vcdog
2019 年8 月 28 日 06:29
1
环境:tidb集群版本为:v3.0.1
使用tidb官方工具:mydumper导出,loader导入工具,进行导入数据时,报错如下:
2019/08/28 16:45:19 status.go:32: [info] [loader] finished_bytes = 3126016720, total_bytes = GetAllRestoringFiles3366163253, progress = 92.87 %Error 9001: PD server timeout
使用pd-ctl工具命令行,查看pd状态正常:http://192.168.3.16:24801 http://192.168.3.16:24791
######### Get the information of pd member . #########http://192.168.3.16:24801 http://192.168.3.16:24791 http://192.168.3.16:24801 http://192.168.3.16:24791 http://192.168.3.16:24801 http://192.168.3.16:24791 http://192.168.3.18:24801 http://192.168.3.18:24791 http://192.168.3.19:24801 http://192.168.3.19:24791
查询store存储就卡住一直不能返回结果:
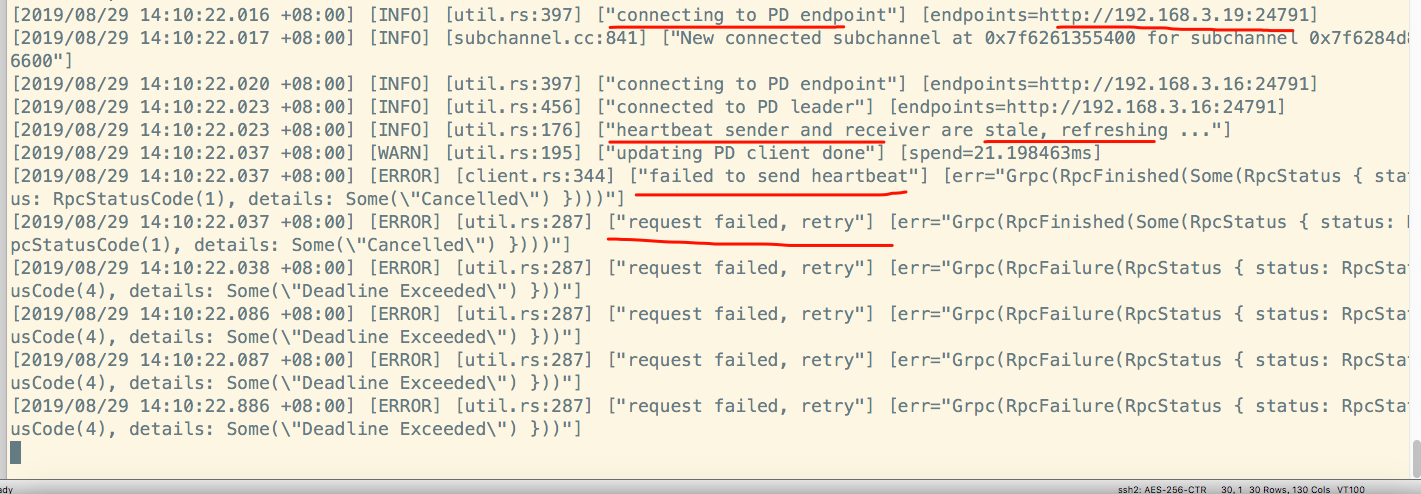
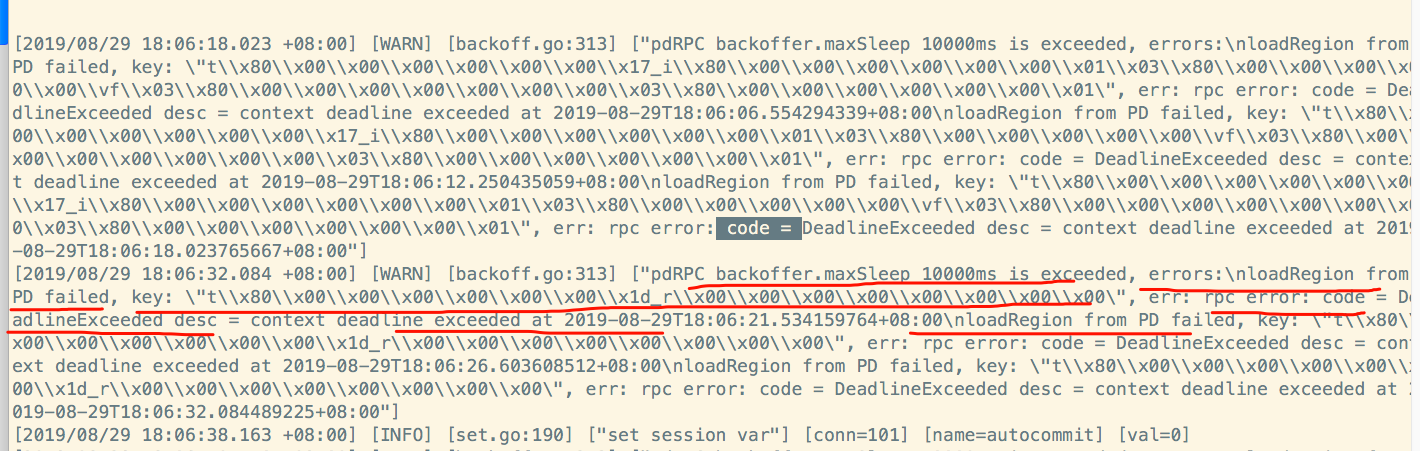
