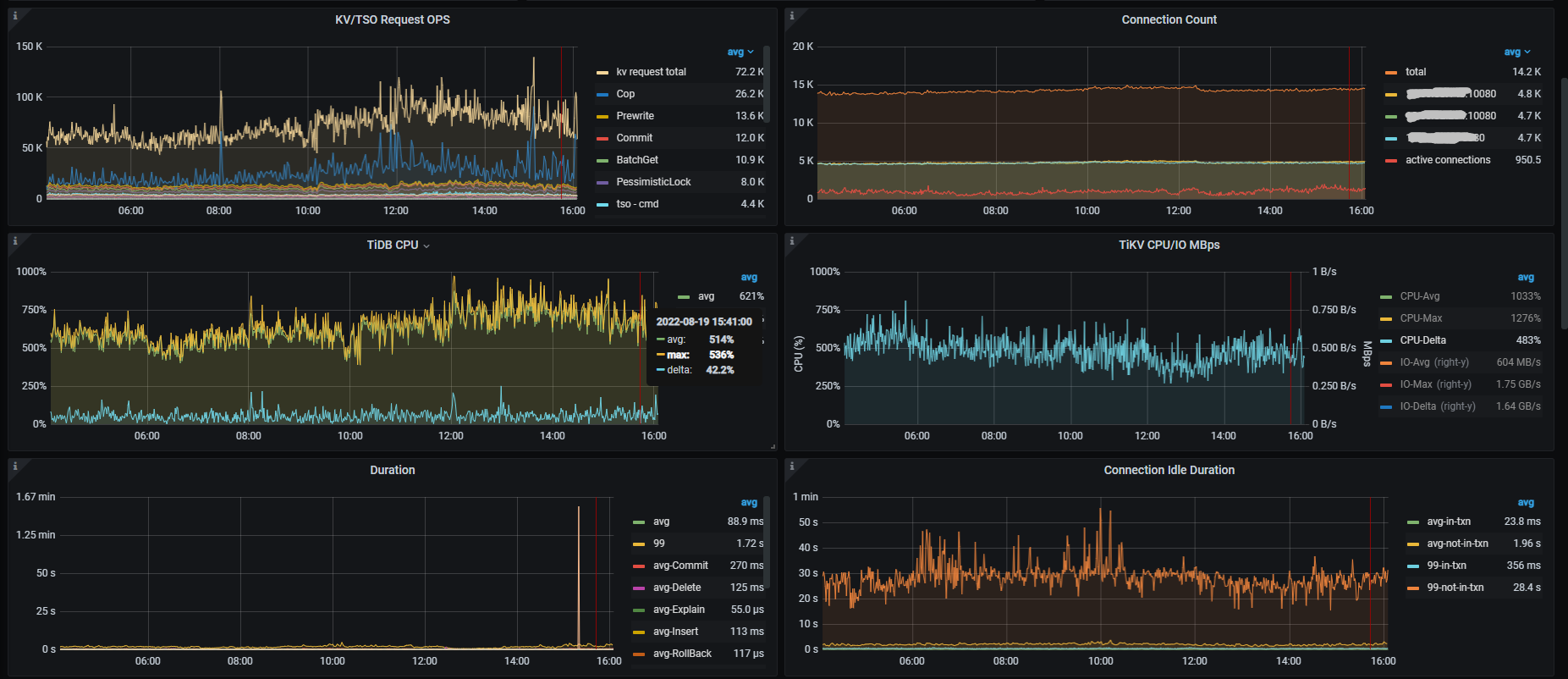
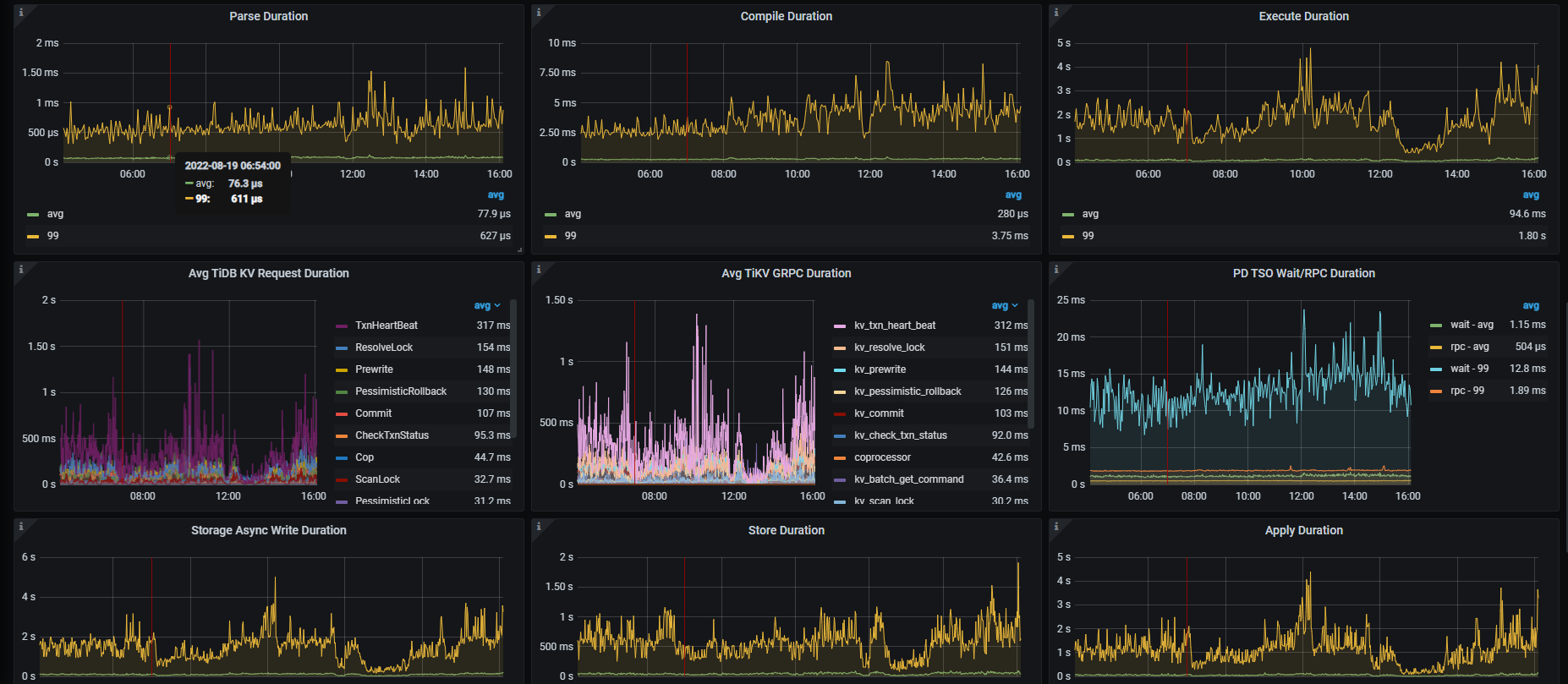
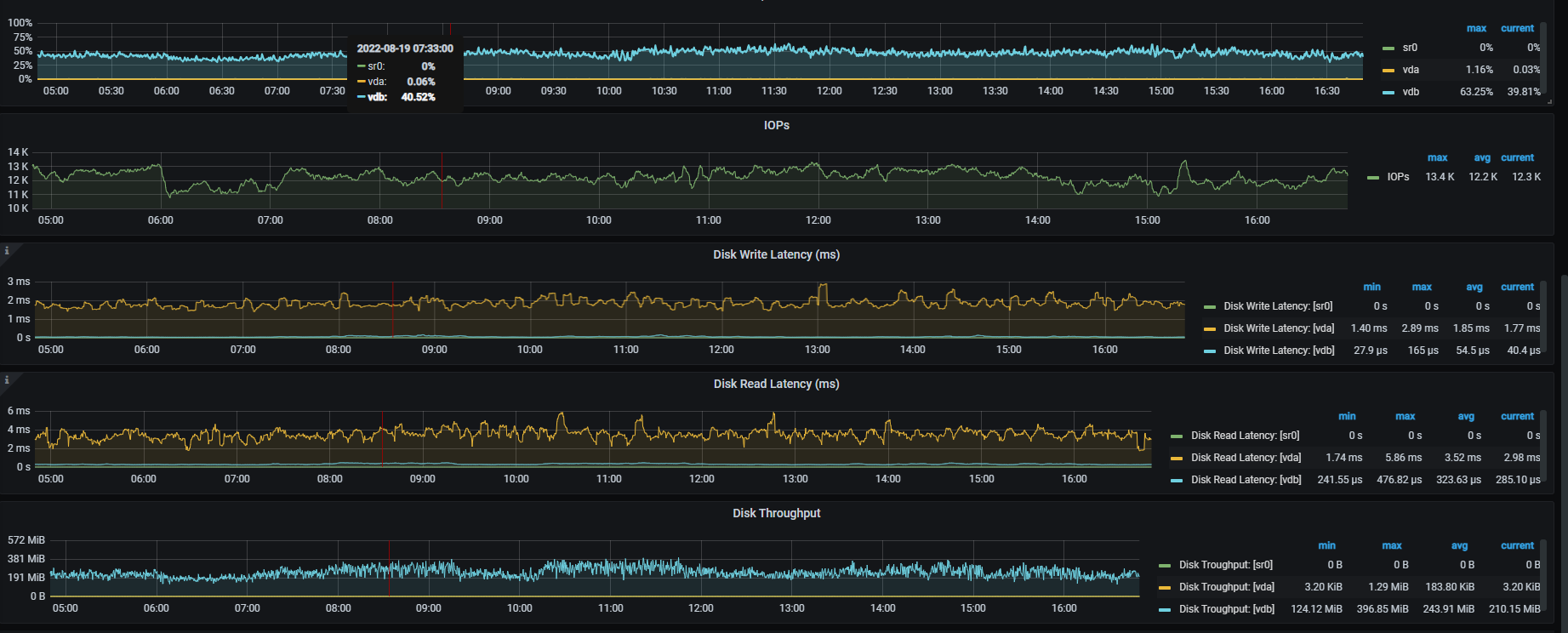
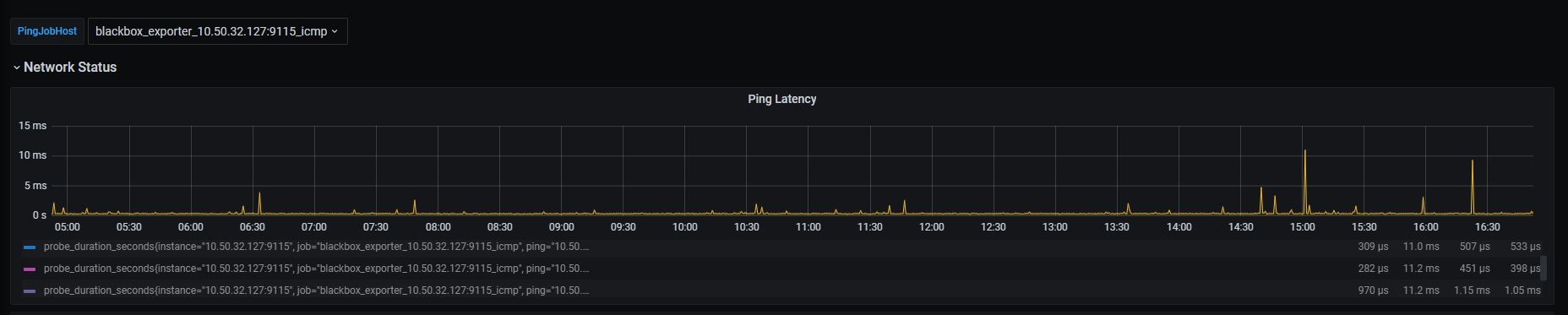
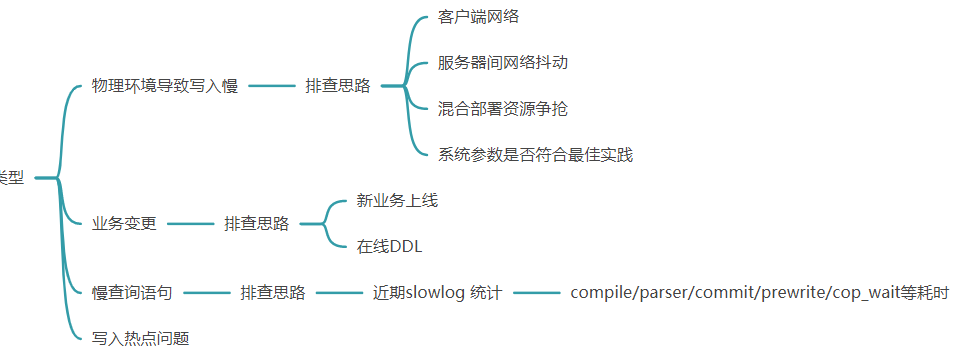
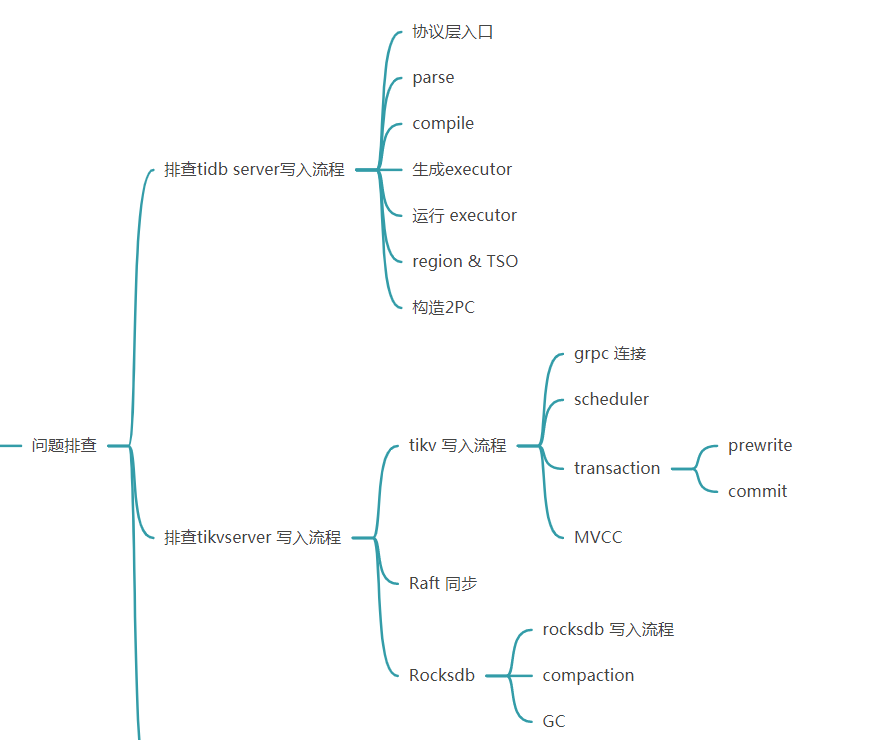
【概述】 场景 + 问题概述
