Tidb版本:5.0.6
DM版本:5.3.0
背景:
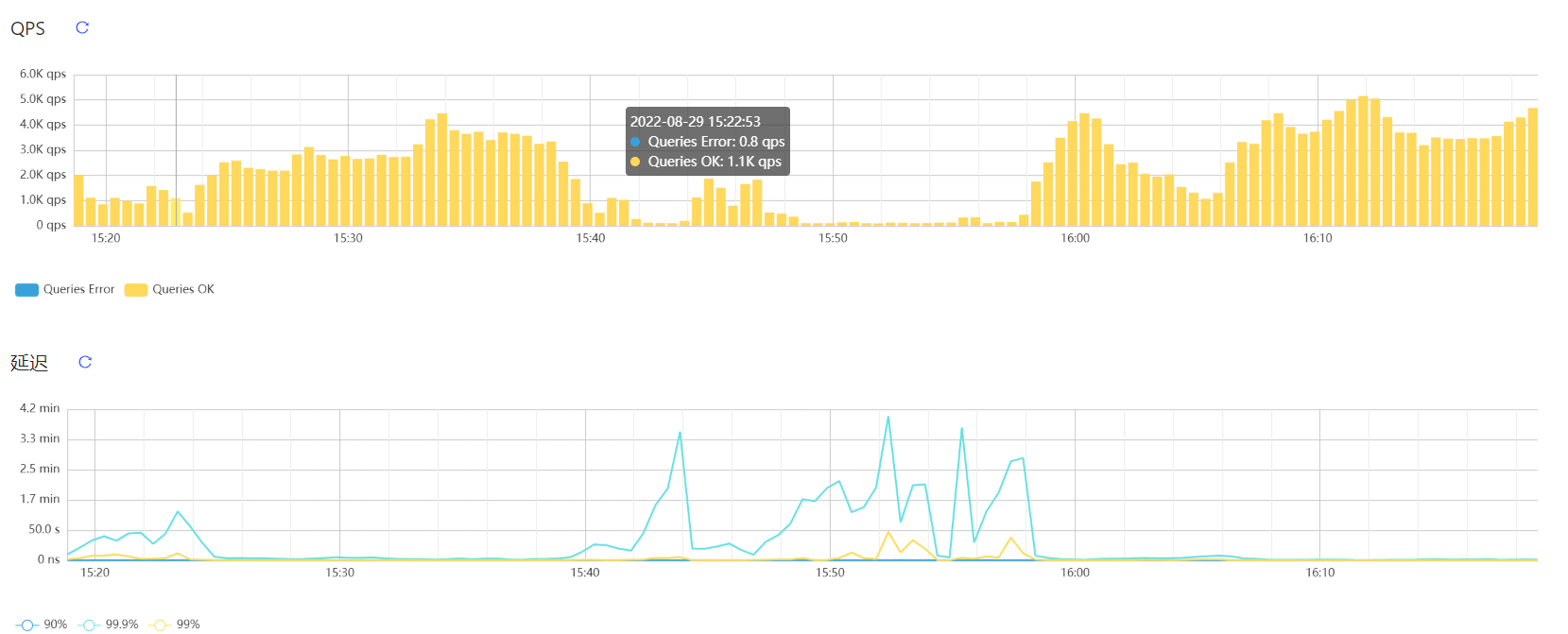
数据通过DM同步至tidb,出现写入异常,dashboard页面的延迟截图,请问可以根据什么信息排查造成延迟的原因?
看看slow log 看看有没有什么慢查询。或者看看集群的资源使用情况
你要确认下是 DM 性能不足,还是 tidb 的性能不足,先排查这个吧
如果你有安排了prometheus 的监控,很容易看到 IO 相关的性能指标的
延迟的确比较大,硬件配置如何呢?