从日志报错来看,是kv和pd之间发送心跳包通讯,请求失败。但是,从kv服务器上telnet 192.168.3.16 24791服务端口是通的。
3.16上pd leader的日志有如下报错:
1 个赞
qizheng
2019 年8 月 28 日 08:53
2
检查下 TiKV 日志有没有报错,从报错看可能有些 region 的 leader 节点有异常
vcdog
2019 年8 月 29 日 07:03
3
prometheus监控显示,服务正常,但是,日志中有报错。
vcdog
2019 年8 月 29 日 10:23
5
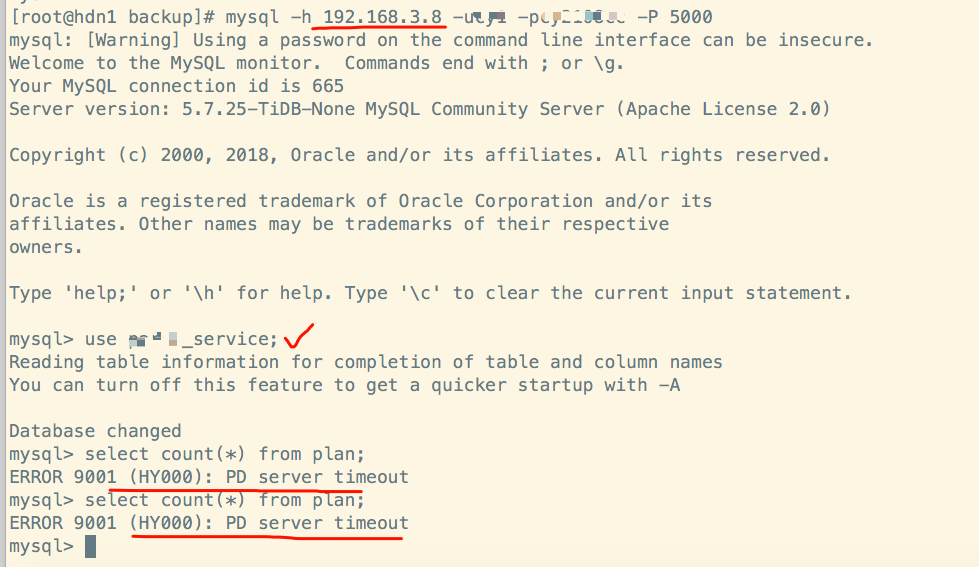
从内网的一台机器3.172服务器上,进行连接192.168.3.8的tidb发起连接,并进行查询:
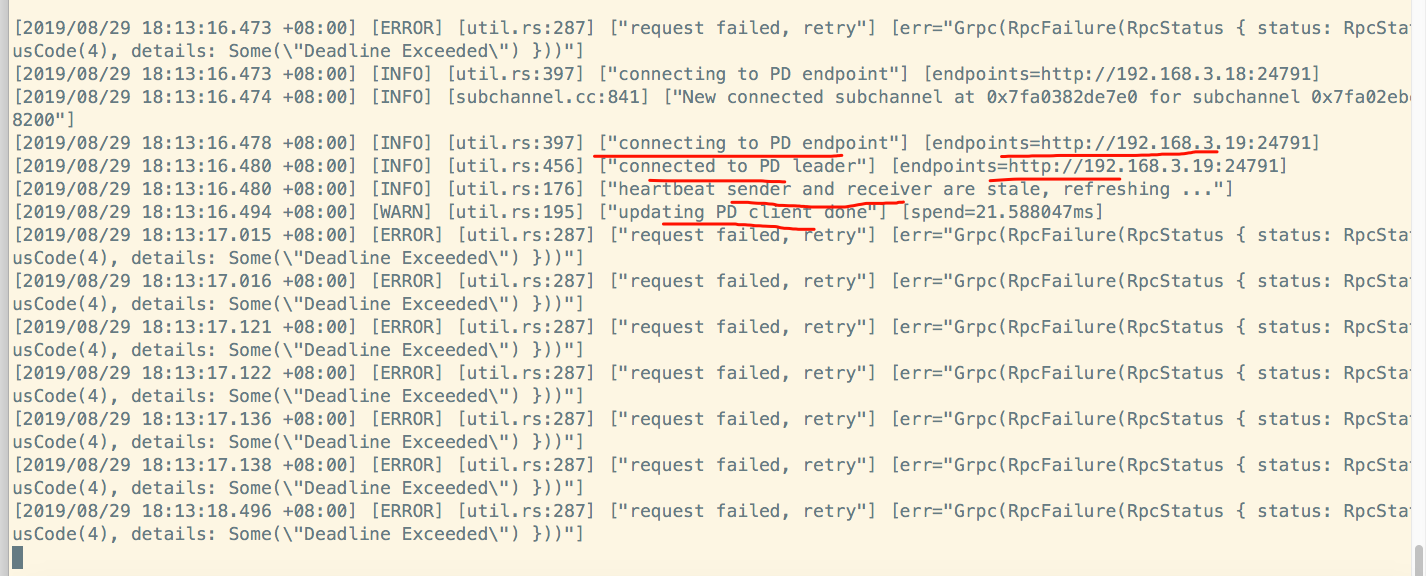
此时,192.168.3.8的tidb实例的报错日志:
显示请求errors:
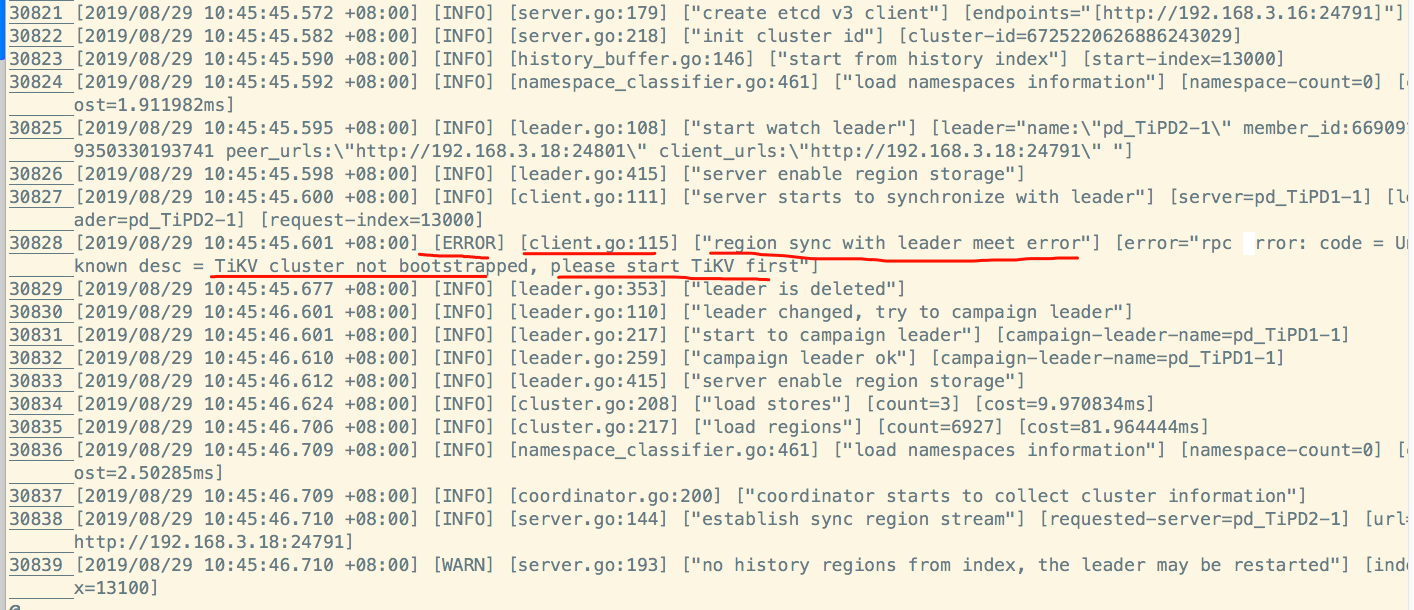
新的pd leader上的日志如下:
3个kv节点的日志报错:
从以上日志来看,象是pd和kv之间的网络心跳不通。
但是,无论是从3个kv节点上去telnet3个pd的ip和端口,还是,从pd上telnet3个kv的ip和端口都是通的。
rleungx
2019 年8 月 29 日 11:50
6
能提供一下 PD 的版本信息吗?另外如果有现场的话,可否抓个 goroutine?
vcdog
2019 年8 月 30 日 01:29
7
./pd-server -V
Release Version: v4.0.0-alpha-26-g96e25880
