【 TiDB 使用环境】线上
【 TiDB 版本】v5.2.2
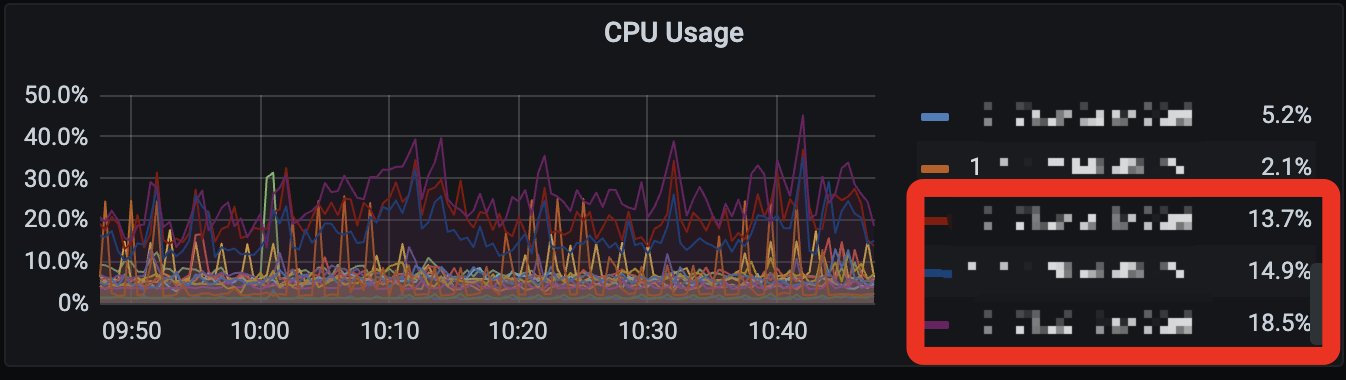
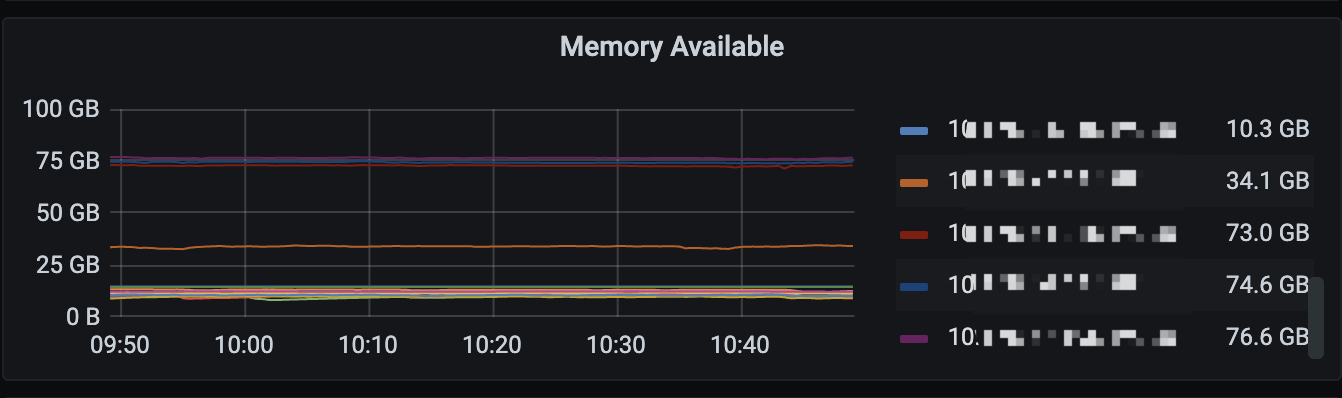
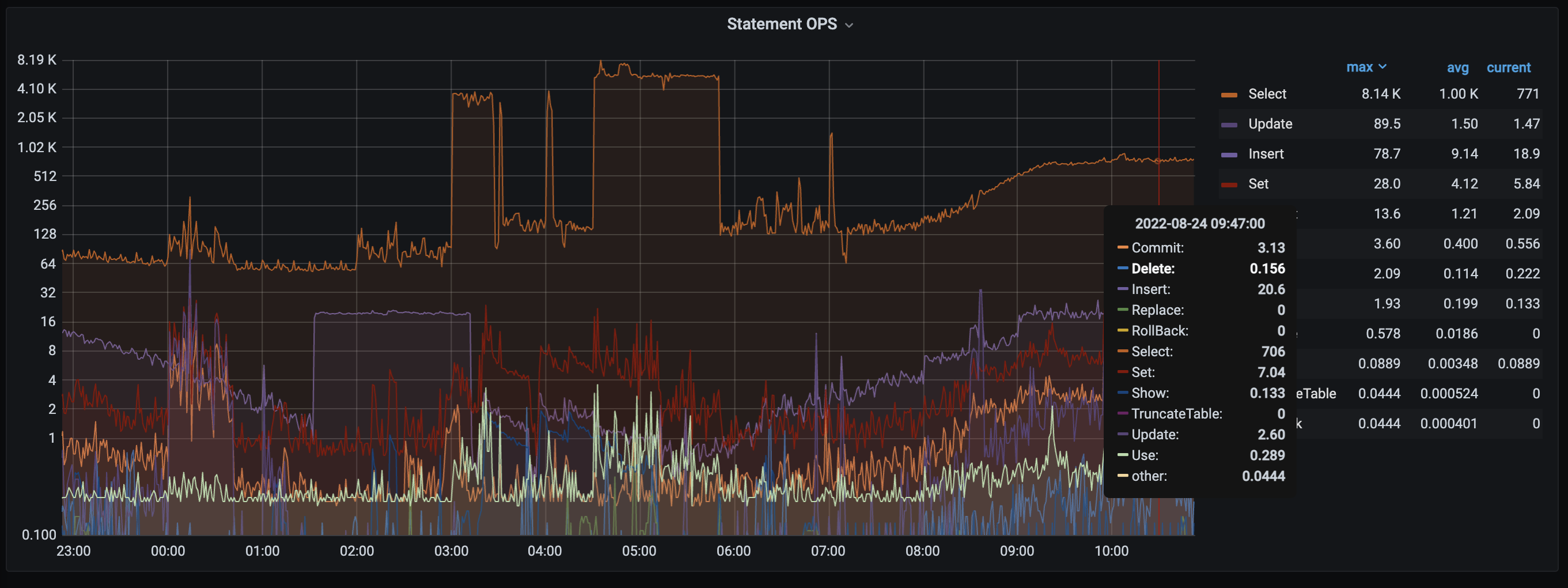
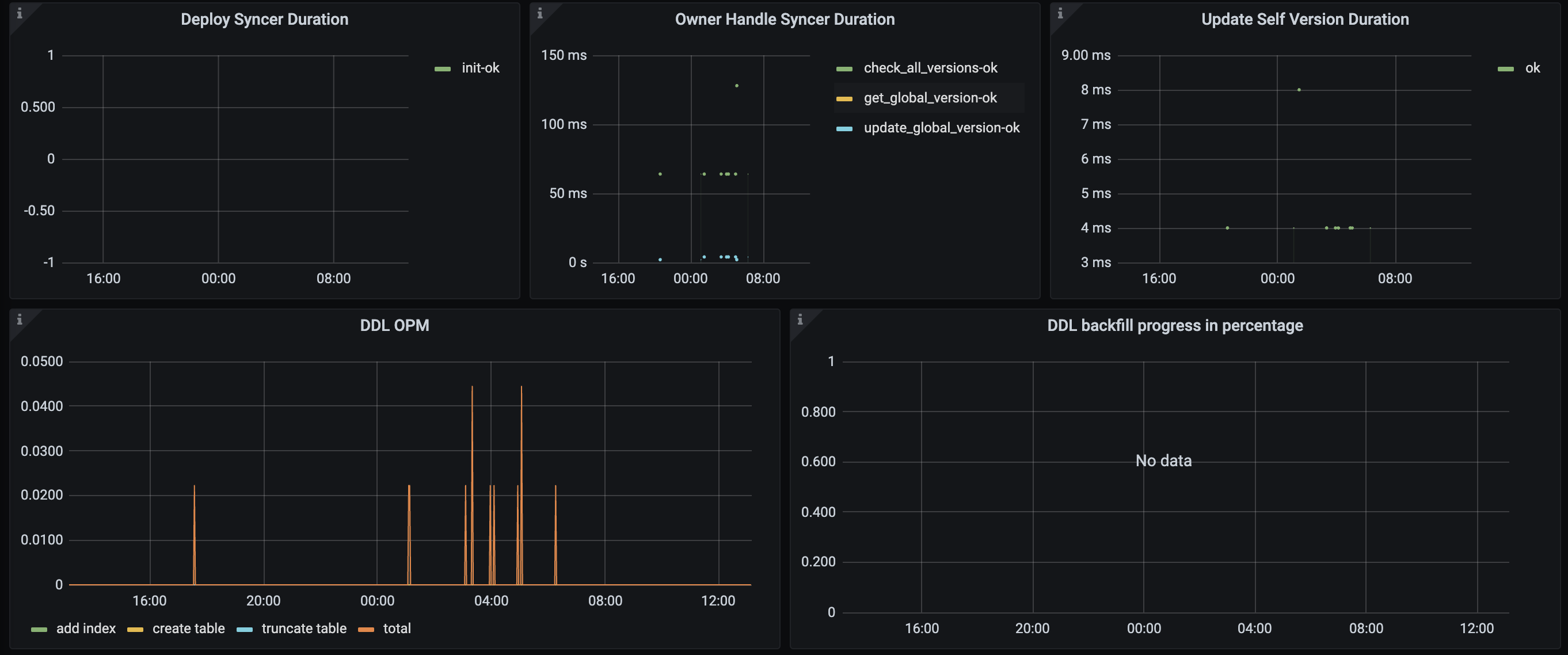
【遇到的问题】900w表添加索引超过一天还没执行完, 执行admin show ddl jobs, ROW_COUNT到了一定值后很长时间都不变化了,根据ddl关键词过滤tidb.log如下
[2022/08/24 09:07:20.332 +08:00] [INFO] [reorg.go:284] ["[ddl] run reorg job wait timeout"] [waitTime=5s] [elementType=idx] [elementID=11] [totalAddedRowCount=3966492] [doneKey=1168558586.next] []
[2022/08/24 09:07:20.336 +08:00] [INFO] [ddl_worker.go:886] ["[ddl] schema version doesn’t change"] [worker=“worker 2, tp add index”]
[2022/08/24 09:07:20.337 +08:00] [INFO] [ddl_worker.go:727] ["[ddl] run DDL job"] [worker=“worker 2, tp add index”] [job=“ID:5160, Type:add index, State:running, SchemaState:write reorganization, SchemaID:53, TableID:216, RowCount:3966492, ArgLen:0, start time: 2022-08-23 20:34:43.531 +0800 CST, Err:, ErrCount:0, SnapshotVersion:435488839088472086”]
