【 TiDB 使用环境】线上
【 TiDB 版本】v4.0.10
【遇到的问题】集群整体sql响应时间上升
【问题现象及影响】
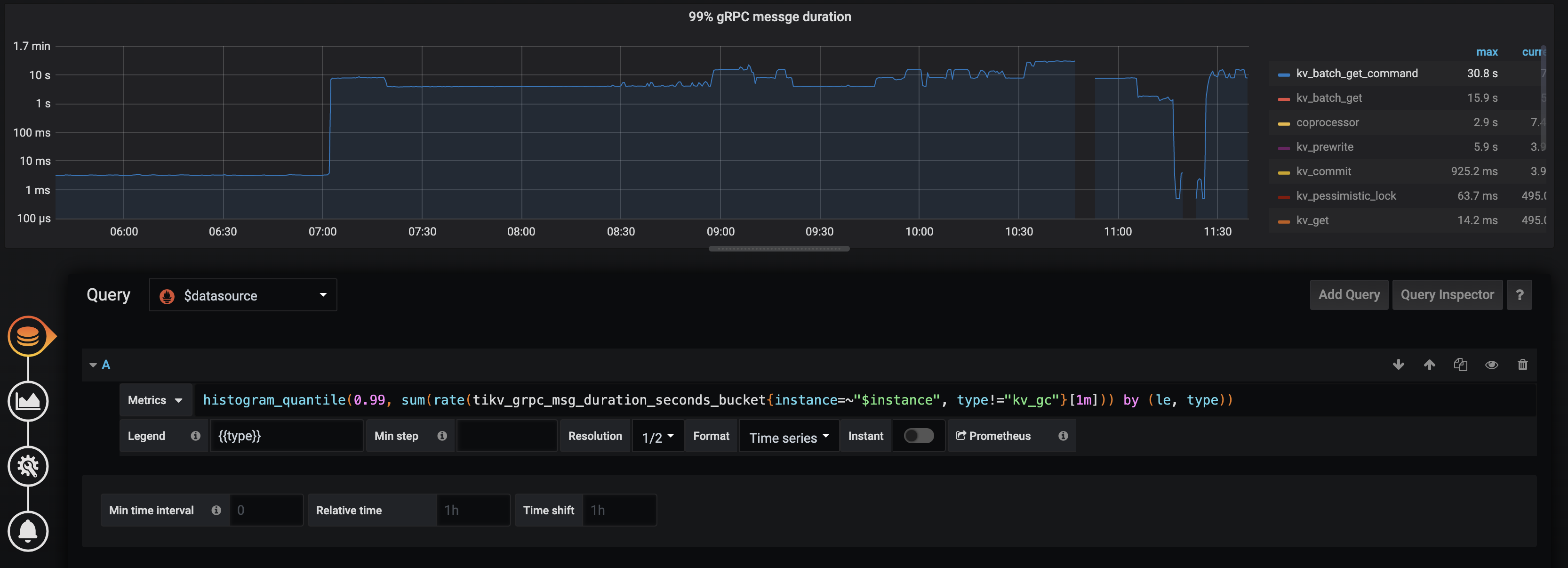
业务反馈sql超时,查看information_schema.cluster_slow_query表发现耗时较久的sql都是走的uk,监控上看99% gRPC message duration-kv_batch_get_command较高,正常是毫秒级,上升到了秒级别。
机器负载没有到达瓶颈。
【附件】


各个组件的 都是v4.0.10版本。
【 TiDB 使用环境】线上
【 TiDB 版本】v4.0.10
【遇到的问题】集群整体sql响应时间上升
【问题现象及影响】
业务反馈sql超时,查看information_schema.cluster_slow_query表发现耗时较久的sql都是走的uk,监控上看99% gRPC message duration-kv_batch_get_command较高,正常是毫秒级,上升到了秒级别。
机器负载没有到达瓶颈。
【附件】
各个组件的 都是v4.0.10版本。
版本、SQL、表结构、执行计划、问题现象、监控是否异常指标,详细情况说说吧
嗯,编辑中
trace select 语句,看下具体耗在哪个部分 ?
https://metricstool.pingcap.com/#backup-with-dev-tools 按这个导出下overview \tidb\pd\tikv detail\的监控 ,要点击expand等所有面板展开 数据加载完在导出
±-----------------------------------------±----------------±-------------+
| operation | startTS | duration |
±-----------------------------------------±----------------±-------------+
| trace | 15:46:27.532819 | 201.281889ms |
| ├─session.Execute | 15:46:27.532825 | 508.492µs |
| │ ├─session.ParseSQL | 15:46:27.532831 | 31.272µs |
| │ ├─executor.Compile | 15:46:27.532894 | 348.389µs |
| │ └─session.runStmt | 15:46:27.533256 | 52.253µs |
| └─*executor.BatchPointGetExec.Next | 15:46:27.533348 | 200.51194ms |
| └─rpcClient.SendRequest | 15:46:27.533389 | 200.391491ms |
±-----------------------------------------±----------------±-------------+
TiDB4.0-Cluster-TiKV-Details_2022-08-26T07_59_45.041Z.json (886.6 KB)
大佬看看这个是否有数据
没有,导出来文件少说也得几兆
我记得4.0.9 有个point get的优化,v4.0.8 之前 不会发生cast 然后4.0.9就会, 你看看你的索引列 类型,和你传的类型是不是一样的
都是数字型的,没有隐式转换
监控项有点多,估计笔记本内存不够,大佬看看导出一些需要的监控面板吧
7:00中时 ops 里use有突增,跟grpc messsage时间比较吻合,这个是正常的吗? 看看tikv监控的thread cpu 、磁盘IO、网络延迟。另外你这个集群是跑在笔记本里的?
这个use应该是use db吧,sql超时应用应该有重试,连接数也是涨高了,新建连接后,use db,然后查询数据
不是,笔记本上查看prometheus监控的,集群跑在物理机上的,配置是64C+256内存,4台物理机
tidb moni
TiDB4.0-Cluster-TiDB_2022-08-26T09_24_08.274Z.json (2.9 MB)
没有大查询,非系统查询语句06:55:00-07:05:00这个时间段内看到的慢查询max(Mem_max):335400
目前定位下来,可能是uk的前导列字段的区分度太低了
栗子:
uk(col1,col2,col3)
col1是一个分组字段,col2是一个状态字段,col3是一个用户id字段
区别度来看col3最高,col2最低
sql:
select * from table where col1 in (1001) and col2 in (1,2,3,4) and col3 = 155246852;