Git Commit Hash: 96e258805daee08029f6e5ba885c8861e33d9d73
Git Branch: master
UTC Build Time: 2019-08-12 08:53:05
goroutine包,怎么抓取,请指教,谢谢!
rleungx
2019 年8 月 30 日 02:13
8
看样子 PD 用的是 master 分支,可以把 PD 更新到最新的 master 版本吗?PD master 分支分别在 8.15 和 8.26 修复了两个会导致死锁的问题,对应的 PR 分别是 Sign in to GitHub · GitHub
vcdog
2019 年8 月 30 日 02:19
9
我是直接用的tidb-ansible-3.0.1的整个部署套件版本。
整个集群跑了一晚上后,tikv集群自动修复,以下日志为从其中的1个kv节点取得:
2338028 [2019/08/30 04:07:18.820 +08:00] [ERROR] [util.rs:287] [“request failed, retry”] [err=“Grpc(RpcFailure(RpcStatus { status: RpcStatusCode(4), details: Some(“Deadline Exceeded”) }))”]
2338029 [2019/08/30 04:07:18.820 +08:00] [ERROR] [client.rs:344] [“failed to send heartbeat”] [err=“Grpc(RpcFinished(Some(RpcStatu s { status: RpcStatusCode(14), details: Some(“keepalive watchdog timeout”) })))”]
