TIKV节点服务器异常关机,都会引发这个问题吗? 不会每次tikv节点异常掉线都需要重新扩容吧?
请看下楼上关于造成这个报错的可能的原因,以及处理的办法,方案一是扩缩容,方案二是在原有的基础上就行修正,可根据情况选择对应的方案~
好的,我现在集群中所有tikv节点,sync-log都是false,现在是先把问题节点重新缩容再扩容,成功后,
再整体修改集群的sync-log配置是吗?
先修改,还是先修复问题节点,这个有先后顺序吗影响吗?
理论上,严格意义上,这两个操作没有前后顺序的要求。但是建议优先调整 sync-log 参数,避免再次发生该问题。下述操作步骤仅供参考,建议根据实际情况进行选取,请评估:
1、确认当前异常的 TiKV 节点的状态,如果是 down 可以先缩容,缩容后变为 offlline 状态,当变为 tombstone 表示缩容成功:
2、调整 sync-log 参数,但是需要考虑设置为 true 可能会带来的写入性能的下降,因为增加了 disk fsync 的操作。
3、扩容 tikv 节点,这个过程中需要考虑到,扩缩容对集群性能的影响。如果允许,可根据情况,如业务高低峰,适当调整 scheduler-limit 以及 store-limit 相关参数~
https://docs.pingcap.com/zh/tidb/v4.0/configure-store-limit#store-limit
https://docs.pingcap.com/zh/tidb/v4.0/pd-configuration-file#leader-schedule-limit
好的,谢谢~
![]()
你好,最近我们集群有2台机器出问题,另一台TIDB服务器风扇坏了,刚换好,当时没法处理tikv这个问题
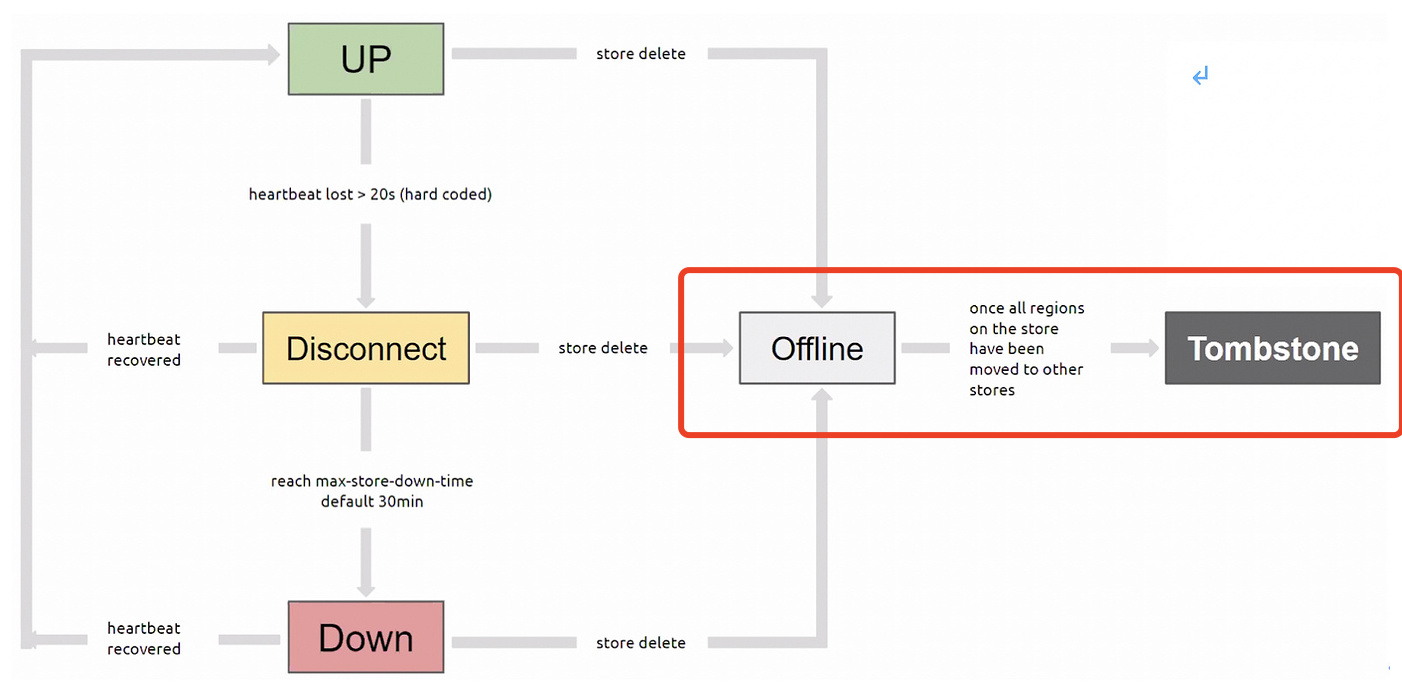
刚刚准备处理,发现那个tikv节点 状态变成Tombstone 了,是tidb集群有机制,tikv节点多长时间不连接,就会变成Tombstone吗?
问题期间,没有过删除修改的操作。
有1个节点故障,tidb/grafna/prometheus/alert 有重启过故障节点的这些组件 。
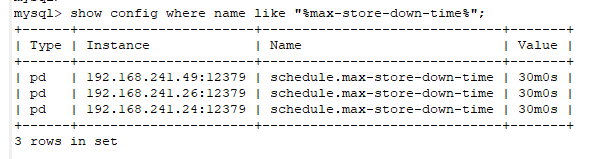
这个配置是默认的30分钟,没修改过
没有执行过pd-ctl delete store这个操作, 但现在变成了Tombstone 状态,这个正常吗?是系统自动处理的吗?
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。