背景
Tidb 集群部署会自带一套完整的监控体系,给广大tidb粉带来了便利,方便的同时也是存在一些槽点,比如监控组件过多,收集的指标过广,出现性能问题在看监控的时候一时摸不到头脑, 无从下手,意识到这点Tidb 在V6.1.0 也推出了 Performance Overview 面板,抽出了关键指标供我们快速查询,这点还是不错的,但是还有个问题就是多集群 如何实现一起监控,几百上千个实例大屏展示如何实现,领导要统计数据一时半会拿不出咋办呢?定期巡检集群一眼看出端倪?下面主要就是解决上述问题
1
方案一:Prometheus+grafana+consul
1.1 架构图

默认Tidb 安装完成promethes+grafana 已经部署好了,在此不再部署
1 . 2 部署consul
Wget https://releases.hashicorp.com/consul/1.6.1/consul_1.6.1_linux_amd64.zip
unzip consul_1.6.1_linux_amd64.zip && cp consul /sbin/ &&mkdir -p /etc/consul.d/ && mkdir -p /data1/consul/
创建配置文件
cat /etc/consul.d/server.json
{
"datacenter": "bjyt",
"data_dir": "/data1/consul",
"log_level": "INFO",
"node_name": "consul-server",
"server": true,
"bootstrap_expect": 1,
"bind_addr": "xx.xx.xx.xx",
"client_addr": "xx.xx.xx.xx",
"ui":true,
"retry_join": ["xx.xx.xx.xx"],
"retry_interval": "10s",
"enable_debug": false,
"rejoin_after_leave": true,
"start_join": ["xx.xx.xx.xx"],