[2022/08/24 09:07:25.401 +08:00] [INFO] [reorg.go:284] ["[ddl] run reorg job wait timeout"] [waitTime=5s] [elementType=idx] [elementID=11] [totalAddedRowCount=3966492] [doneKey=1168558586.next] []
[2022/08/24 09:07:25.404 +08:00] [INFO] [ddl_worker.go:886] ["[ddl] schema version doesn’t change"] [worker=“worker 2, tp add index”]
[2022/08/24 09:07:25.405 +08:00] [INFO] [ddl_worker.go:727] ["[ddl] run DDL job"] [worker=“worker 2, tp add index”] [job=“ID:5160, Type:add index, State:running, SchemaState:write reorganization, SchemaID:53, TableID:216, RowCount:3966492, ArgLen:0, start time: 2022-08-23 20:34:43.531 +0800 CST, Err:, ErrCount:0, SnapshotVersion:435488839088472086”]
[2022/08/24 09:07:30.429 +08:00] [INFO] [reorg.go:284] ["[ddl] run reorg job wait timeout"] [waitTime=5s] [elementType=idx] [elementID=11] [totalAddedRowCount=3966492] [doneKey=1168558586.next] []
[2022/08/24 09:07:30.432 +08:00] [INFO] [ddl_worker.go:886] ["[ddl] schema version doesn’t change"] [worker=“worker 2, tp add index”]