tidb 并发写入的时候,
insert 语句几乎都在 8-10s 内完成
业务 insert 并发100个左右
【问题】 当前遇到的问题
insert 写入非常耗时
sql语句如下 每次批量拼接300条数据
INSERT INTO
xxxx_ods_latest (
marketplace_id,
asin,
item_md5,
res_json,
request_timestamp
)
VALUES
(…),
(…),
(…),
(…) ON DUPLICATE KEY
UPDATE
item_md5 = IF (
xxxx_ods_latest.item_md5 !=
VALUES
(item_md5),
VALUES
(item_md5),
xxxx_ods_latest.item_md5
),
res_json =
VALUES
(res_json),
request_timestamp =
VALUES
(request_timestamp);
【业务影响】
kafka消费不完,数据有延迟。
【TiDB 版本】
V5.4.0
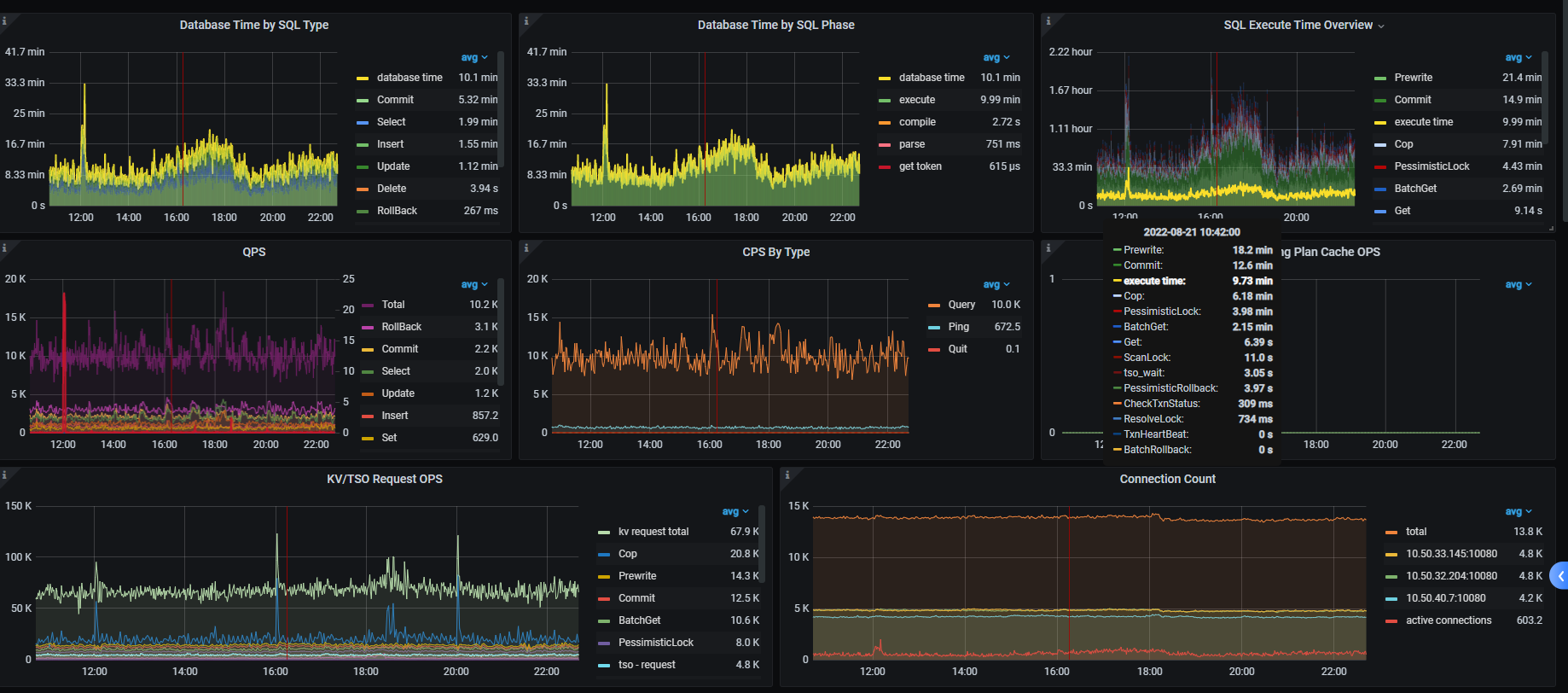