"enable_syslog": true,
"syslog_facility": "local0"
}
启动consul :
nohup consul agent -config-dir=/etc/consul.d > /data/consul/consul.log &
访问consul web 管理界面
为了增强安全性也可以增加ACL 设置,consul UI token 进行管理,可按照官网进行设置在此略过

1 . 3 服务注册
下面就是如何把tidb exporter信息注册到consul:
首先就是如何获取到tidb exporter 信息,有很多方式都行比如:
第一种 :
curl http://ip:9090/api/v1/targets 获取到tidb 所有的exporter 主机/端口/targets/lables等信息后进行注册
第二种 :
一般tidb 部署的时候相关的元数据信息会存储到数据库表中,我这边也是存储到mysql对应的表中,可以方便的查询出需要的指标进行注册
服务注册:
下面主要是对Tidb/Tikv/Pd 三种角色进行注册,可自定义注册哪些角色并打上tag
Tidb:
curl -X PUT -d '{"id": "tidb-exporter","name": "tidb","address": "xx.xx.xx.xx","port": 10080,"tags": ["tidb","shyc2","product","xx.xx.xx.xx","10080"],"checks": [{"http": "http://xx.xx.xx.xx:10080/metrics", "interval": "5s"}]}' http://xx.xx.xx.xx:8500/v1/agent/service/register
Tikv:
