【 TiDB 使用环境`】测试环境
【 TiDB 版本】
tidb:6.1.0
dm:6.1.0
【遇到的问题】
前几天碰到的问题:dm不同步,但是也不报错。
重新全量同步后同步恢复正常
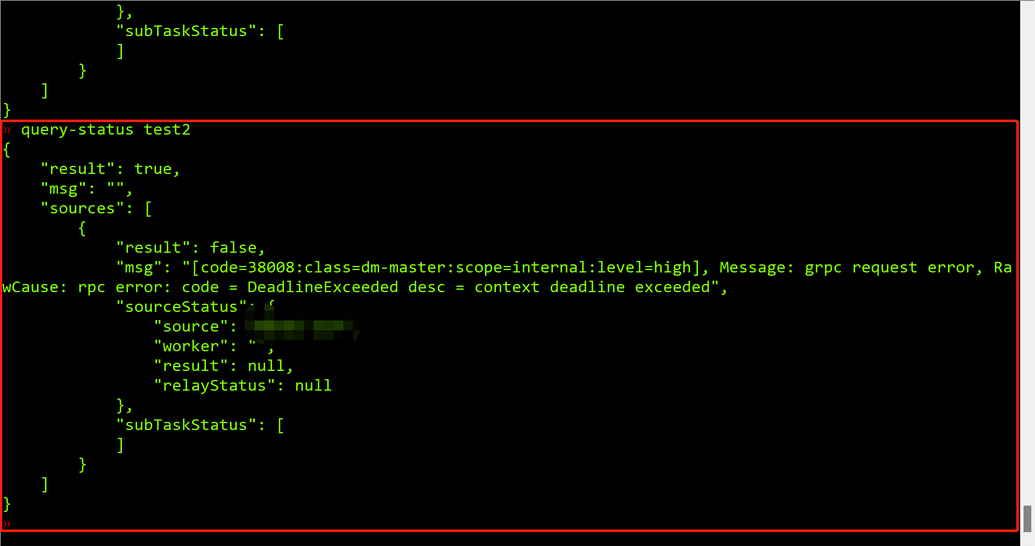
由于是测试环境,tikv部署在一个服务器上,发现内存32G内存只剩下900M,就想着重启一下tikv,结果碰到前几天一样的问题:不同步,但是也不报错。stop-task后就报如下的错误:
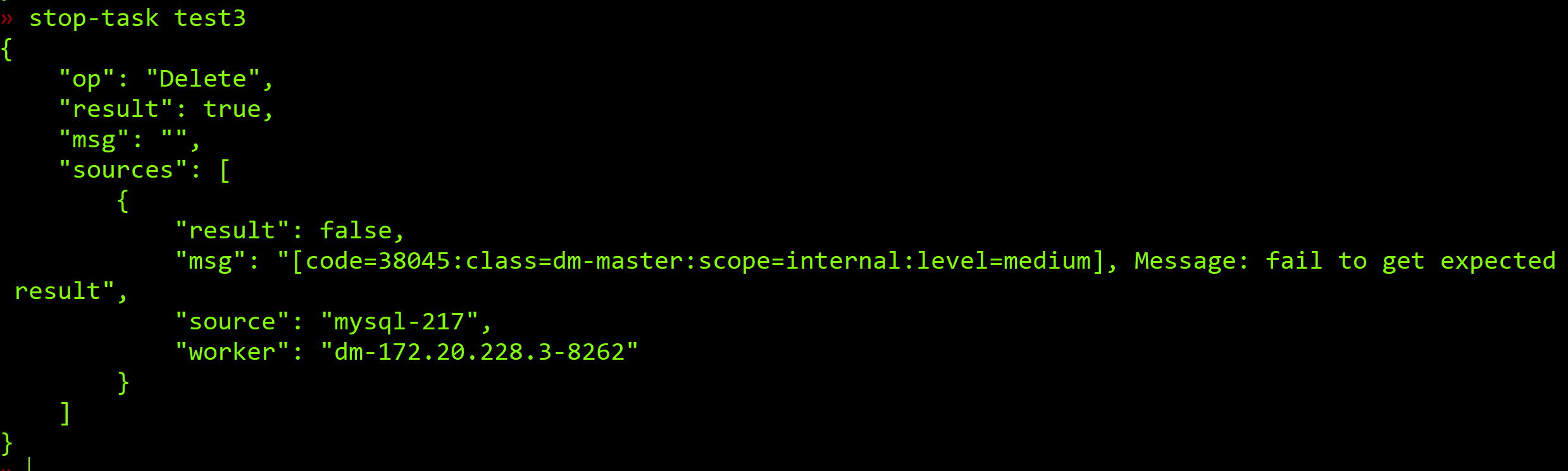
日志里面没有信息吗?
