为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】4.0.12
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】4.0.12
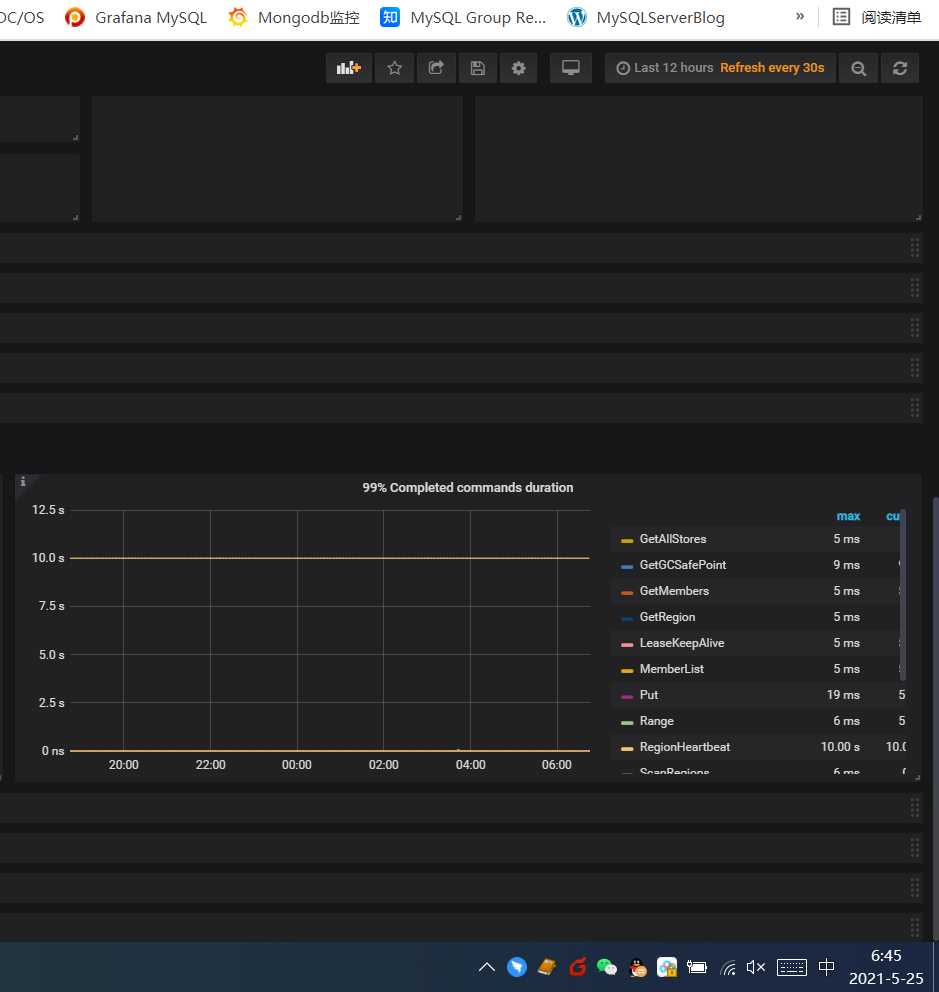
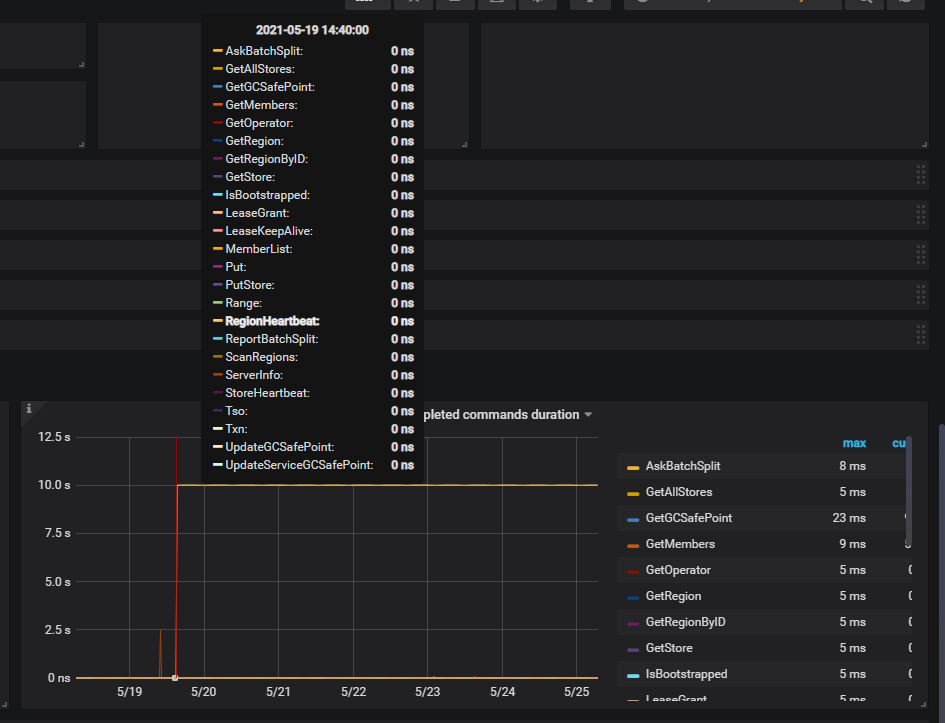
