【 TiDB 使用环境】线上
【 TiDB 版本】5.0.6
【遇到的问题】
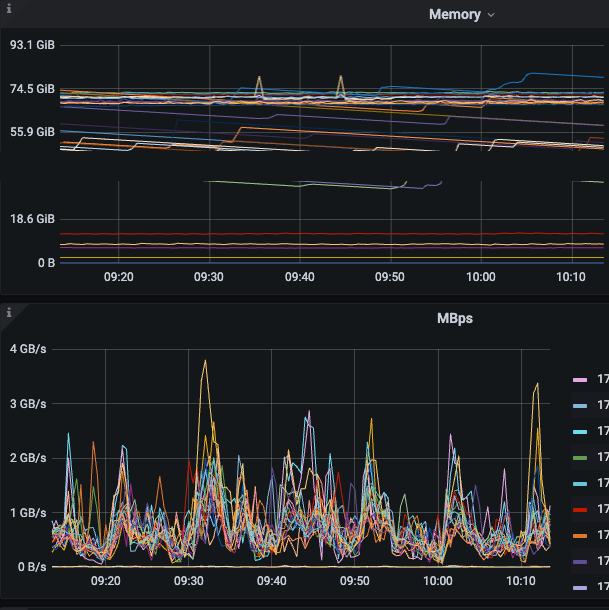
tidb日志报gc work is too busy,查询gc safe time正常,目前是数据不回收导致数据增长太快,不知道如何解决
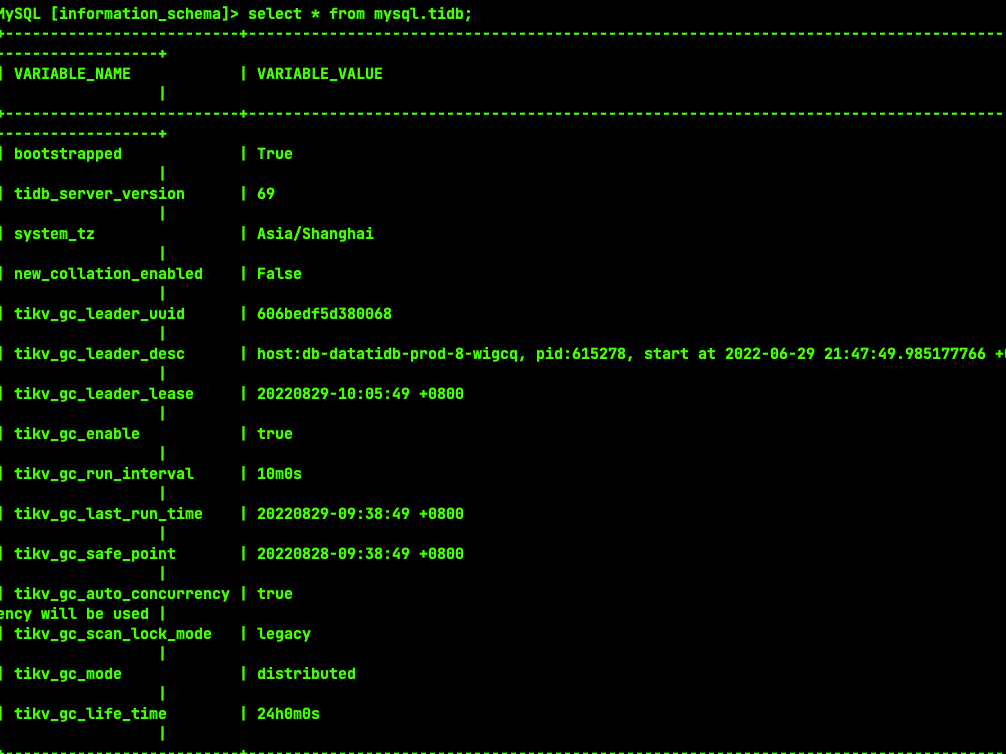
但是GC一次需要34分钟到1小时
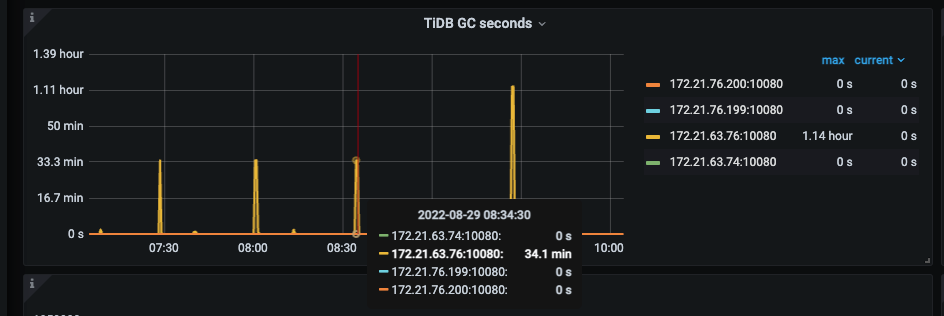
业务上会每隔5分钟做10个左右的truncate,但是没看到有unsafe destroy range

【复现路径】
做过哪些操作出现的问题【问题现象及影响】
【附件】
【 TiDB 使用环境】线上
【 TiDB 版本】5.0.6
【遇到的问题】
tidb日志报gc work is too busy,查询gc safe time正常,目前是数据不回收导致数据增长太快,不知道如何解决
做过哪些操作出现的问题【附件】
tikv_gc_lift_time 24小时 太长了吧。。
tikv_gc_lift_time 比查询最大时间大点就可以,1小时左右都可以。。