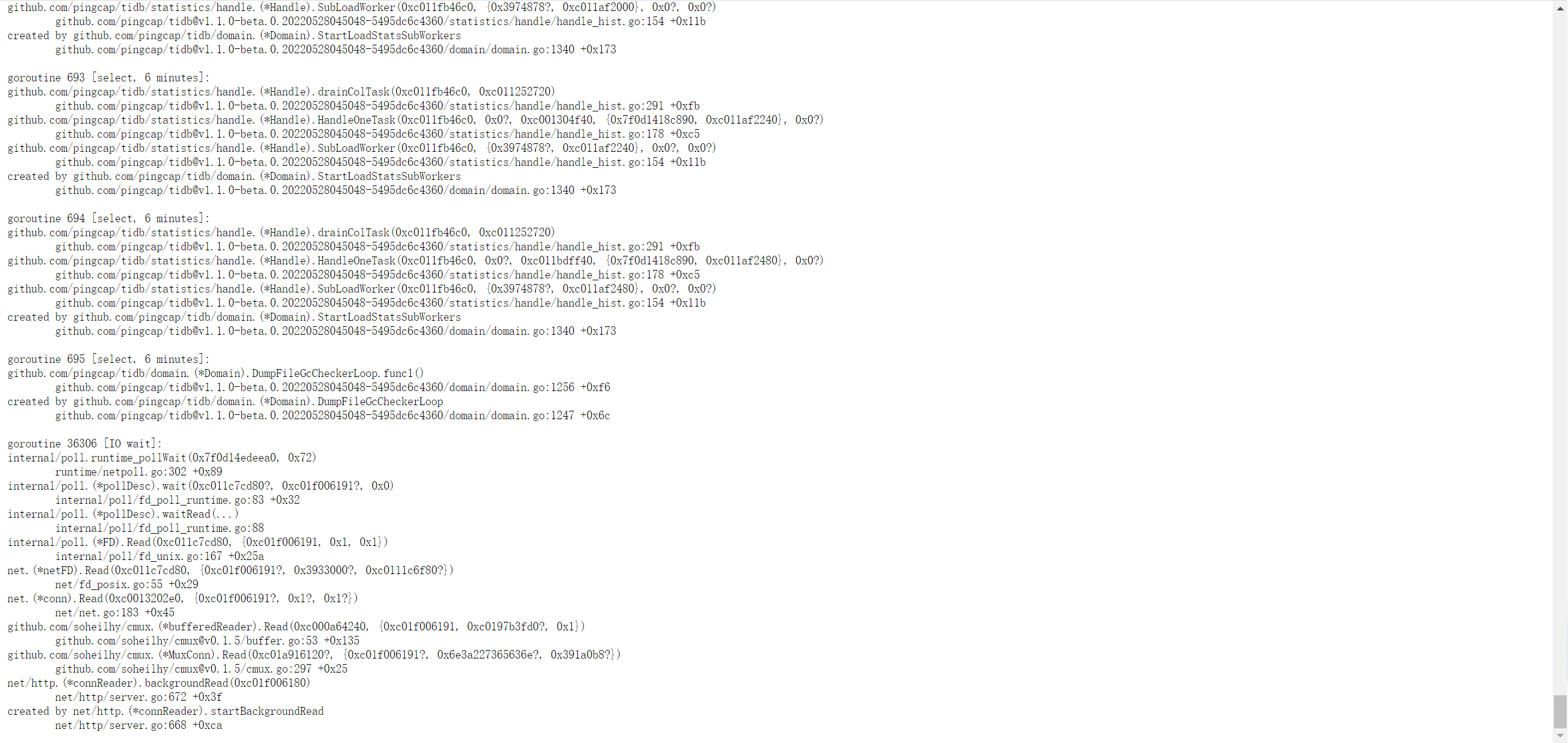
看上去像是这个 DM-worker 卡住了。可以抓一下 goroutine 信息贴出来吗
根据您的截图,应该是 172.20.228.3:8262/debug/pprof/goroutine?debug=2
上传完整的文本文件我们看一下
好的,稍等
我也看不到
感谢反馈,初步来看是 DM-worker 遇到任务报错之后,定时自动恢复任务时,卡在了任务初始化的的一个阶段上。我们稍后在 GitHub 上开一个 issue 记录一下这个问题
您能找一下这个 worker 的 stdout/stderr 日志文件,看看有什么包含 “ddl” 的报错内容吗


大佬,这个问题有解决办法吗?
暂时还没有定位到原因,我们在 https://github.com/pingcap/tiflow/issues/6898 这里跟踪。您可以先试试重启这个 DM-worker
另外您这边出问题的任务,同步的表的数目很多吗
大概有800多个表
目前看 5.4 以及之前版本不会受到这个 bug 影响。