请问,当前 region heartbeat duration 周期性增长,对你那里的业务请求造成了什么影响,整个集群的 duration 升高了吗?
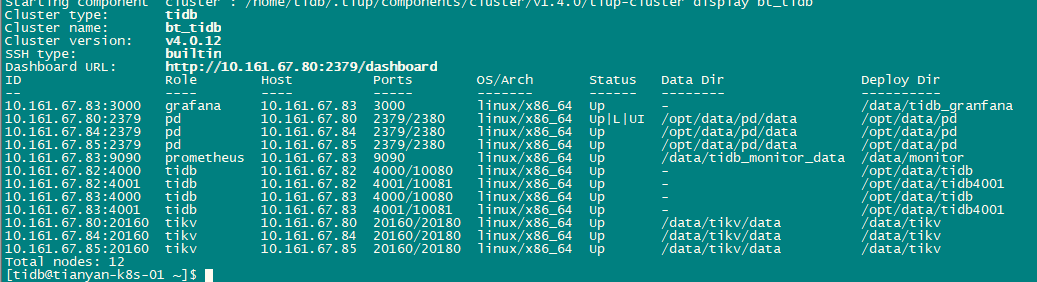
可以把 TiKV-Details 以及 PD 的 grafana 的监控导出下 ~
麻烦参考帖子导出下 over-view pd tidb 和 tikv-detail 的完整监控,多谢。
