前言:执行了 crd.yaml 和 operator.yaml 后,重建了 crd。正常运行20 小时后,pd 挂掉。
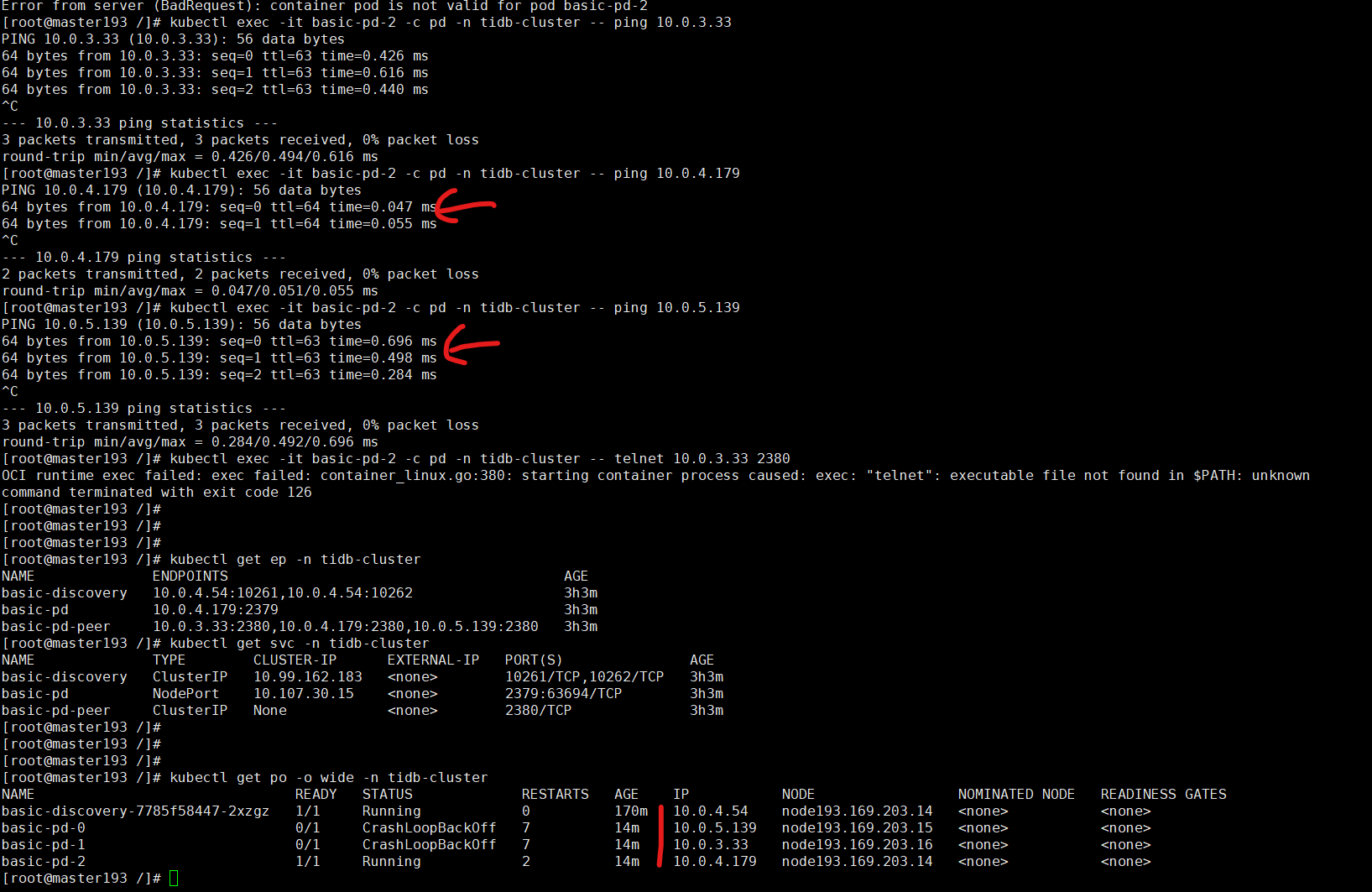
请教:如何定位为什么 pd 间的通信为什么失败 和 解决方案。不要推荐 tiup 和 删掉 operator 再次重建方式,代价太大了,555。 -.-
【 TiDB 使用环境】线上
【 TiDB 版本】v5.2.1
【遇到的问题】
【复现路径】做过哪些操作出现的问题
【问题现象及影响】
2022/08/25 07:20:22.565 +00:00] [WARN] [stream.go:277] ["established TCP streaming connection with remote peer"] [stream-writer-type="stream Message"] [local-member-id=caab82c67f3f4ad1] [remote-peer-id=6b27cfc0d7490063]
[2022/08/25 07:20:22.565 +00:00] [INFO] [stream.go:250] ["set message encoder"] [from=caab82c67f3f4ad1] [to=caab82c67f3f4ad1] [stream-type="stream MsgApp v2"]
[2022/08/25 07:20:22.565 +00:00] [WARN] [stream.go:277] ["established TCP streaming connection with remote peer"] [stream-writer-type="stream MsgApp v2"] [local-member-id=caab82c67f3f4ad1] [remote-peer-id=6b27cfc0d7490063]
2022/08/25 07:20:22.573 log.go:85: [warning] etcdserver: [could not get cluster response from http://basic-pd-1.basic-pd-peer.tidb-cluster.svc:2380: Get "http://basic-pd-1.basic-pd-peer.tidb-cluster.svc:2380/members": dial tcp 10.0.3.16:2380: connect: connection refused]
[2022/08/25 07:20:22.573 +00:00] [ERROR] [etcdutil.go:70] ["failed to get cluster from remote"] [error="[PD:etcd:ErrEtcdGetCluster]could not retrieve cluster information from the given URLs"]
[2022/08/25 07:20:22.767 +00:00] [PANIC] [cluster.go:460] ["failed to update; member unknown"] [cluster-id=d9e392fb342bfa96] [local-member-id=caab82c67f3f4ad1] [unknown-remote-peer-id=2b86c59db64a77fc]
panic: failed to update; member unknown
goroutine 450 [running]:
go.uber.org/zap/zapcore.(*CheckedEntry).Write(0xc000750300, 0xc00067e0c0, 0x3, 0x3)
/nfs/cache/mod/go.uber.org/zap@v1.16.0/zapcore/entry.go:234 +0x58d
go.uber.org/zap.(*Logger).Panic(0xc000276360, 0x2759a56, 0x20, 0xc00067e0c0, 0x3, 0x3)
/nfs/cache/mod/go.uber.org/zap@v1.16.0/logger.go:226 +0x85
go.etcd.io/etcd/etcdserver/api/membership.(*RaftCluster).UpdateAttributes(0xc0006e0070, 0x2b86c59db64a77fc, 0xc005d8e630, 0xa, 0xc005dba940, 0x1, 0x4)