2338030 [2019/08/30 04:07:18.820 +08:00] [ERROR] [util.rs:287] [“request failed, retry”] [err=“Grpc(RpcFinished(Some(RpcStatus { s tatus: RpcStatusCode(14), details: Some(“keepalive watchdog timeout”) })))”]
2338031 [2019/08/30 04:07:19.750 +08:00] [ERROR] [gc_worker.rs:786] [“failed to get safe point from pd”] [err=“Other(”[src/storag e/gc_worker.rs:66]: failed to get safe point from PD: Grpc(RpcFailure(RpcStatus { status: RpcStatusCode(4), details: Some( “Deadline Exceeded”) }))")"]
2338032 [2019/08/30 04:09:18.138 +08:00] [INFO] [raft.rs:2013] ["[term 18] received MsgTimeoutNow from 50082 and starts an electio n to get leadership."] [tag="[region 50081] 50083"] [from=50082] [term=18] [id=50083]
2338033 [2019/08/30 04:09:18.138 +08:00] [INFO] [raft.rs:1294] [“starting a new election”] [term=18] [tag="[region 50081] 50083"] [id=50083]
2338034 [2019/08/30 04:09:18.138 +08:00] [INFO] [raft.rs:886] [“became candidate at term 19”] [tag="[region 50081] 50083"] [term=1 9] [id=50083]
2338035 [2019/08/30 04:09:18.138 +08:00] [INFO] [raft.rs:1006] [“50083 received message from 50083”] [term=19] [msg=MsgRequestVote ] [from=50083] [id=50083] [id=50083]
2338036 [2019/08/30 04:09:18.138 +08:00] [INFO] [raft.rs:1032] ["[logterm: 18, index: 18] sent request to 50084"] [msg=MsgRequestV ote] [tag="[region 50081] 50083"] [term=19] [id=50084] [log_index=18] [log_term=18] [id=50083]
2338037 [2019/08/30 04:09:18.138 +08:00] [INFO] [raft.rs:1032] ["[logterm: 18, index: 18] sent request to 50082"] [msg=MsgRequestV ote] [tag="[region 50081] 50083"] [term=19] [id=50082] [log_index=18] [log_term=18] [id=50083]