curl -X PUT -d '{"id": "tikv-exporter","name": "tidb","address": "xx.xx.xx.xx","port": 20180,"tags": ["tidb","shyc2","product","xx.xx.xx.xx","20180"],"checks": [{"http": "http://xx.xx.xx.xx:20180/metrics", "interval": "5s"}]}' http://xx.xx.xx.xx:8500/v1/agent/service/register
Pd:
curl -X PUT -d '{"id": "pd-exporter","name": "tidb","address": "xx.xx.xx.xx","port": 2379,"tags": ["tidb","shyc2","product","xx.xx.xx.xx","2379"],"checks": [{"http": "http://xx.xx.xx.xx:2379/metrics", "interval": "5s"}]}' http://xx.xx.xx.xx:8500/v1/agent/service/register
consul web ui界面可以看到是否注册成功
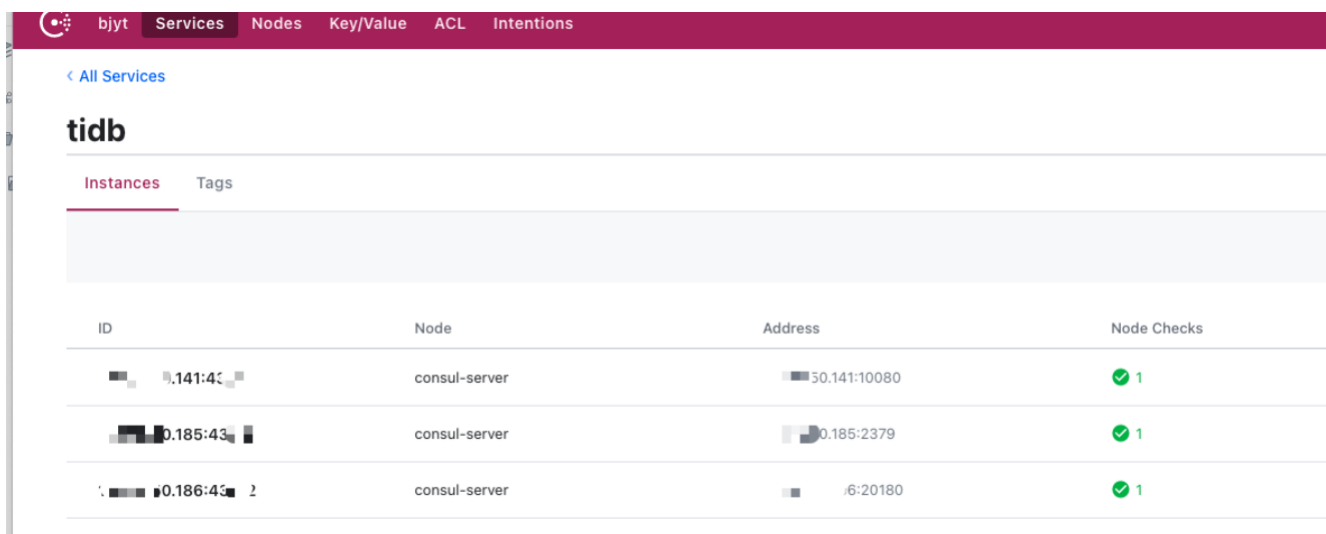
1.4 Prometheus 联动consul :
cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: 'tidb'
consul_sd_configs:
- server: 'xx.xx.xx.xx:8500'
services: ['tidb']
relabel_configs:
- source_labels: ['__meta_consul_tags']
regex: ',(.*),(.*),(.*),(.*),(.*),'
action: replace
target_label: 'instance'
replacement: '${1}_${4}_${5}'
- source_labels: ['__meta_consul_tags']
regex: ',(.*),(.*),(.*),(.*),(.*),'
action: replace
target_label: 'dc'
