为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
5.0.0
【问题描述】
用dumpling存量同步后(用tidb-lightning导入),从metadata里获取到Pos: 425023074565619717 ,将drainer的commit_ts配置成这个值,现在看,数据能实时同步,但存库里数据量没有上游多,请问是什么原因?谢谢!
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
5.0.0
【问题描述】
用dumpling存量同步后(用tidb-lightning导入),从metadata里获取到Pos: 425023074565619717 ,将drainer的commit_ts配置成这个值,现在看,数据能实时同步,但存库里数据量没有上游多,请问是什么原因?谢谢!
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
辛苦确认一下以下几点:
gc=7
lightning导入完后,是隔了两天再启动的binlog
这个 gc 表示本地的 binlog 文件保留的时间,不是 tidb 的 gc 时间。默认情况下 gc-life-time 和 interval time 默认是 10 分钟。
如果是在 lightning 导入数据两天后再启动 tidb-binlog,属于下面哪种情况:
1、pump 始终是启动的状态,但是 drainer 是导入数据两天后才启动的
2、pump 和 drainer 都是在数据导入两天后才启动的
如果是情况 1,可以将下面的信息提供下:
1)pump 以及 drainer 的 配置文件,
2)两天后指定 drainer commit_ts 配置,并启动。该时间点前后一小时的 pump 以及 drainer 的 log
3)select * from mysql.tidb 的结果
如果是情况 2,那么 tidb server 的参数配置的是 false 吗?如果是那么在数据导入完成和 drainer 启动两天之间的数据会丢失:
https://docs.pingcap.com/zh/tidb/v4.0/tidb-configuration-file#ignore-error
谢谢!应该是属于情况2,我是lightning导入两天后再启用的binlog(之前binlog是false),同时扩容pump和drainer
现在我可以怎么弄让数据一致?
我想先停掉binlog,再把下游数据清掉后,用dumpling和lingning导入存量数据,再启用binlog,请问具体要怎么操作?pump和drainer的数据要不要手动清理?
如果属于情况 2,那么确实是需要重新开始做全量和增量数据来实现数据的一致性了。
这个情况下,参考步骤如下(仅供参考):
1、停止 drainer
2、清理下游已导入的目标库数据
3、清理 checkpoint 信息,取决于配置文件的参数设置:
file 文件
mysql/tidb 实例
4、全量导出原目标库数据
5、目标库数据全量导入下游 tidb/mysql
6、drainer 设置数据同步起始 ts
7、启动 drainer
8、验证数据同步状态
另外,你这边是 5.0 版本,4.0 及以上版本,可以尝试使用 ticdc,ticdc 具有高可用等特性(tidb-binlog 的 drainer 没有高可用):
https://docs.pingcap.com/zh/tidb/stable/ticdc-overview#ticdc-简介
谢谢!请问是不是这样:
1、停止 drainer
tiup cluster stop xxx -R drainer
2、清理下游已导入的目标库数据
drop table xxx;
3、清理 checkpoint 信息,取决于配置文件的参数设置:
file 文件
mysql/tidb 实例
这里要怎么操作?
4、全量导出原目标库数据
dumpling导出
5、目标库数据全量导入下游 tidb/mysql
lightning导入
6、drainer 设置数据同步起始 ts
commit_ts 设置为dumpling里metadata种的pos值
7、启动 drainer
tiup cluster start xxx -R drainer
8、验证数据同步状态
验证
你说的第3步没太明白,我drainer之前的配置:
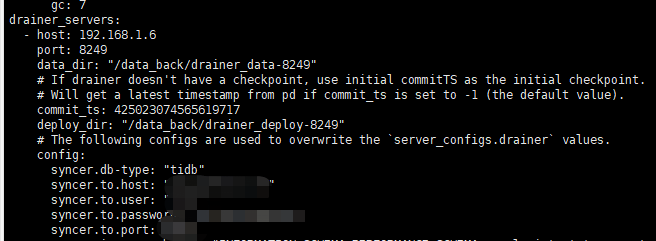
建议看下 drainer 的配置文件,syncer.to.checkpoint 对应部分的参数哈:
https://docs.pingcap.com/zh/tidb/stable/tidb-binlog-configuration-file#syncertocheckpoint
tiup cluster edit-config xxxx 修改不了drainer的commint_ts, 报错:
New topology could not be saved: immutable field changed: Drainers.0.CommitTS changed from ‘425023074565619717’ to ‘425153765853888513’
全量导入后是不是可以不用改drainer的这个参数,直接启动drainer就可以? 谢谢!
直接启动 drainer 会按照下面的方式来进行数据的增量同步:
这个如果方便,可以将完整的 tiup edit-config 的内容上传下,以及完整的报错信息 ~
另外,下游的 drainer 上次同步的生成的 checkpoint 的信息已经清理了吧 ?
tidb_dl.config (5.8 KB)
commit_ts: 425023074565619717
tiup cluster edit-config xxxx 修改不了drainer的commint_ts, 报错:
New topology could not be saved: immutable field changed: Drainers.0.CommitTS changed from ‘425023074565619717’ to ‘425153765853888513’
上面就是完成报错信息
两外,你说下游的checkpoint是指哪个?我找了下文档没找到: 刚看到了下游里有个tidb_binlog,是不是要把这个删掉?
我把dariner停了后,清掉下游的数据,再用lighning同步存量数据,因为修改commit_ts失败了,就没管了,直接启动drainer,没有其他操作了,麻烦指导下,这样有没有啥问题?谢谢!
如果你那里下游有 tidb_binlog 这个库,那么大概率是把 checkpoint 保存到 mysql/tidb 里面了,请把 tidb_binlog.checkpoint 表 drop 掉,然后再配置 drainer 的 commit_ts:
https://docs.pingcap.com/zh/tidb/v4.0/tidb-binlog-faq#什么是-checkpoint
下游数据清理后,drop掉了checkpoint表
通过tiup cluster edit-config xxx 配置commit_ts时,还是报下面的错:
New topology could not be saved: immutable field changed: Drainers.0.CommitTS changed from ‘425023074565619717’ to ‘425156470210035715’
请问要怎样才能修改commit_ts参数?谢谢!
可以了,直接编辑.tiup/storage/cluster/clusters/{cluster-name}/meta.yaml 就可以改,谢谢!
可以了,再请教下,如果下游故障了,例如掉电了之类的,不通,会对drainer有啥影响?下游恢复后需要做什么操作不?谢谢!
如果下游故障了,那么 drainer 写入数据到下游会失败:
如果上游故障了,可能处于数据不一致的中间状态,但是可以通过 relay log 来解决这个问题:
如果 drainer 故障了,那么数据同步会停止,因为 drainer 没有高可用:
如果集群中有 2 个或以上的 pump ,其中一个故障,那么理论上不影响数据同步:
因为 drainer 没有高可用,pump 提供有限高可用,建议评估下 TiCDC,TiCDC 在这块做了很好的优化和改进 ~
如果这个问题结束了,还有其他新的问题,可以重新开帖哈 ~
谢谢!
![]()
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。