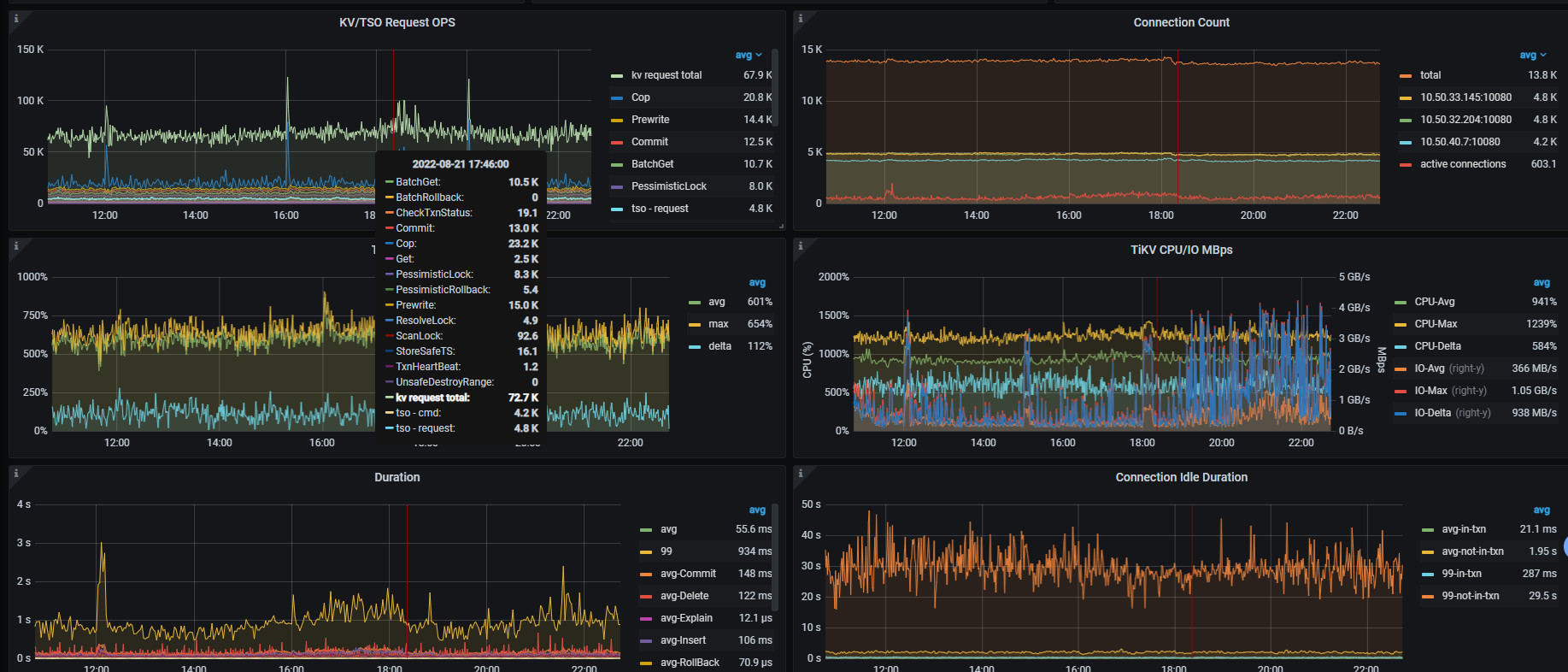
【附件】 相关日志及监控(
https://metricstool.pingcap.com/)
h5n1
(H5n1)
2
看着像网络有延迟,看下node _exporter , black_exporter监控。磁盘IO情况也看下
h5n1
(H5n1)
4
https://metricstool.pingcap.com/#backup-with-dev-tools 按这个把overview 、tidb、tikv detail、PD 监控问题时段导出下,要等待所有面板全部展开后再导出