replacement: '${2}'
- source_labels: ['__meta_consul_tags']
regex: ',(.*),(.*),(.*),(.*),(.*),'
action: replace
target_label: 'env'
replacement: '${3}'
- source_labels: ['__meta_consul_tags']
regex: ',(.*),(.*),(.*),(.*),(.*),'
action: replace
target_label: 'service'
replacement: '${1}'
- source_labels: ['__meta_consul_service_address']
regex: "(.*)"
action: replace
target_label: 'ip'
replacement: '${1}'
- source_labels: ['__meta_consul_tags']
regex: ',(.*),(.*),(.*),(.*),(.*),'
action: replace
target_label: 'port'
replacement: '${5}'
可以灵活根据tags 进行正则匹配替换为自己想要的grafana展示的label
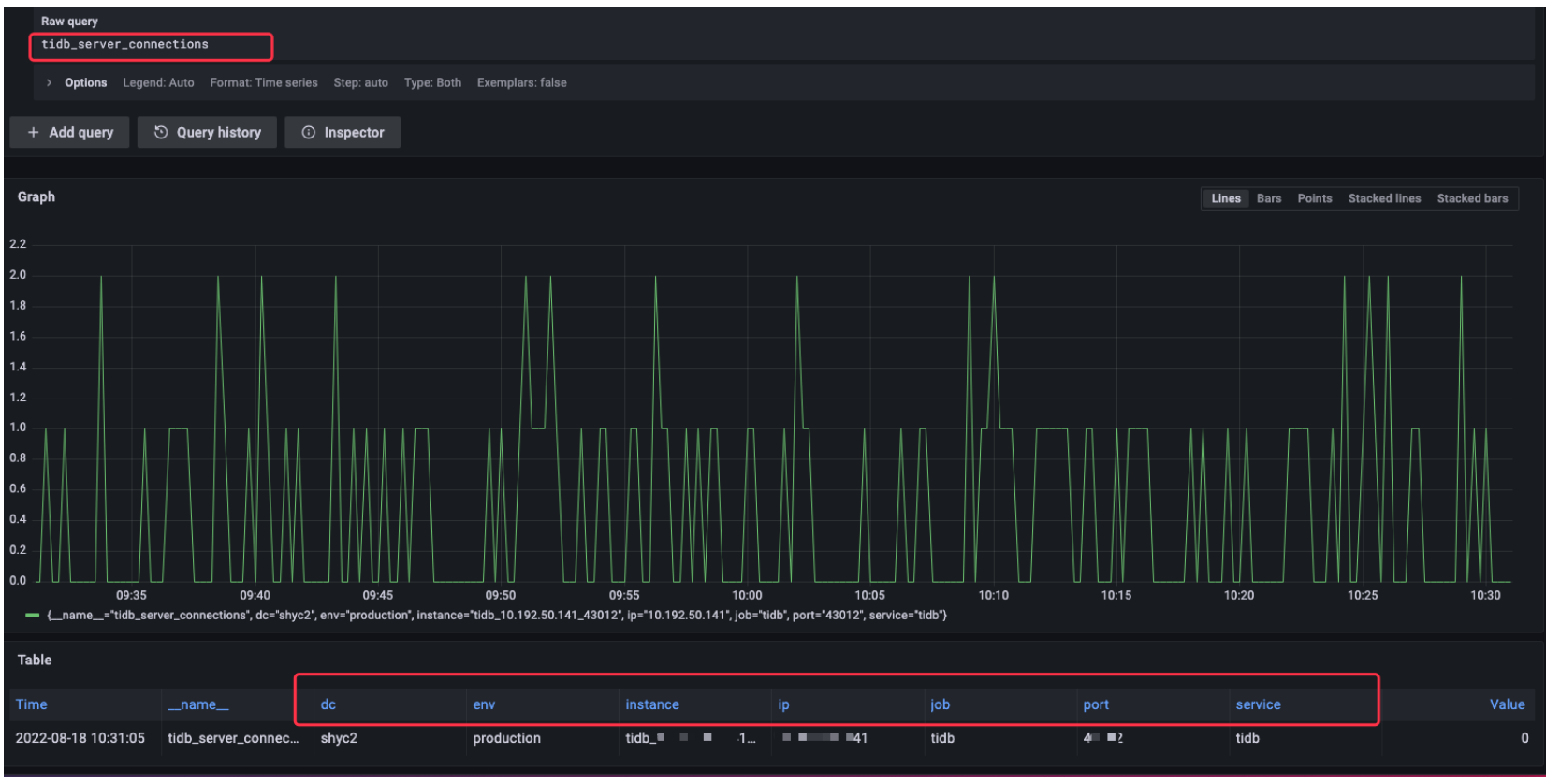
简单配置grafana后,执行tidb 一个监控项比如tidb_server_connections已经可以获取到我们在consul 定制的tag 指标
方案一 适用于数据库实例不是很多的情况下,上述方案完全可支撑,但是我司各种db有上万实例,consul 注册的时候会出现超时的情况,于是采用下面第二种方案
2
方案二: VictoriaMetrics+grafana+api
简单说下思路,主要利用tornado技术编写后端服务发现api,然后put db exporter 指标到api,VM 再通过api get 获取到db 的exporter 信息grafana图形化展示出来