配置:
cpu 40核
内存:128G
磁盘: nvme
网络:万兆
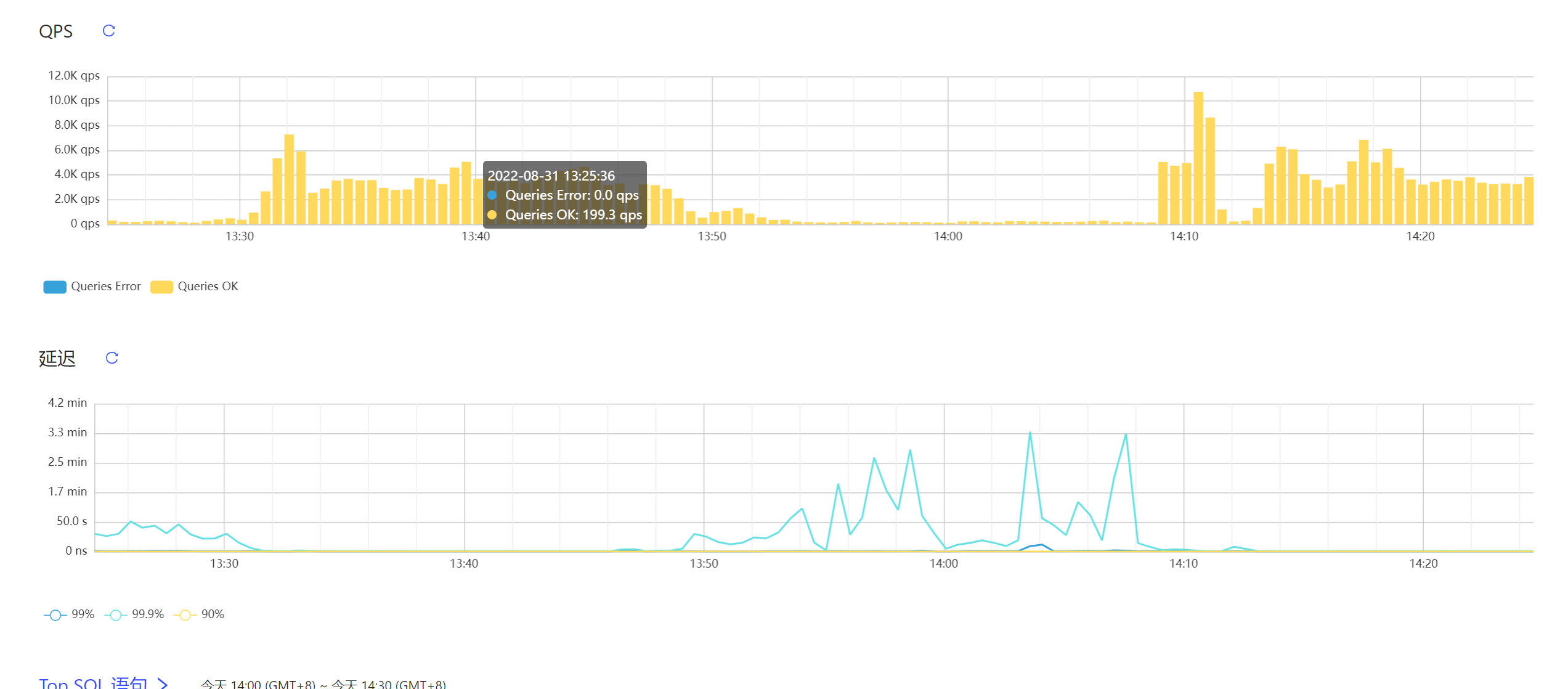
以下是目前排查获得的信息:
1.dm在延迟异常时,出现过写写冲突的问题,集群模式用的是悲观锁,尝试过关闭dm,延迟还是出现。
2.异常时错误日志中出现"[gc worker] delete range failed on range,正常写入阶段没有。
tidb-pro-TiDB_2022-08-31T06_22_46.275Z.json (3.7 MB)
感觉可能是tidb哪里有问题, 导致这段时间数据无法写入,io方面没发现什么异常问题。有没有什么办法可以看到引起延迟的异常情况?
通过 prometheus 查下 tidb 所有的节点 请求和 处理的状态指标

https://docs.pingcap.com/zh/tidb/stable/grafana-tidb-dashboard
捡回一条狗命, 根据上面提示,找到当时有一台tidb 在延迟较高的时候,KV Transaction OPS 值一条都没有。把这台机器下掉,没有在出现那个延迟问题,机器初步判断是网卡的问题。
谢谢大佬~
网卡问题 流量监控应该能看出来
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。