h5n1
(H5n1)
13
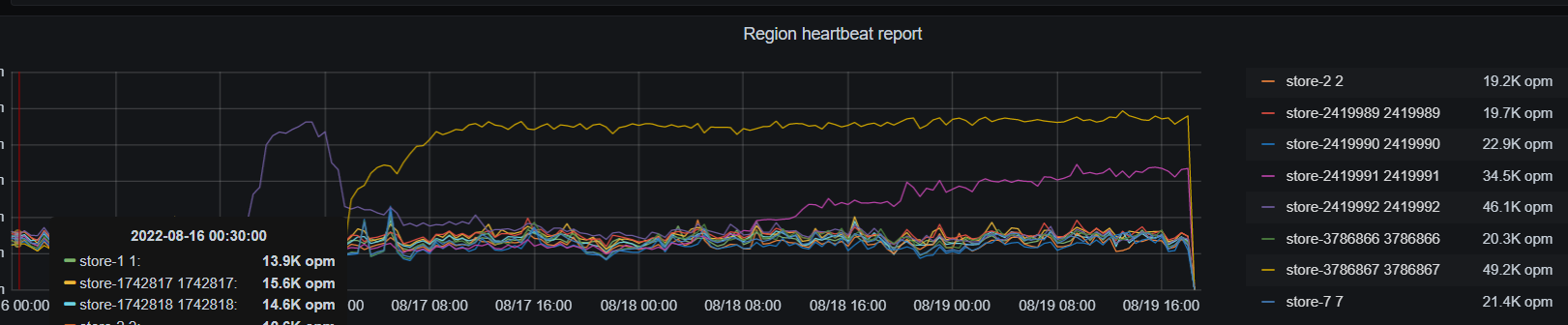
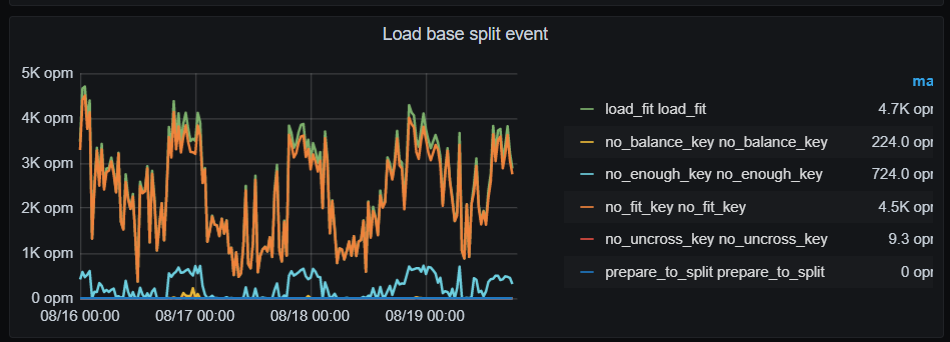
导出的有些面板没有数据,部分Tikv节点上增加了很多region,CPU利用率较高。 split.qps-thresholdsplit.byte-threshold 这2个参数值是多少? 每个tikv的磁盘空间是一样的吗,有没有设置region_weight ,leader weight?