Downloads.rar (2.8 MB)
你好 监控导出见附件
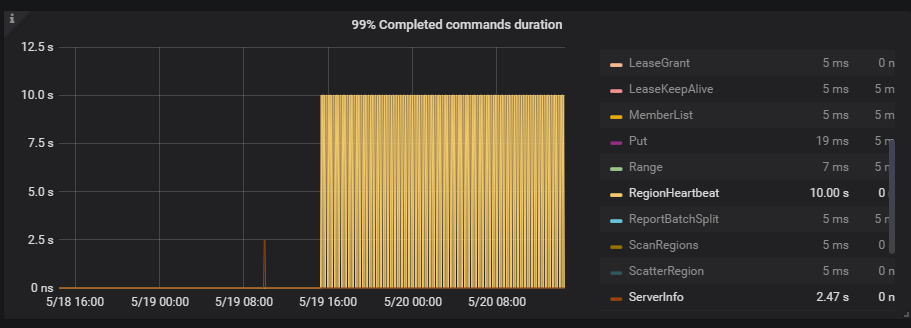
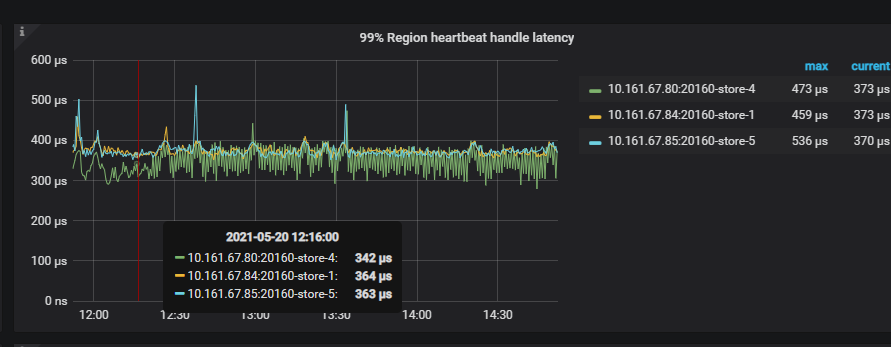
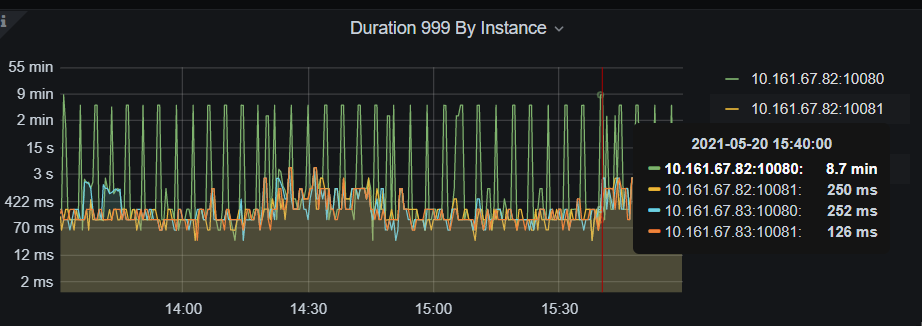
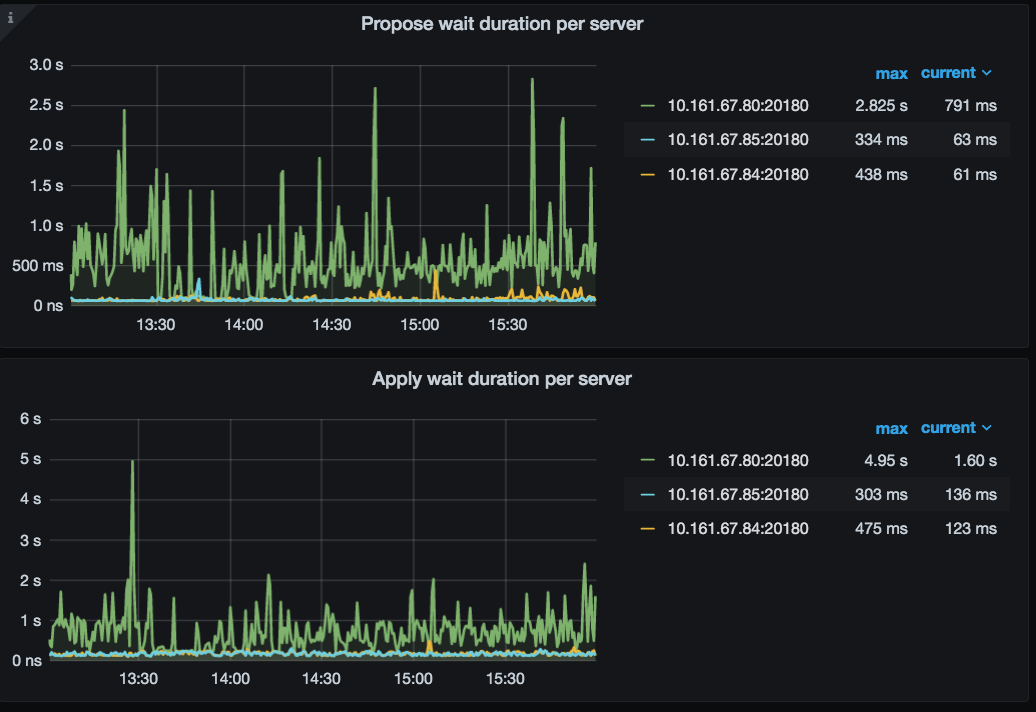
