hyman
1
【 TiDB 使用环境】生产 【 TiDB 版本】5.4 【数据体量】800G TIDB 3台6核256G内存 4台KV同上配置 【复现路径】通过使用lightning进行数据恢复一直卡到如下日志地方
【问题现象及影响】
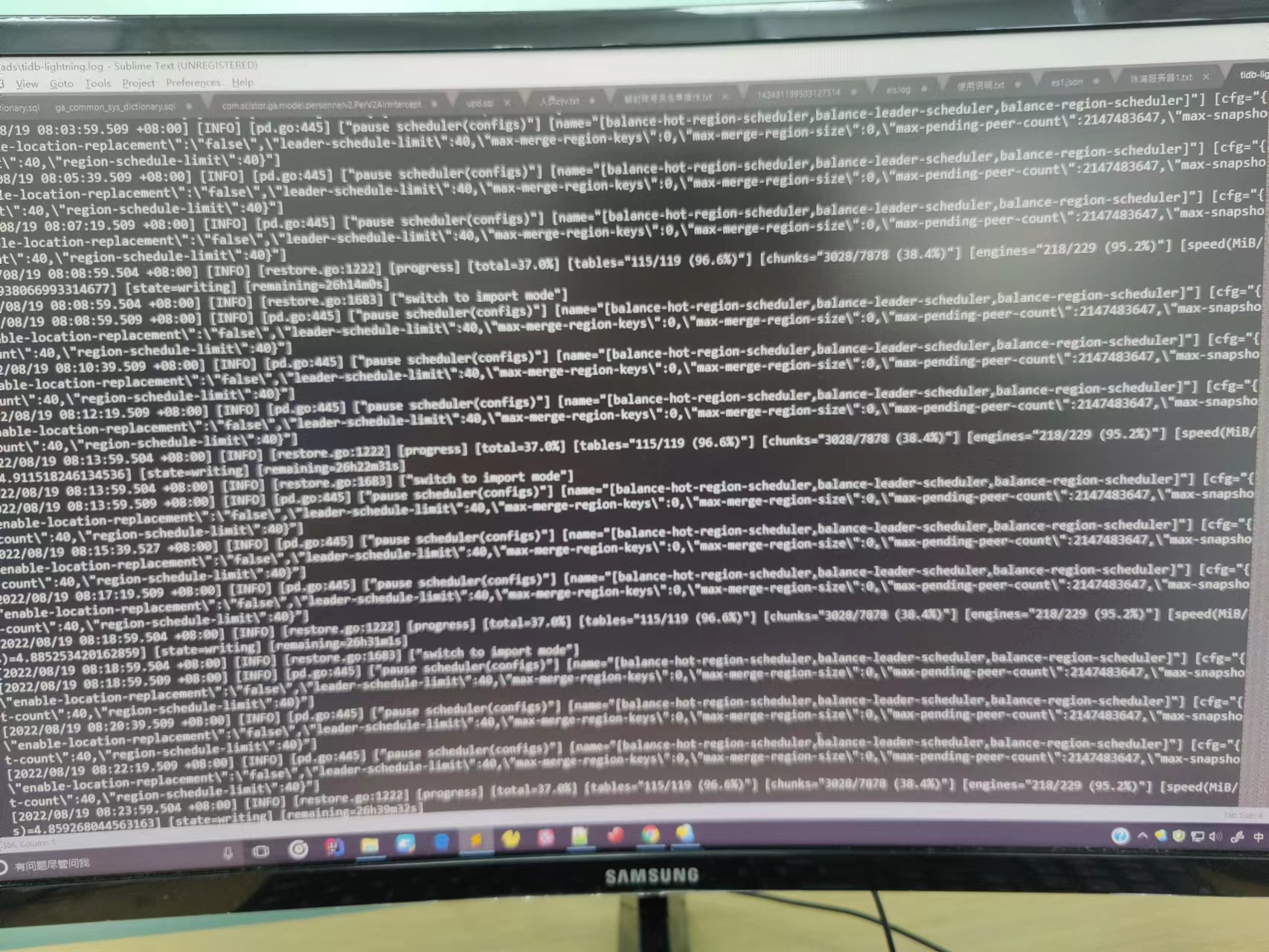
[INFO] [pd.go:406] [“pause scheduler(configs)”] [name=“[balance-region-scheduler,balance-leader-scheduler,balance-hot-region-scheduler]”] [cfg=“{"enable-location-replacement":"false","leader-schedule-limit":40,"max-merge-region-keys":0,"max-merge-region-size":0,"max-pending-peer-count":2147483647,"max-snapshot-count":40,"region-schedule-limit":40}”]
wink
(winkyao)
2
我看还是有 progress 的进度,为何说卡住呢?
hyman
3
因为一直再这个日志卡了24小时了总量数据就800G
wink
(winkyao)
4
lightning卡在99%,一直不动 麻烦按这个回答的操作,试试看抓一下 lightning 的 go routine, 看看卡在哪里?
hyman
7
800G数据重新跑了一天卡住然后重新启动的lightning也是卡住
1 个赞
hyman
9
lightning部署的是6核256G的单独服务器上面,已经导入成功了300G的库和100G的库几个库,现在导入的是800G的最大的一个库,现在能看出来是因为性能瓶颈导致的吗?