2 . 1 架构图如下 :
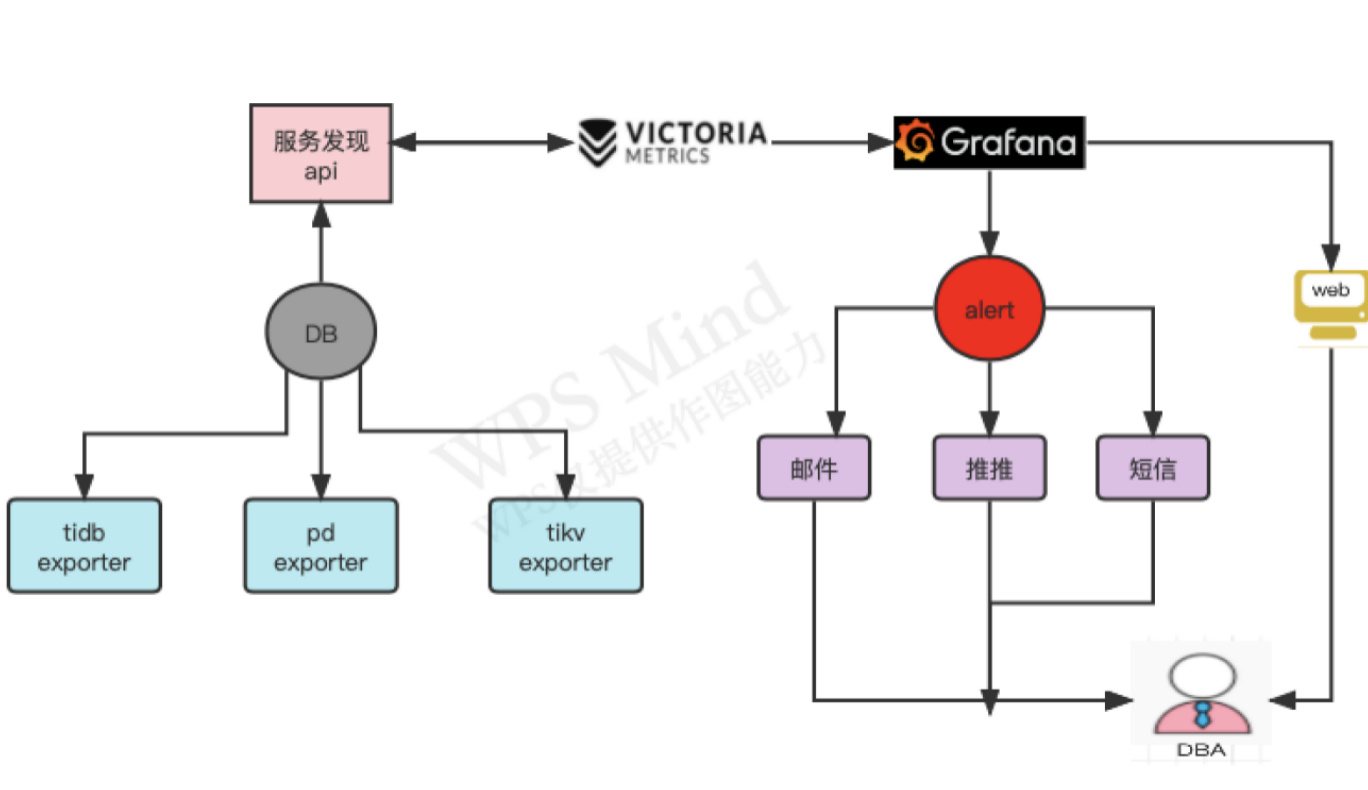
为什么用VM,抛弃了promethes,主要是VM 性能相对更好,内存占用更小
2 . 2 VM vs promethes 性能测试
每组同时并发24个请求,每个请求统计1个小时内的,磁盘使用率和MySQL OPS的Top10。
然后每组请求3次,求平均值。
总数据量:1.3万亿
活跃time series:1100万
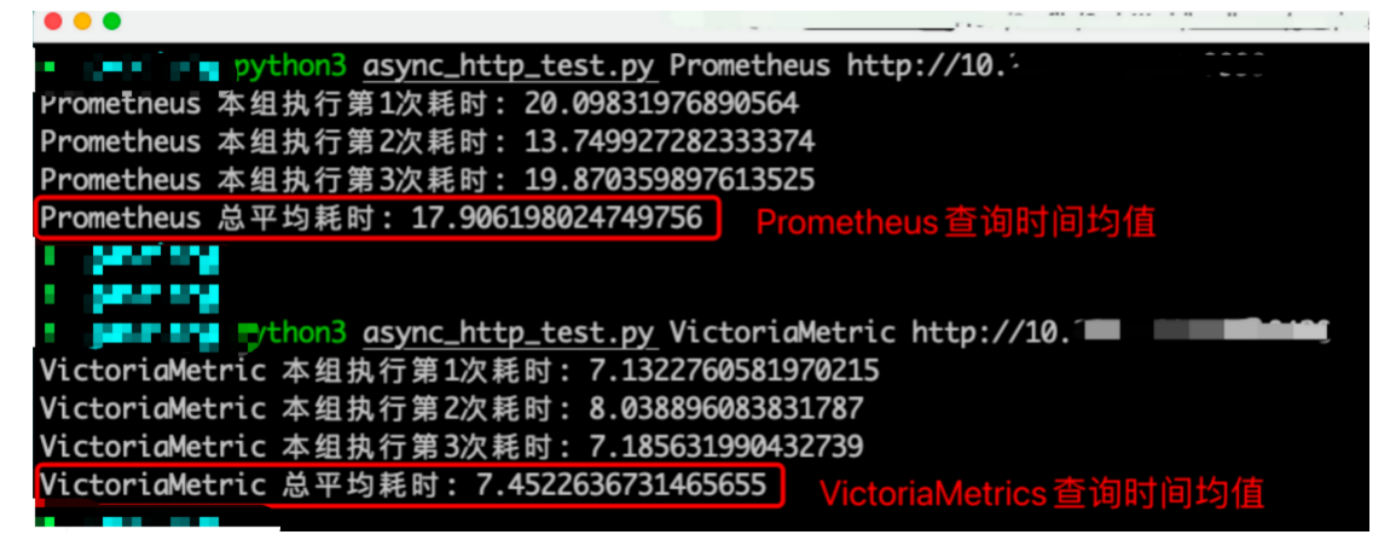
如下截图为执行完上面的查询命令后,
查看VictoriaMetrics和Prometheus两个进程的内存占用情况

可看到vm 内存占用相对真的小很多,线上有个超大Tidb集群即时TB 存储量,Prometheus 内存占用一直接近系统内存,因此用VictoriaMetrics 替换了Prometheus 采集监控数据后效果非常显著,下面介绍下如何使用VM替换Prometheus ,这里简单介绍下单机版操作方式,集群版相对复杂点,可参考官网部署
2 . 3 VM 部署
mkdir victoria-metrics && tar -xvzf victoria-metrics-amd64-v1.65.0.tar.gz && \
mv victoria-metrics-prod victoria-metrics/victoria-metrics
编辑配置文件
cat /etc/systemd/system/victoria-metrics-prod.service
[Unit]
Description=For Victoria-metrics-prod Service
After=network.target
[Service]
ExecStart=/usr/local/bin/victoria-metrics-prod -promscrape.config=/data1/tidb/deploy/conf/prometheus.yml -httpListenAddr=0.0.0.0:8428 -promscrape.config.strictParse=false -storageDataPath=/data1/victoria -retentionPeriod=3