当前你上面的 Region 的心跳上报慢, 每隔 5 分钟会增到 10 秒持续 4 分钟。这个理论上,不会影响数据写入的效率。反过来,数据写入生成 Region 后,会出现 Region 向 PD 上报心跳的现象。一句话概括,Region heartheat 可能是 load data 操作后,导致的现象,而不是问题的原因 ~
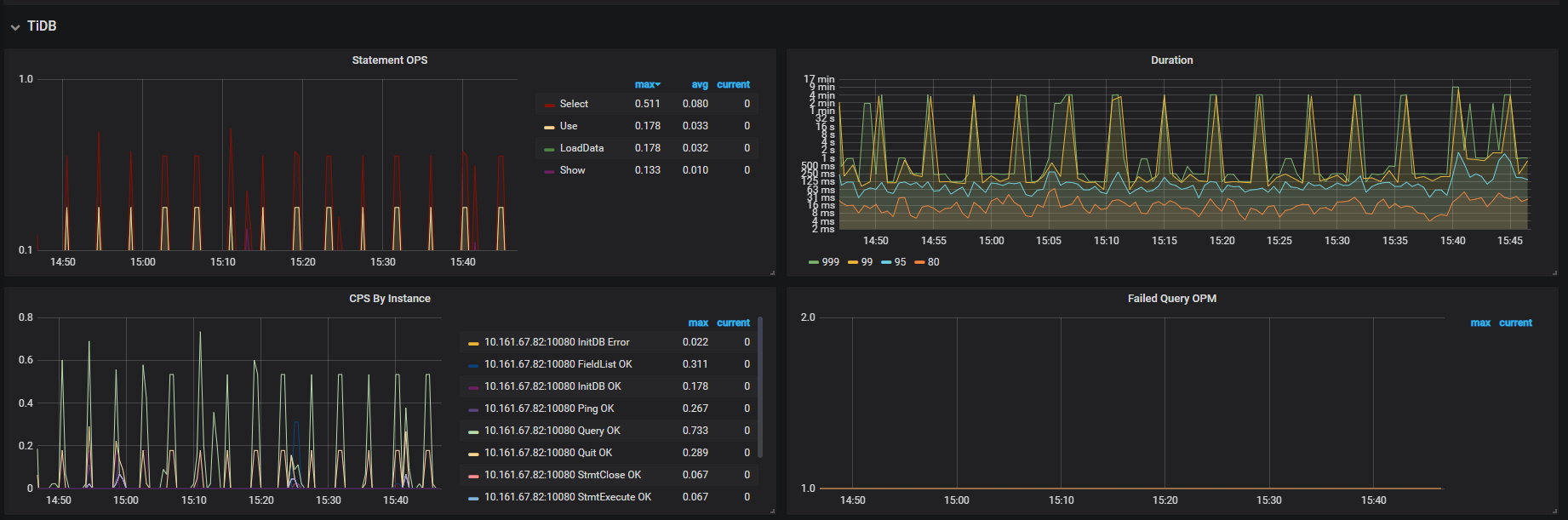