我们尝试本地复现一下

这个是的集群部署情况,一共2台服务器,tikv3个节点中有2个节点在同一台服务器,其他组件节点在另一条服务器(包括dm master和worker),tiflash由于内存紧张就停掉了,操作系统:Ubuntu 18.04.5 LTS (GNU/Linux 4.15.0-128-generic x86_64)。服务器配置:16C/32G
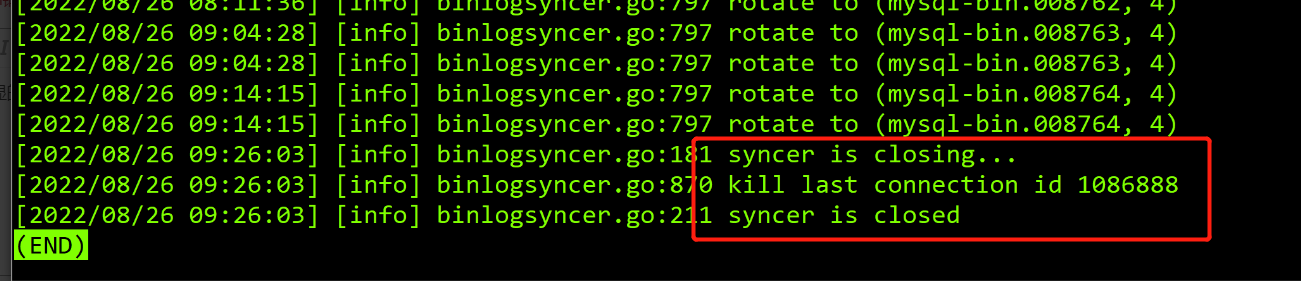
您提供的 goroutine 栈对应的时刻,任务其实已经启动成功了。由于您这个任务包含 800 张表,任务在启动后的初始化阶段可能会等待 80 秒左右,之后应该会正常同步的。如果任务更长时间不推进的话,可能是遇到错误导致任务暂停、自动恢复,又进入了一个 80 秒的等待。这个在日志中应该会有错误信息
对于您说的这个 stop-task、query-status 超时,也是需要在出问题的时候提供 goroutine 栈信息,我们排查一下
稍等,我复现一下,业务暂时迁移走了,准备卸载,安装5.4版本的了
1 个赞