[Install]
WantedBy=multi-user.target
启动vm服务:
systemctl restart victoria-metrics-prod.service
2 . 4 VM 联动grafana
修改grafana:
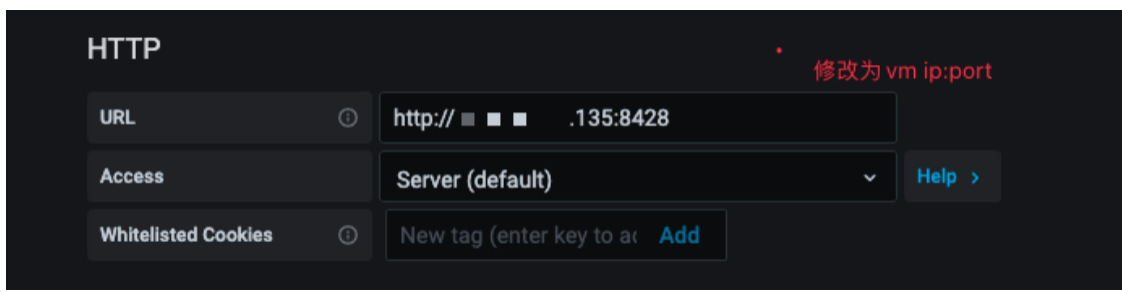
Api 编写忽略,服务注册方式如下:
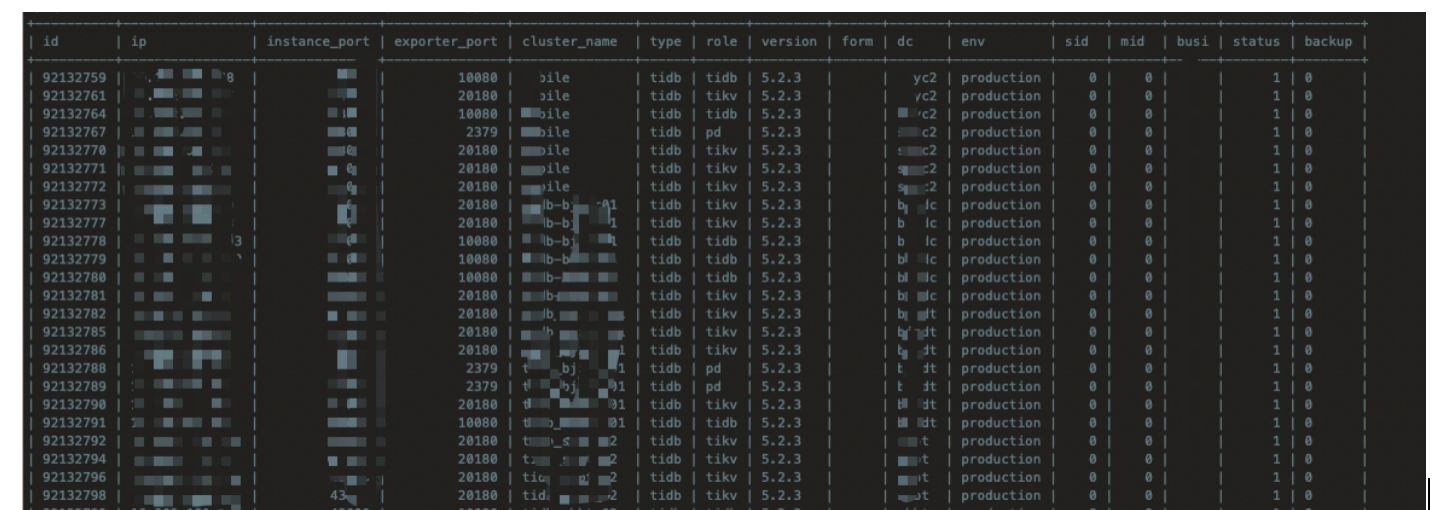
curl -sS --connect-timeout 10 -m 20 --retry 3 --retry-max-time 30 -H 'Content-Type: application/json' -XPUT -d '{"ip": "'${LOCAL_LISTEN_IP}'","instance_port": "'${DB_LISTEN_PORT}'","exporter_port": "'${LOCAL_LISTEN_PORT}'","role":"'${ROLE}'","token":"'${TOKEN}'"}'http://127.0.0.1:8888/tidb/${SERVICE_TYPE}
执行完上述命令后,会在mysql 数据库表中插入tidb注册数据:
Grafana 具体监控项目可参考tidb v6.1.0起推出的performance_overview.json,即使版本低于6,也可以直接倒入这个json使用,个别监控项可以针对性调整下

最终Tidb 集群合并监控如下:具体监控指标可自定义基本参考6.1 推出的performance_overview.json即可

总结:
本文主要分享了tidb 多集群监控整合的两种方案,方案还有很多,比如prometheus集群联邦机制等,选择一个适合自己的即可,主要目的是为了更方便巡检统计线上所有集群的重要监控指标,可以通过大屏的方式可视化出来,有无性能问题一览无余~