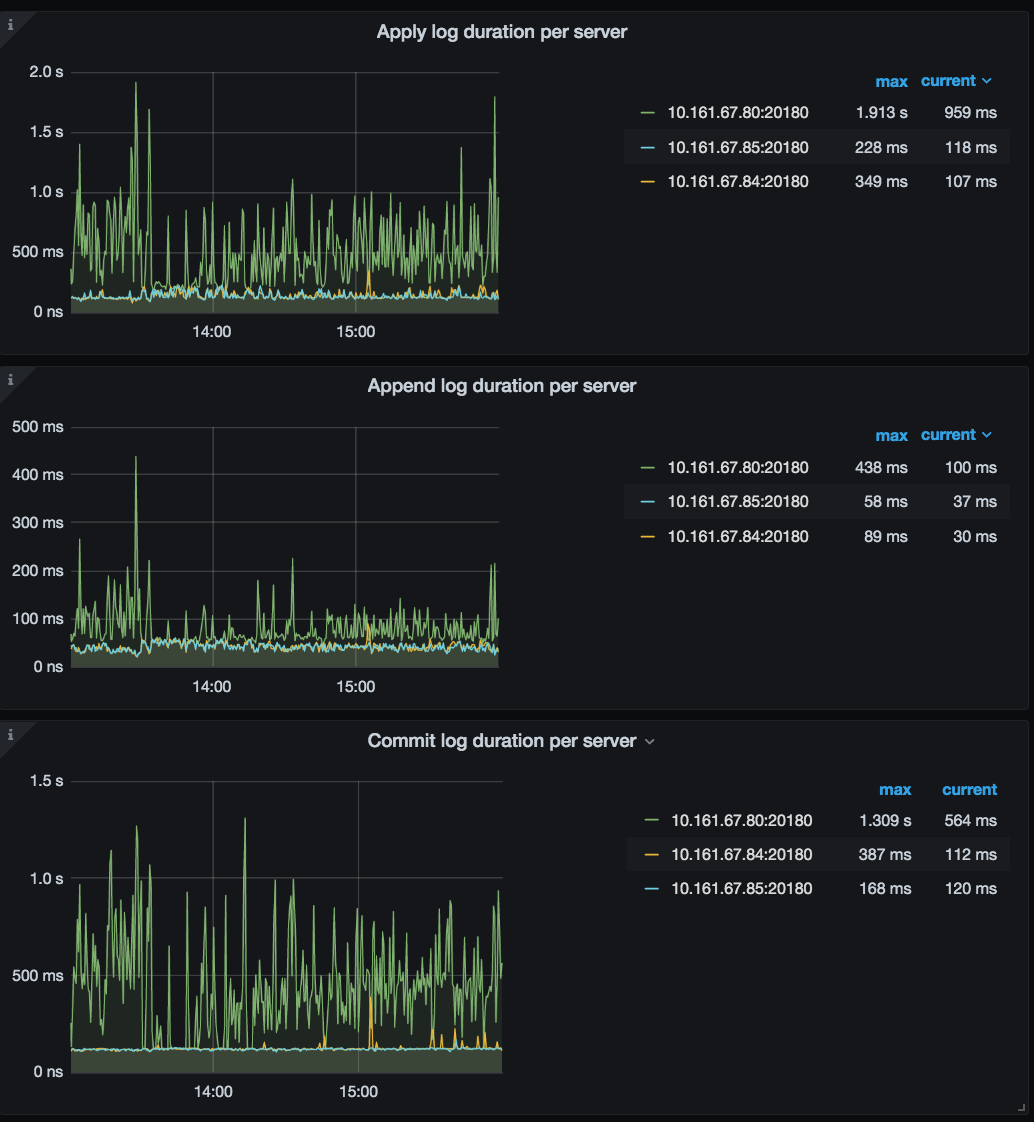
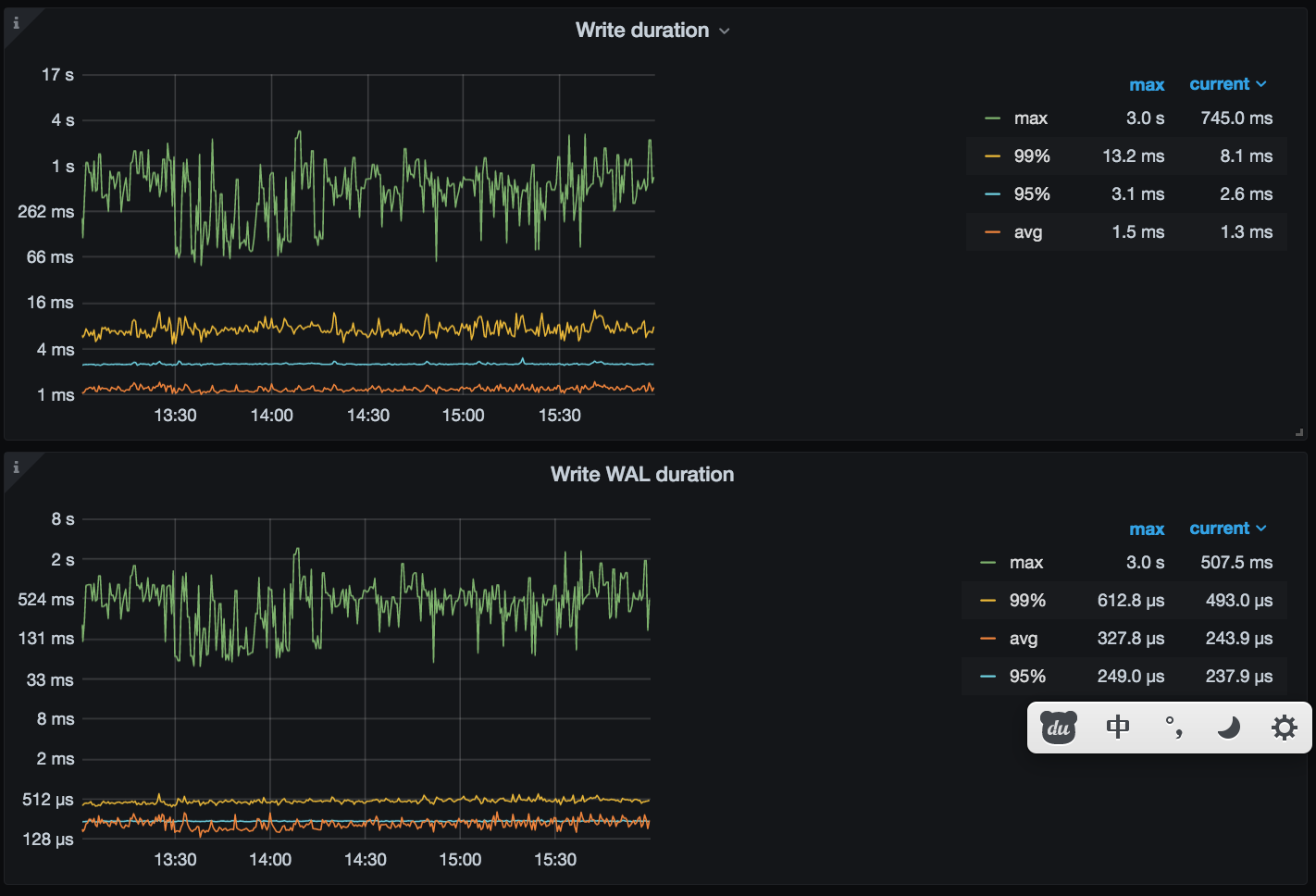
回归到问题本身,看上面 TiDB 监控周期性升高是大概 5 分钟一次,和你那里每隔 5 分钟 load data 数据有关。下述监控中 TiKV-Details 监控可见,整体写入耗时比较久,apply wait ,append ,propose wait,apply log duration ,raft-kv 的 wal 和 write duration 耗时都比较高:
如果计划详细的定位下,写入慢的原因,那么可以参照下面的 『写慢』排查文档看下:
回归下问题,你那里是想定位导入数据期间 tidb duration 升高,写入数据慢的问题,还是想弄清楚 pd 某一个监控项的释义,比如 region heartbeat duration 持续或者间歇性升高的原因?