hyman
10
重新删除了数据库和断电文件重新启动lightning 依然卡住,日志如下goroutine (1).log (335.2 KB) tidb-lightning.log.1 (299.5 KB)
hyman
12
监控这块暂时无法看到,这个是内部限制问题,暂时只能通过系统指令查看 导入机 CPU是一直100% ,之前已经导入成功过一个300G的表耗时3小时,这个800G的耗时16小时了已经卡了十几个小时了
hyman
14
当前tidb-lightning.toml只配置了断点续传 index-concurrency = 1 table-concurrency =1 region-concurrency = 5 其他都是默认标准配置
hyman
15
还有一个问题,现在是卡住了,如果是因为机器性能的问题什么样的场景会卡在一个地方10多个小时,这个配置毕竟是已经导入成功过几个 300G的库,还有没有其他方式能查看卡在哪里了
Ming
16
[progress] [total=34.8%] [tables=“114/119 (95.8%)”] [chunks=“2906/7883 (36.9%)”] [engines=“216/229 (94.3%)”] [speed(MiB/s)=9.852305238553472] [state=writing] [remaining=13h54m21s]
[2022/08/25 01:17:43.309 +08:00] [INFO] [restore.go:1683] [“switch to import mode”]
这个正常后面都是提示switch to import mode吗,我咋感觉正常后面不是这个呢
1 个赞
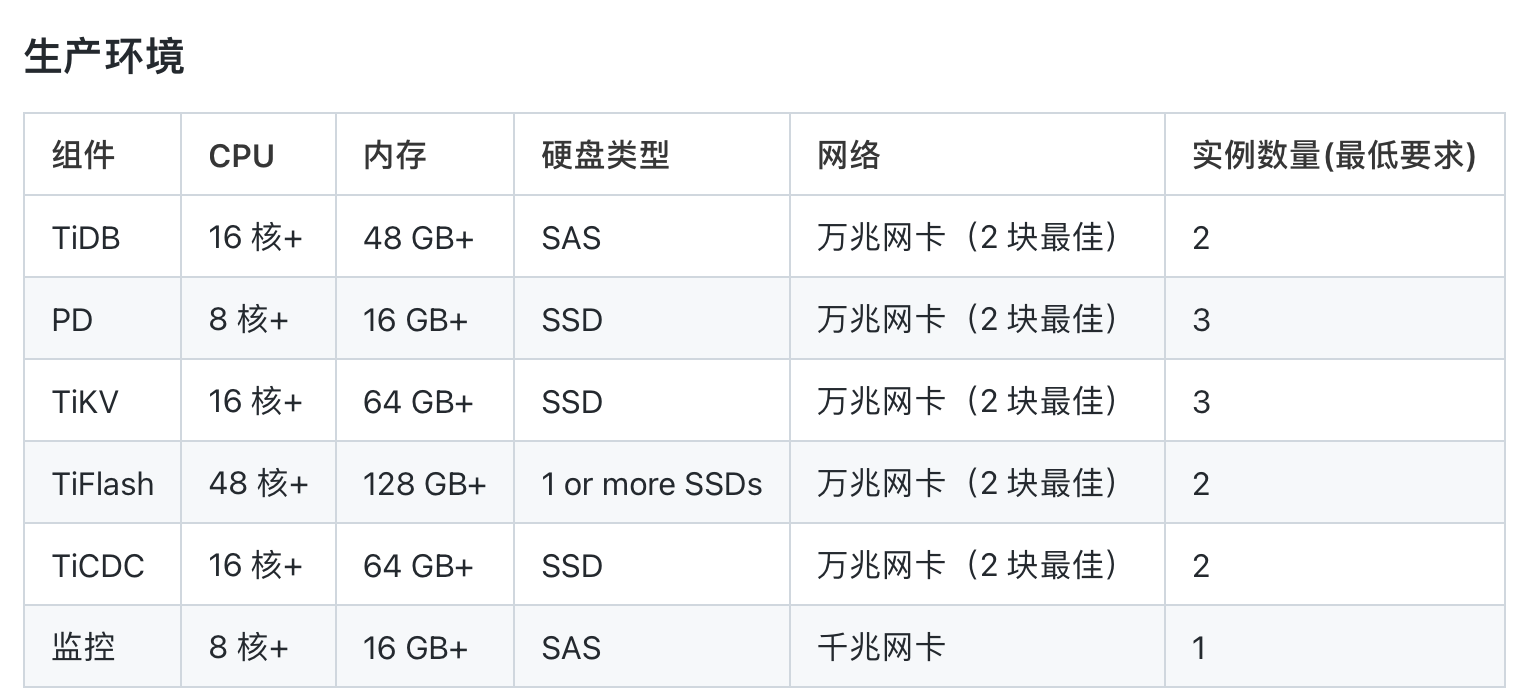
和群主沟通了 他机器cpu核心太少不满足最低要求 让他升级硬件
gary
(feng)
18
1 个赞
hyman
21
已解决,全量数据有点问题,单sql文件存在超50G的文件,可能传输过程中导致的,替换之后就好了