split.qps-threshold = 3000
split.byte-threshold = 31457280
没有设置 region_weight ,leader weight
h5n1
(H5n1)
15
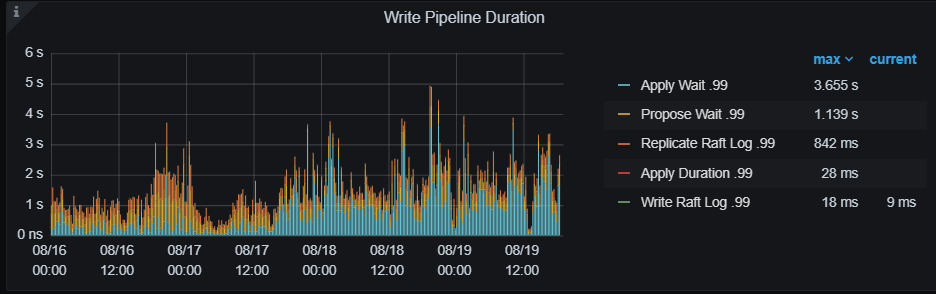
现在写入性能正常了吗, 前面2个截图监控目前什么状态
指标有下降,昨天加大了scheduler-worker-pool-size 和 storage.block-cache.capacity
看下 raftstore.store-pool-size,raftstore.apply-pool-size 的设置, 这辆尽量一致,前者是生产者的能力 后者是消费的能量 , 如果前面的值比后面的 值大很多的话, 会影响写入速度
3 个赞
如果你的机器资源较高的话 可以适当调高这2个参数 , 增大生产和消费能力
qizheng
(qizheng)
22
写入主要是 raftstore 线程 propoase/apply wait 长尾延迟高,可以按楼上建议的,根据当前 cpu 和 io 资源情况,先调大这两个线程池