问题是找到增长到10秒的原因
嗯嗯,辛苦把 5 月 19 号 ~ 现在的 PD 的 grafana 监控数据导出下哈 ~
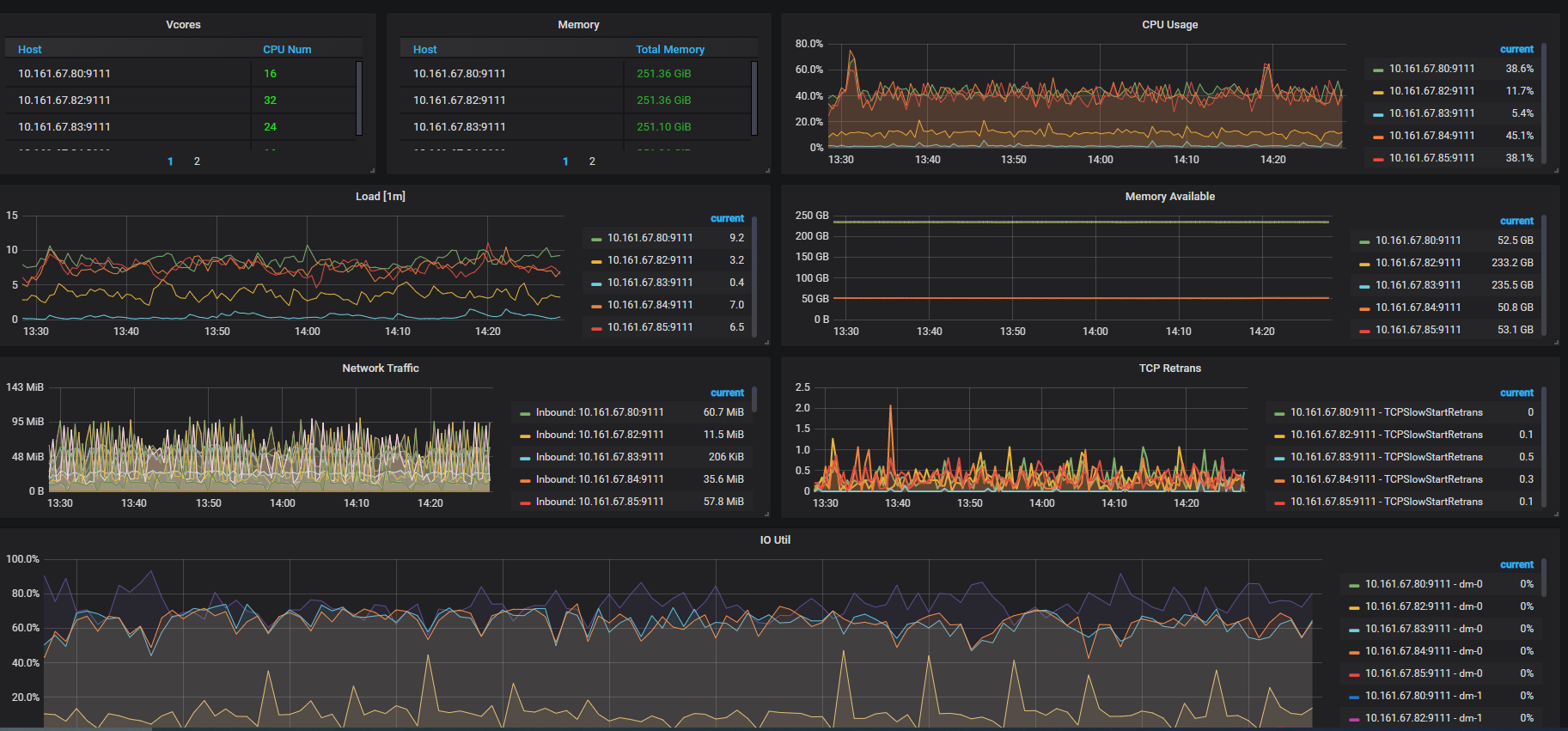
还有 PD 所在的服务器的 node-exporter 监控,也导出下,时间段 5 月 19 号 ~ 现在的 ~
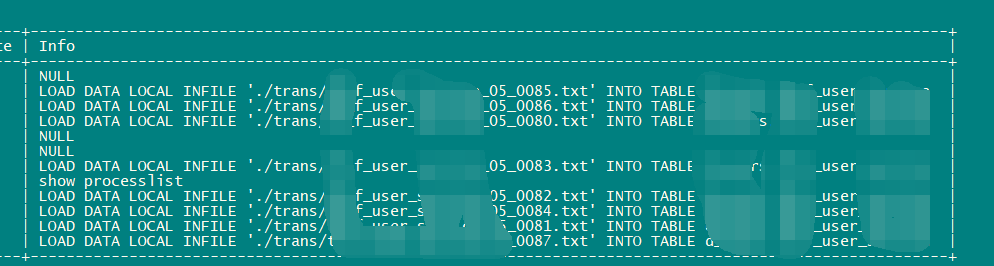
另外,你那里大概在哪个时间点停止批量导入数据的 ?