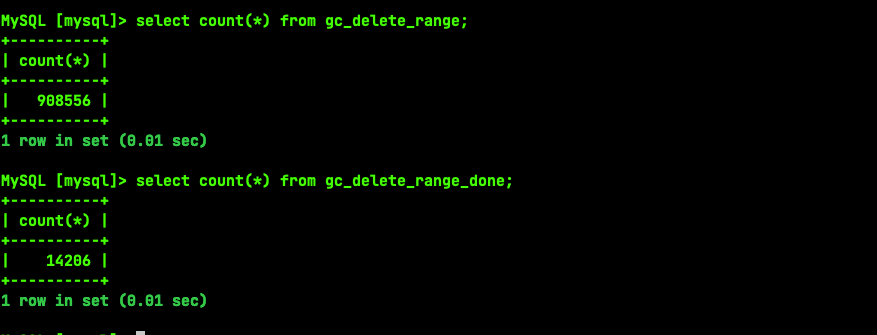
看下mysql.gc_delete_range gc_delete_range_done,里面记录truncate/drop后GC的进度,如果没有清理,估计你这可能是碰上bug了
TiDB 节点大量[gc worker] delete range failed 报错信息 - #6,来自 h5n1…
找时间使用tikv-ctl 手动compact下
tikv-ctl --host tikv_ip:port compact -d kv -c write
tikv-ctl --host tikv_ip:port compact -d kv -c default
tikv-ctl --host tikv_ip:port compact -d kv -c write --bottommost force
tikv-ctl --host tikv_ip:port compact -d kv -c lock --bottommost force
请教下这个操作的目的和风险大概是怎么样 搜了文档没咋详细解释
执行时间较长,资源消耗比较高
可能数据量太大,GC清理不过来
这个会回收之前的GC数据是么 单TiKV 2T数据大概会执行多久?
