是TiFlash这个阻止了空region合并吗?
是的,这个表太小了,被判为 empty region。而且有 tiflash 的 rule 在,所以没法合并。看上去是正常的情况
这集群多少 tiflash 这种表?监控上的 empty region 有 6k 多都是上面这个情况么?

那和空region 数对应不上,上面那个 default 的 rule 是默认存在的。
可以把 rule 和 empty region 全量 dump 出来看看?
pdctl config placement-rules save
pdctl region check empty-region > region.json
rules.json (1.8 MB) region.json (4.4 MB)
请查看
看了一下, empty 数目应该是合理的。因为 rule 的边界并不是连续的,比如下面 2 条 rule 可能会把 region 切成3个以上空region:
│ │ │ │
│ │ │ │
┌────┼────────┼───────────┼────────┼───────────┐
│ │ │ │ │ │
│r4 │region1 │ region2 │ region3│ r5 │
│ │ │ │ │ │
└────┼────────┼───────────┼────────┼───────────┘
│ │ │ │
│ │ │ │
│ │ │
│ │
rule 1 rule 2
这些没办法合并是么,那它会占用多少空间呢,我通过这个语句看很多空table_id 占用磁盘大量空间
SELECT
db_name,
ROUND(SUM(total_size / cnt), 2) Approximate_Size,
ROUND(SUM(total_size / cnt / (SELECT
ROUND(AVG(value), 2)
FROM
METRICS_SCHEMA.store_size_amplification
WHERE
value > 0)),
2) Disk_Size
FROM
(SELECT
db_name,
table_name,
region_id,
SUM(Approximate_Size) total_size,
COUNT(*) cnt
FROM
information_schema.TIKV_REGION_STATUS
GROUP BY db_name , table_name , region_id) tabinfo
GROUP BY db_name order by Disk_Size desc ;
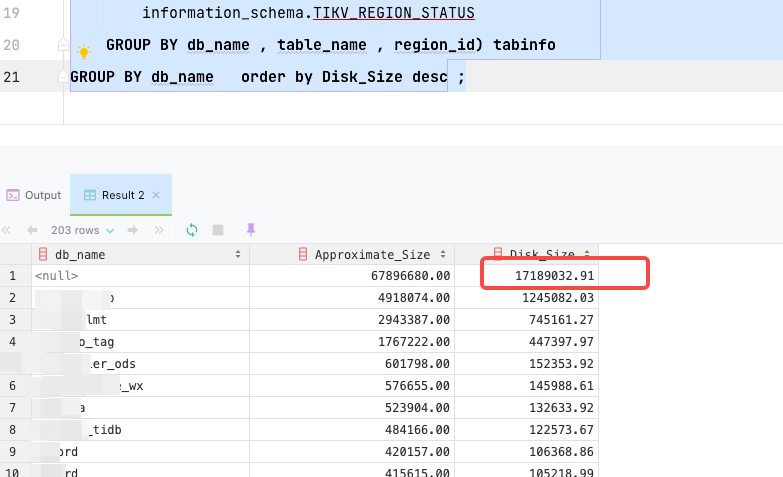
被统计为 empty region 的 Approximate Size 肯定是 1(实际更小,单位是 MB), 所以最多应该是 6k , 你这个又算得有点奇怪
目前不知道这些占用的空间不知道为什么这么大,包括集群的增量数据也比较异常,GC也太忙了。之前的两个帖子麻烦大佬看下是不是都是相关的。
看上去是相关的,5.3.1 有修复.
好的 谢谢,集群太大 升级担心有另外的问题,有其它办法能处理么?
Issue
在 TiKV GC worker CPU 使用率 100% 期间内,执行 drop table 或 truncate table 命令,可能遇到删除表后 TiKV 空间不回收的问题。且 GC worker CPU 下降后,后续执行 drop table 或 truncate table 依然不会回收空间。
Root Cause
TiDB 的 drop table 和 truncate table 命令会发送 unsafe destroy range 请求给 TiKV 删除一个范围的数据。
在 TiKV GC worker 繁忙时,GC worker 的 pending task 数量可能达到上限。此时如果继续向其中添加 unsafe destroy range 任务时,会错误地增加任务数量的计数器但最终没有减小。
多次这样的操作后,该计数器的值会永久性地高于 GC worker 繁忙的阈值。之后所有的 unsafe destroy range 请求都会被 TiKV 拒绝,造成 drop/truncate table 后删除数据不成功。
GitHub issue: https://github.com/tikv/tikv/issues/11903
Diagnostic Steps
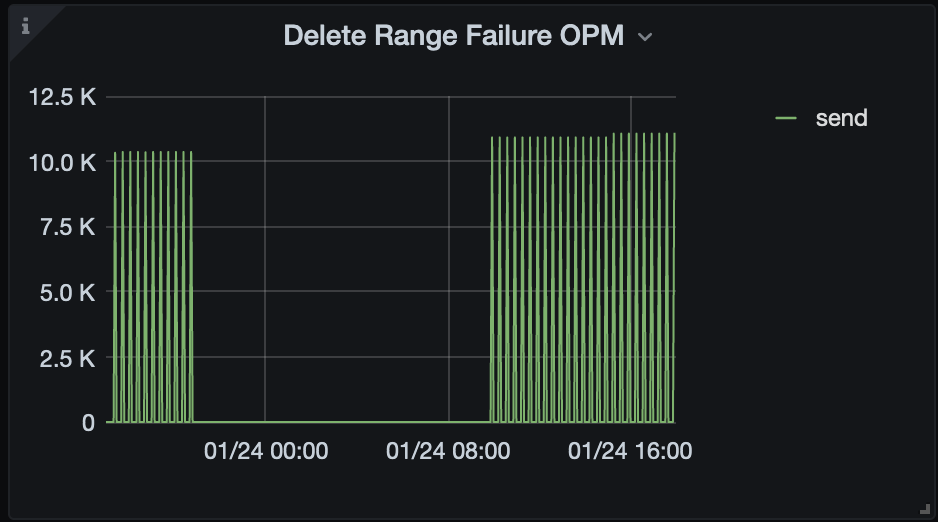
- TiDB 监控的 GC - Delete Range Failure OPM 中有持续的 send 失败,如图:
-
TiDB 日志中确认 Delete Range 错误原因是 “gc worker is too busy”
-
从原理上再次确认,检查 TiKV 曾经出现过 GC worker 持续 CPU 100% 的状况。
Resolution
Bugfix PR: https://github.com/tikv/tikv/pull/11904
修复版本:5.0.7, 5.1.4, 5.3.1, 5.4.0
Workaround
-
如果当前 TiKV GC worker CPU 使用率不高,可以重启 TiKV 实例重置错误的计数器,暂时规避问题。
-
避免在 TiKV GC worker CPU 使用率高的时候执行 drop table/truncate table 操作。

确实监控中失败的很多,上周也重启过一次TiKV,估计也就好了几个小时。
业务上如果不做truncate 操作 那就是delete +insert或者replace操作,我理解会更慢、GC操作会更重了。
有pd的etcd哪些key存了这些值吗?
pd 只存储 gc safepoint,建议短期先对 fail opm 多的 tikv 进行重启,长期升级。升级到 5.0.7 是风险比较小的。

这里咋没看到5.0.7?![]()
还没有发, 5.1.4 是有发的
大概啥时候会发,主要怕升级引入新的bug,还有一些sql不兼容的问题,看过升级方案说准备新集群引流过去验证,但是集群50T 操作起来太麻烦了,也需要耗费大量的时间和经济成本
问了下,还在排期。旧版本的周期要长一些
好的 谢谢~