vcdog
2019 年8 月 30 日 02:31
10
tikv集群在遇到批量导入数据时,打散到kv的region数据通过raft一致性处理,没有达到最终一致后,会进入一种safe安全保护模式吗?从昨天的现象来看,是tikv和pd之间一直在尝试连接,却又连接失败
liubo
2019 年8 月 30 日 03:04
11
是不是替换过 tidb-ansible 里面的 binary,完全用 ansible 部署的话,不会串版本的
vcdog
2019 年8 月 30 日 05:45
12
没有替换过,都是用的ansible工具下载的,各个组件如下:
vcdog
2019 年8 月 30 日 07:23
13
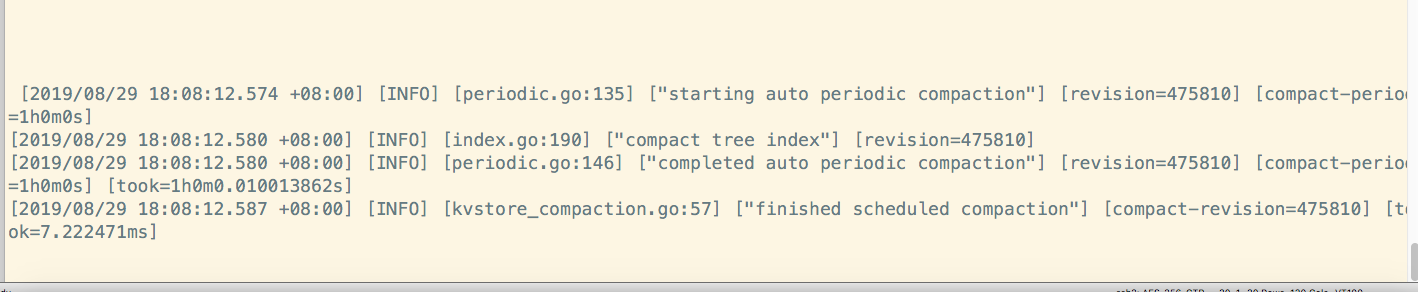
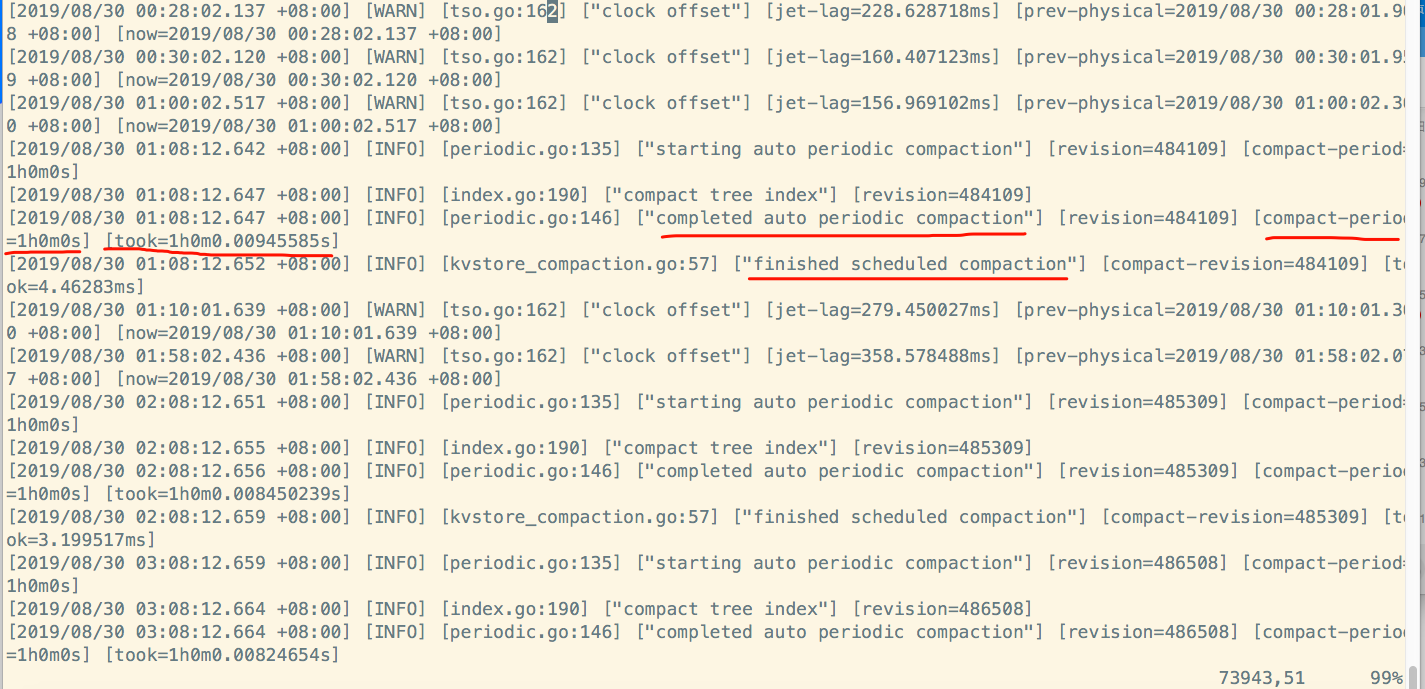
经过查看3.19的pd的日志信息,发现在凌晨1点08分,2点08分,3点08分,数据均进行完成1次自动定期压缩,但是,消耗的时间有点长,长达1小时之久。
pd日志显示,在凌晨4点09分的时候,进行了自动重启,然后,就ok了。
vcdog
2019 年9 月 5 日 03:11
15
这个问题的根本原因,是tidb,tipd,tikv3者的版本不统一兼容的问题。后来,从官网下载3.0.1版本,重新部署,导入批量数据后,没有再产生pd server timeout的问题。
1 个赞
system
2022 年10 月 31 日 19:17
16
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。