嗯 看着是清理不过来。 你也是compact么
这个得看系统性能了,可以找个低峰时间试试
没啥低峰,晚上任务更重,早上数据查询更重要!![]() 可能也就中午2个小时低峰,怕完不成
可能也就中午2个小时低峰,怕完不成
等我在我的环境跑一遍看看时间
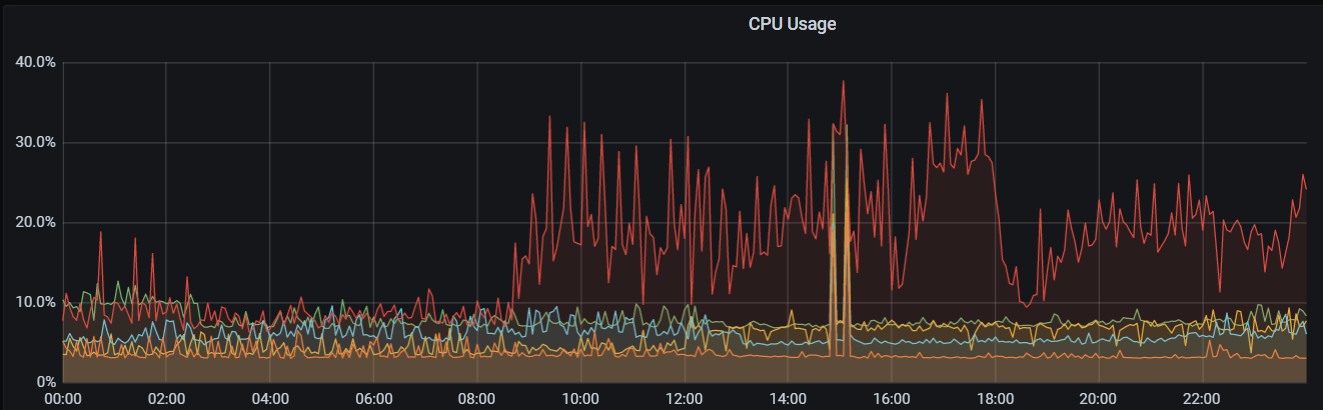
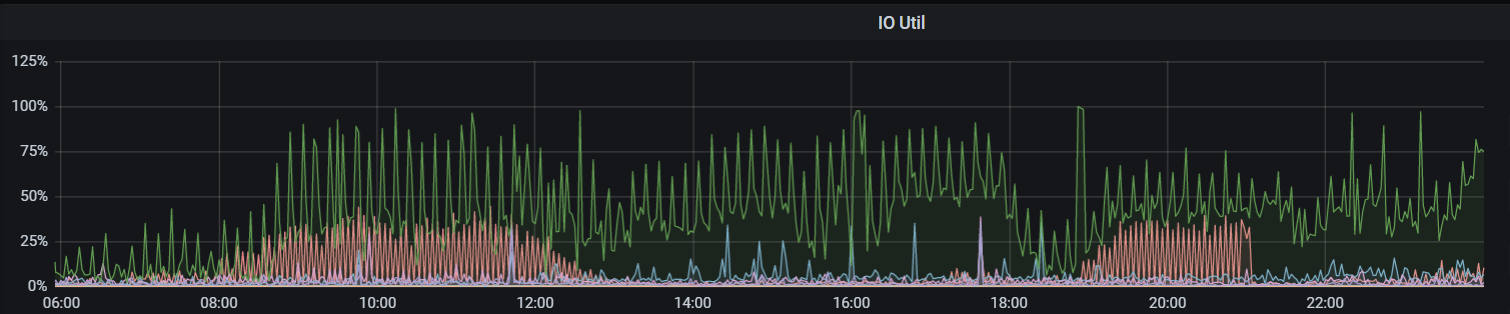