/nfs/cache/mod/go.etcd.io/etcd@v0.5.0-alpha.5.0.20191023171146-3cf2f69b5738/etcdserver/api/membership/cluster.go:460 +0x9d1
go.etcd.io/etcd/etcdserver.(*applierV2store).Put(0xc001c4a540, 0xc005dc2580, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0)
/nfs/cache/mod/go.etcd.io/etcd@v0.5.0-alpha.5.0.20191023171146-3cf2f69b5738/etcdserver/apply_v2.go:89 +0x966
go.etcd.io/etcd/etcdserver.(*EtcdServer).applyV2Request(0xc00017c680, 0xc005dc2580, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0)
/nfs/cache/mod/go.etcd.io/etcd@v0.5.0-alpha.5.0.20191023171146-3cf2f69b5738/etcdserver/apply_v2.go:123 +0x248
go.etcd.io/etcd/etcdserver.(*EtcdServer).applyEntryNormal(0xc00017c680, 0xc0005e14d8)
/nfs/cache/mod/go.etcd.io/etcd@v0.5.0-alpha.5.0.20191023171146-3cf2f69b5738/etcdserver/server.go:2178 +0xad4
go.etcd.io/etcd/etcdserver.(*EtcdServer).apply(0xc00017c680, 0xc004aef8e0, 0x240, 0x252, 0xc0001fc0a0, 0x0, 0xf3d34e, 0xc0005e1640)
/nfs/cache/mod/go.etcd.io/etcd@v0.5.0-alpha.5.0.20191023171146-3cf2f69b5738/etcdserver/server.go:2117 +0x579
go.etcd.io/etcd/etcdserver.(*EtcdServer).applyEntries(0xc00017c680, 0xc0001fc0a0, 0xc001a1e200)
/nfs/cache/mod/go.etcd.io/etcd@v0.5.0-alpha.5.0.20191023171146-3cf2f69b5738/etcdserver/server.go:1369 +0xe5
go.etcd.io/etcd/etcdserver.(*EtcdServer).applyAll(0xc00017c680, 0xc0001fc0a0, 0xc001a1e200)
/nfs/cache/mod/go.etcd.io/etcd@v0.5.0-alpha.5.0.20191023171146-3cf2f69b5738/etcdserver/server.go:1093 +0x88
go.etcd.io/etcd/etcdserver.(*EtcdServer).run.func8(0x30f6530, 0xc001c20040)
/nfs/cache/mod/go.etcd.io/etcd@v0.5.0-alpha.5.0.20191023171146-3cf2f69b5738/etcdserver/server.go:1038 +0x3c
go.etcd.io/etcd/pkg/schedule.(*fifo).run(0xc001c14000)
/nfs/cache/mod/go.etcd.io/etcd@v0.5.0-alpha.5.0.20191023171146-3cf2f69b5738/pkg/schedule/schedule.go:157 +0xf3
created by go.etcd.io/etcd/pkg/schedule.NewFIFOScheduler
/nfs/cache/mod/go.etcd.io/etcd@v0.5.0-alpha.5.0.20191023171146-3cf2f69b5738/pkg/schedule/schedule.go:70 +0x13b
【附件】
请提供各个组件的 version 信息,如 cdc/tikv,可通过执行 cdc version/tikv-server --version 获取。