[2022/08/24 09:07:30.436 +08:00] [INFO] [ddl_worker.go:727] ["[ddl] run DDL job"] [worker=“worker 2, tp add index”] [job=“ID:5160, Type:add index, State:running, SchemaState:write reorganization, SchemaID:53, TableID:216, RowCount:3966492, ArgLen:0, start time: 2022-08-23 20:34:43.531 +0800 CST, Err:, ErrCount:0, SnapshotVersion:435488839088472086”]
[2022/08/24 09:07:35.467 +08:00] [INFO] [reorg.go:284] ["[ddl] run reorg job wait timeout"] [waitTime=5s] [elementType=idx] [elementID=11] [totalAddedRowCount=3966492] [doneKey=1168558586.next] []
[2022/08/24 09:07:35.470 +08:00] [INFO] [ddl_worker.go:886] ["[ddl] schema version doesn’t change"] [worker=“worker 2, tp add index”]
[2022/08/24 09:07:35.471 +08:00] [INFO] [ddl_worker.go:727] ["[ddl] run DDL job"] [worker=“worker 2, tp add index”] [job=“ID:5160, Type:add index, State:running, SchemaState:write reorganization, SchemaID:53, TableID:216, RowCount:3966492, ArgLen:0, start time: 2022-08-23 20:34:43.531 +0800 CST, Err:, ErrCount:0, SnapshotVersion:435488839088472086”]
【复现路径】执行admin cancel ddl jobs jobid,重新执行添加索引还是上面的现象。
请问如何排查ddl卡在哪个阶段?以及如何解决?