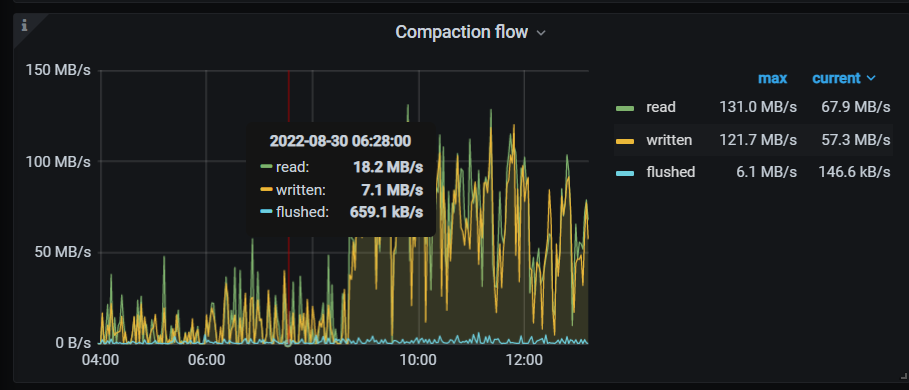
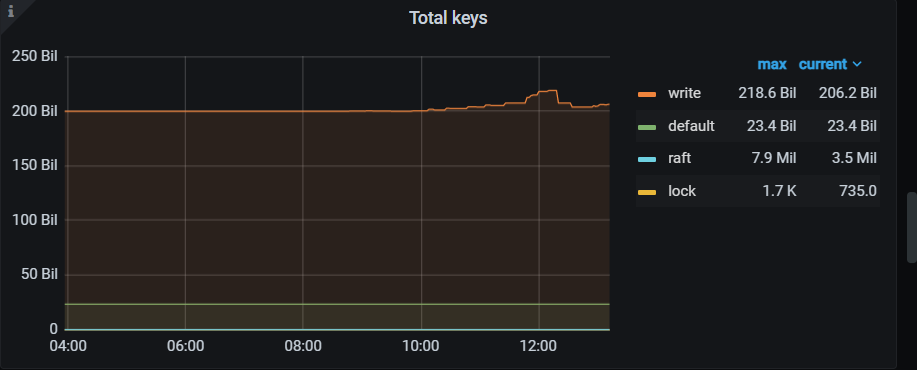
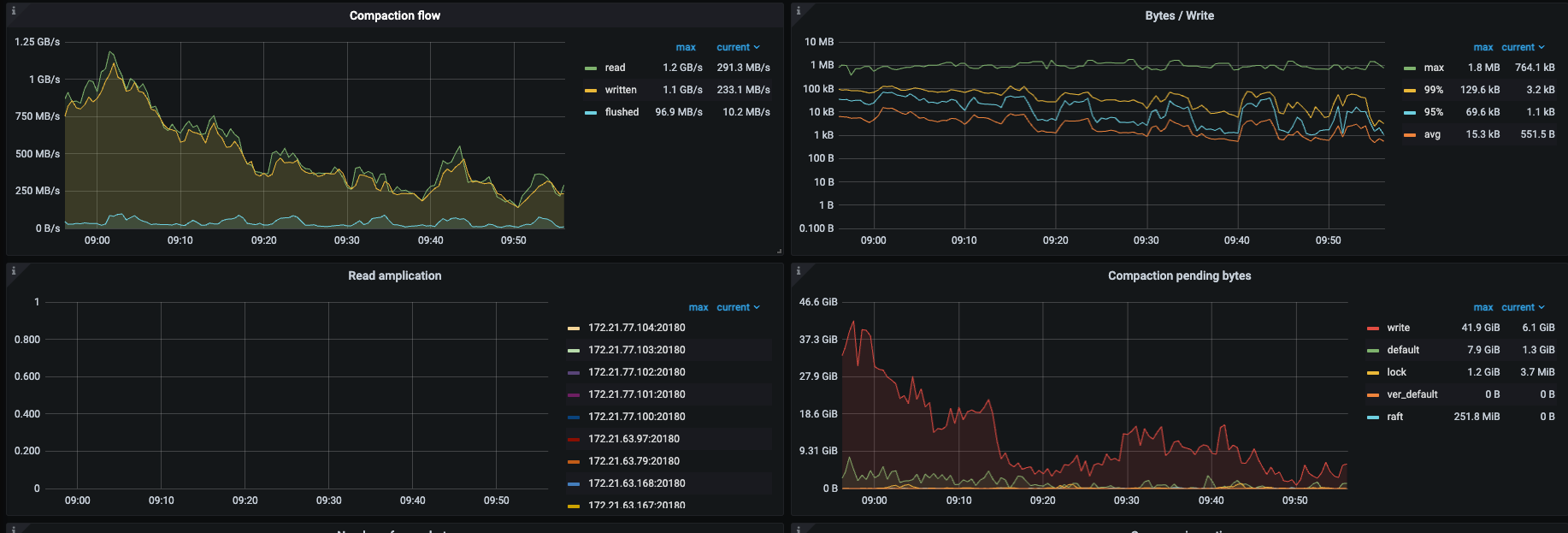
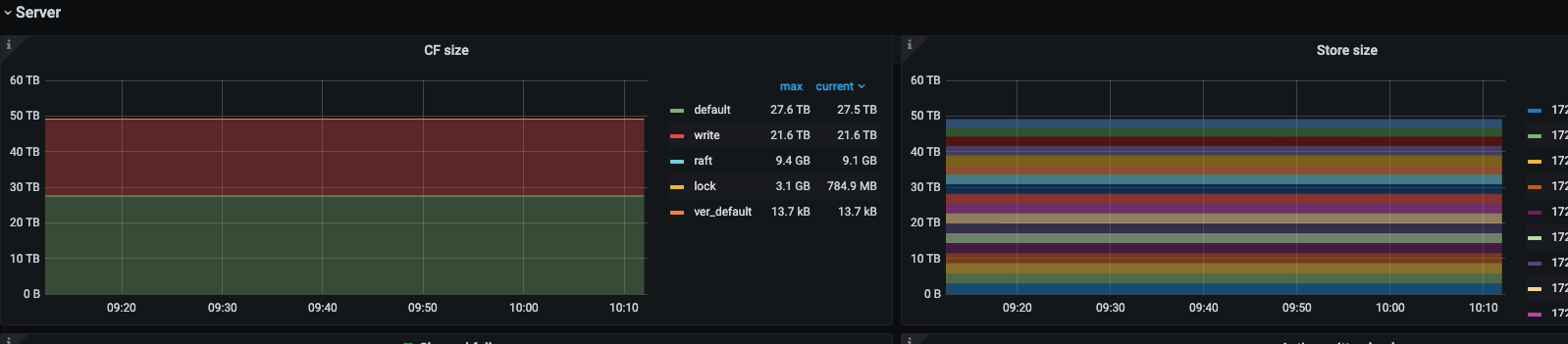
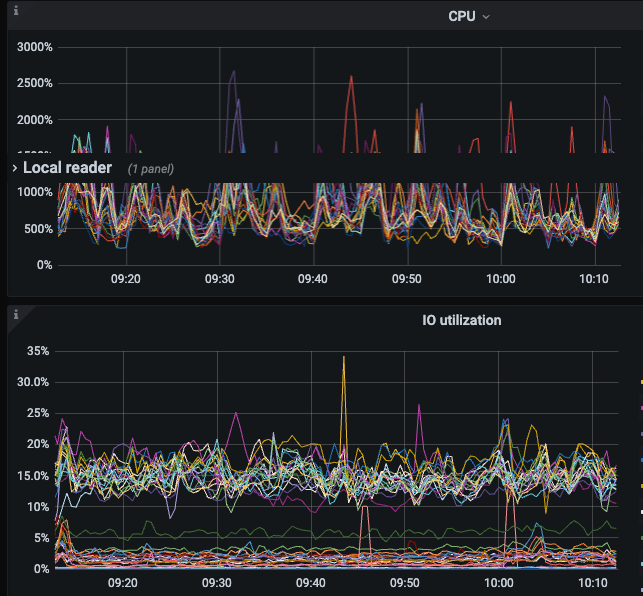
我这个跑完了 5.4T 5tikv sas盘,都是insert没有update/delete所以空间没释放,下面是时间消耗和资源情况,没有指定–threads 磁盘IO还好,主要rocksdb CPU 利用率有增
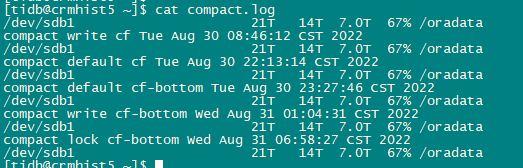
应该kill了就行,有个–threads 默认是8
或者说这个问题升级到哪个版本能解决吗? 升级有额外的风险么,看文档都是说一条命令,也试过小集群的升级,不知道大集群有没有啥坑或者额外的问题
嗯嗯 好的 谢谢大佬~~